

Tree BFS 탐색 순서
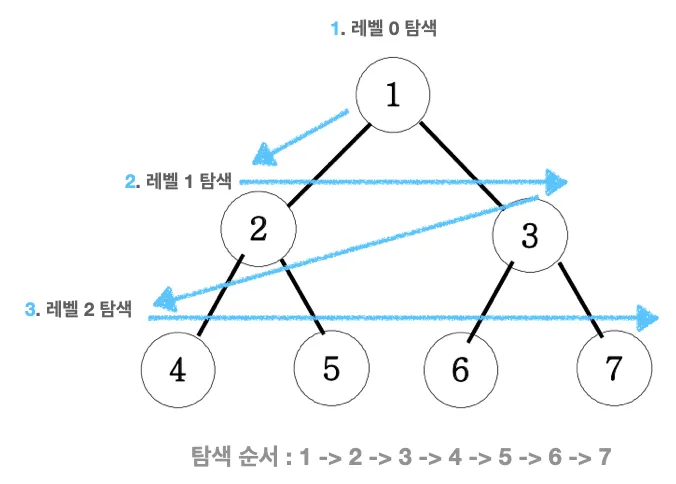
기본 개념
•
BFS는 레벨 단위로 탐색을 한다
•
한 번 만에 갈 수 있는 길을 모두 탐색한 후, 두 번 만에 갈 수 있는 모든 길을 탐색하는 방식이다
탐색 순서: 1 → 2 → 3 → 4 → 5 → 6 → 7
BFS의 특징
•
두 노드사이의 최단경로를 탐색할때 활용하기 좋은 방식이다. 멀리떨어진 노드는 나중에 탐색하는 방식이기 때문!
•
큐를 활용해서 탐색할 노드의 순서를 저장하고 큐에 저장된 순서대로 탐색한다. 선입선출의 방식을 활용해야 하기 때문에 큐를 활용한다.
BFS 구현 알고리즘
1.
루트노드에서 시작한다.
2.
루트노드와 인접하고 방문되지 않은 노드, 큐에 저장되지 않은 노드들을 Queue에 넣는다.
3.
Queue에서 dequeue(pop)하여 가장 먼저 큐에 저장한 노드를 방문한다.
배열을 큐처럼 활용한 트리 BFS 순회 방법
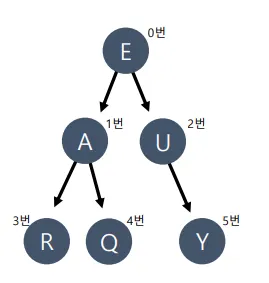
배열을 큐처럼 활용한 트리 BFS 순회 방법
핵심 아이디어
•
배열을 Queue처럼 사용: head와 tail 포인터로 큐 동작 구현
•
head: 다음에 꺼낼 위치 (dequeue)
•
tail: 다음에 넣을 위치 (enqueue)
•
종료 조건: head == tail이 되면 큐가 비어있음
직접 Queue 구현
#include <iostream>
#include <queue>
int map[6][6] =
{
{0, 1, 1, 0, 0, 0},
{0, 0, 0, 1, 1, 0},
{0, 0, 0, 0, 0, 1},
{0, 0, 0, 0, 0, 0},
{0, 0, 0, 0, 0, 0},
{0, 0, 0, 0, 0, 0}
};
char value[6] = { 'E', 'A', 'U', 'R', 'Q', 'Y' };
struct Node
{
int num; // 노드 번호
int level; // 깊이 레벨
};
Node queue[7] = { {0,0} }; // 큐 역할을 할 배열, 시작 노드 {0,0} 미리 삽입
int head = 0; // 큐에서 꺼낼 위치
int tail = 1; // 큐에 넣을 위치 (시작노드가 이미 있으므로 1)
int main()
{
while (head != tail) // 큐가 비어있지 않은 동안
{
Node now = queue[head]; // 큐에서 노드 꺼내기 (dequeue)
std::cout << value[now.num] << std::endl; // 현재 노드 출력
std::cout << "-----------" << std::endl;
// 현재 노드와 연결된 모든 자식 노드들을 큐에 추가
for (int i = 0; i < 6; i++)
{
if (map[now.num][i] == 1) // 연결되어 있으면
{
queue[tail] = { i, now.level + 1 }; // 큐에 추가 (enqueue)
tail++; // tail 포인터 이동
}
}
head++; // head 포인터 이동 (방금 처리한 노드는 제거된 것과 같음)
}
return 0;
}
C++
복사
동작 과정:
1.
