

계수정렬 (Counting Sort) & 해시테이블 (Hash Table)
 계수정렬 (Counting Sort)
계수정렬 (Counting Sort)
핵심 개념
Counting sort는 정렬 알고리즘중 하나로, 키 값의 범위가 제한된 정수 일때 매우 효율적인 방법. 다른 비교기반 정렬 알고리즘과 달리, 비교를 하지 않고 숫자의 발생 횟수를 카운트하여 정렬을 수행한다.
시간 복잡도가 O(n+k)이다. 데이터크기와 데이터 값의 범위에 비례한다.
카운팅소트의 동작원리
1. 입력데이터와 범위를 미리 알아두어야 한다. 예를 들어 0에서 100사이의 정수만을 다룬다면, 해당범위에 맞춰 알고리즘 동작
2. 각 데이터가 몇번씩 등장했는지 기록하는 카운트 배열을 만든다.
3. 카운트 배열을 통해 해당 숫자보다 작은 숫자가 몇개 있는지 계산한다.
4. 원래 배열의 숫자를 하나씩 꺼내면서 정렬된 위치에 배치한다.
위치 지정: 누적합 4라는 것은 "이 숫자(1)와 이보다 작은 숫자들을 다 합쳐서 총 4개가 있다"는 뜻입니다. 즉, 이 숫자는 아무리 뒤로 밀려도 4번째 자리 안에는 들어와야 한다는 가이드라인이 됩니다
Stable Sort(안정 정렬) 유지: 원본 배열을 뒤에서부터