시작: queue[0] = {0,0}, head=0, tail=1
2.
E(0) 처리 → A(1), U(2)를 큐에 추가 → tail=3
3.
A(1) 처리 → R(3), Q(4)를 큐에 추가 → tail=5
4.
U(2) 처리 → Y(5)를 큐에 추가 → tail=6
5.
R(3), Q(4), Y(5) 순서대로 처리
bfs 트리 순회 std::Queue 라이브러리를 사용한 방법
표준 라이브러리의 장점
•
자동 메모리 관리: 크기 제한 없이 자동으로 확장
•
편리한 메소드: push(), pop(), front(), empty() 제공
•
안전성: 배열 경계 체크 불필요
표준 라이브러리 활용
#include <iostream>
#include <queue> // std::queue 사용을 위한 헤더
int map[6][6] =
{
{0, 1, 1, 0, 0, 0},
{0, 0, 0, 1, 1, 0},
{0, 0, 0, 0, 0, 1},
{0, 0, 0, 0, 0, 0},
{0, 0, 0, 0, 0, 0},
{0, 0, 0, 0, 0, 0}
};
char value[6] = { 'E', 'A', 'U', 'R', 'Q', 'Y' };
struct Node
{
int num; // 노드 번호
int level; // 깊이 레벨
};
std::queue<Node> queue = {}; // 표준 라이브러리 큐 선언
int main()
{
queue.push(Node{0, 0}); // 시작 노드를 큐에 추가
while (!queue.empty()) // 큐가 비어있지 않은 동안
{
Node now = queue.front(); // 큐의 맨 앞 원소 가져오기
std::cout << value[now.num] << std::endl; // 현재 노드 출력
std::cout << "-----------" << std::endl;
// 현재 노드와 연결된 모든 자식 노드들을 큐에 추가
for (int i = 0; i < 6; i++)
{
if (map[now.num][i] == 1) // 연결되어 있으면
{
queue.push(Node{ i, now.level + 1 }); // 큐에 추가
}
}
queue.pop(); // 처리 완료된 노드를 큐에서 제거
}
return 0;
}
C++
복사
직접 구현 vs 표준 라이브러리 비교:
•
직접 구현: head, tail 관리, 배열 크기 제한
•
표준 라이브러리: push(), pop(), front() 사용, 크기 제한 없음
•
성능: 거의 동일, 표준 라이브러리가 약간 더 안전
bfs 그래프 순회 방법
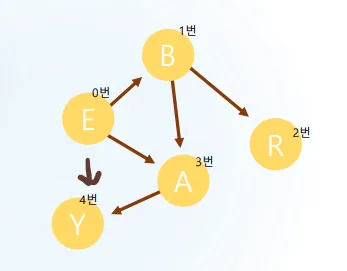
트리 vs 그래프의 핵심 차이점
•
트리: 사이클이 없어서 중복 방문 불가능
•
그래프: 사이클이 있어서 무한 루프 위험 → used[] 배열로 중복 방문 방지
used 배열 사용
#include <iostream>
#include <queue>
int map[5][5] =
{
{0, 1, 0, 1, 1}, // E는 B, A, Y와 연결
{0, 0, 1, 1, 0}, // B는 R, A와 연결
{0, 0, 0, 0, 0}, // R는 연결된 곳 없음 (끝점)
{0, 0, 0, 0, 1}, // A는 Y와 연결
{0, 0, 0, 0, 0}, // Y는 연결된 곳 없음 (끝점)
};
char value[6] = { 'E', 'B', 'R', 'A', 'Y'};
struct Node
{
int num; // 노드 번호
int level; // 깊이 레벨
};
std::queue<Node> queue = {};
int used[6] = {}; // 방문 체크 배열 (0: 미방문, 1: 방문완료)
int main()
{
queue.push(Node{0, 0}); // 시작 노드 E(0)를 큐에 추가
used[0] = 1; // 시작 노드를 방문 처리 ★중요★
while (!queue.empty())
{
Node now = queue.front(); // 현재 처리할 노드
std::cout << value[now.num] << std::endl; // 현재 노드 출력
std::cout << "-----------" << std::endl;
// 현재 노드와 연결된 모든 노드들 확인
for (int i = 0; i < 5; i++)
{
if (used[i] == 1) // 이미 방문한 노드면 건너뛰기
continue;
if (map[now.num][i] == 0) // 연결되지 않은 노드면 건너뛰기
continue;
used[i] = 1; // 방문 처리 ★중요★
queue.push(Node{ i, now.level + 1 }); // 큐에 추가
}
queue.pop(); // 현재 노드 처리 완료
}
return 0;
}
C++
복사
핵심 포인트:
1.
시작할 때: used[0] = 1로 시작점 방문 처리
2.
큐에 넣을 때: used[i] = 1로 미리 방문 처리 (중요!)
3.
두 번의 continue: 방문했거나 연결되지 않은 노드 건너뛰기
동작 과정:
1.
E(0) 처리 → B(1), A(3), Y(4) 발견하여 큐에 추가 및 방문 처리
2.
B(1) 처리 → R(2) 발견하여 큐에 추가 (A는 이미 방문 처리됨)
3.
A(3) 처리 → Y(4)는 이미 방문 처리되어 건너뜀
4.
Y(4), R(2) 순서대로 처리하며 종료
왜 큐에 넣을 때 바로 방문 처리?
•
큐에서 꺼낼 때 방문 처리하면, 같은 노드가 여러 번 큐에 들어갈 수 있음
•
미리 방문 처리하면 중복 추가 방지 가능
핵심 비교
구분 | DFS | BFS |
탐색 방식 | 깊이 우선 | 너비 우선 |
자료구조 | Stack (재귀) | Queue |
구현 | 재귀함수 | 반복문 + Queue |
메모리 | 적음 | 많음 |
경로 탐색 | 모든 경로 | 최단 경로 |
BFS 길찾기 맵 탐색
기본 개념
bfs 알고리즘은 단순 순회 외에도 길찾기 알고리즘으로 활용 하는 경우도 많다.
다만 여기에서는 당장 길찾기에 활용 하면 목적할 수 있게에 2차원 배열을 bfs를 이용해 순회하는 방법부터 연습해보도록 하자다. (다음 시간에 길찾기 bfs활용)
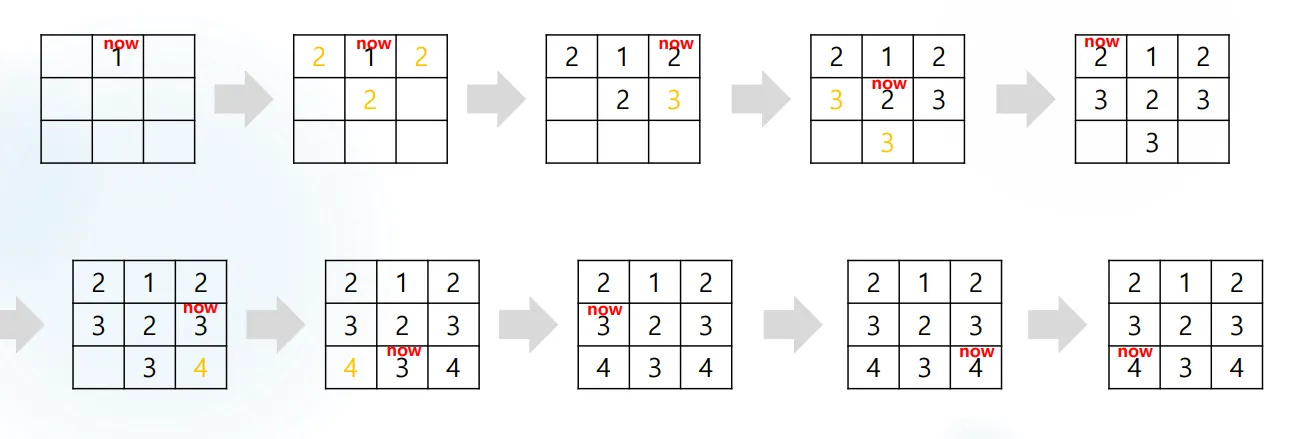
BFS 2차원 배열 길찾기 사전준비 ( 2차원배열 BFS로 순회하기 )
#include <iostream>
#include <queue>
int map[3][3] =
{
{0, 0, 0},
{0, 0, 0},
{0, 0, 0},
};
struct Node
{
int x;
int y;
int level;
};
std::queue<Node> queue = {};
int used[6] = {};
int direct[4][2] =
{
0, 1,
0, -1,
1, 0,
-1, 0,
};
int main()
{
queue.push(Node{1, 0, 1});
map[0][1] = 1;
while (!queue.empty())
{
Node now = queue.front();
if (now.y == 2 && now.x == 2)
{
std::cout << "도착" << std::endl;
}
for (size_t i = 0; i < 4; i++)
{
int dy = now.y + direct[i][0];
int dx = now.x + direct[i][1];
if (dy < 0 || dx < 0 || dy > 2 || dx > 2)
continue;
if (map[dy][dx] > 0)
continue;
Node next = Node{ dx, dy, now.level + 1 };
map[dy][dx] = next.level;
queue.push(next);
int a = 0;
}
queue.pop();
}
return 0;
}
C++
복사
“강의는 많은데, 왜 나는 아직도 코드를 못 짤까?”
혼자 공부하다 보면 누구나 이런 고민을 하게 됩니다.
•
강의는 다 들었지만 막상 손이 안 움직이고,
•
복습을 하려 해도 무엇을 다시 봐야 할지 모르겠고,
•
질문할 곳도 없고,
•
유튜브는 결국 정답을 따라 치는 것밖에 안 되는 것 같고.
문제는 ‘연습’이 빠졌기 때문입니다.
단순히 강의를 듣는 것만으로는 실력이 늘지 않습니다.
실제 문제를 풀고, 고민하고, 직접 구현해보는 시간이 반드시 필요합니다.
그래서, 얌얌코딩 코칭은 다릅니다.
그냥 가르치지 않습니다.
스스로 설계하고, 코딩할 수 있게 만듭니다.
얌얌코딩 코칭에서는 단순한 예제가 아닌,
스스로 문제를 분석하고 구현해야 하는 연습문제를 제공합니다.
이 연습문제들은 다음과 같은 역량을 키우기 위해 설계되어 있습니다:
•
문제를 스스로 쪼개고 설계하는 힘
•
다양한 조건을 만족시키는 실제 구현 능력
•
기능 단위가 아닌, 프로그램 단위로 사고하는 습관
•
마침내 자신의 힘으로 코드를 끝까지 작성하는 경험
지금 필요한 건 더 많은 강의가 아닙니다.
코드를 스스로 완성해 나가는 훈련,
그것이 지금 실력을 끌어올릴 가장 현실적인 방법입니다.
 자세한 안내 보기: 프리미엄 코칭 안내 바로가기 또는 카카오톡 상담방: 얌얌코딩 상담방
자세한 안내 보기: 프리미엄 코칭 안내 바로가기 또는 카카오톡 상담방: 얌얌코딩 상담방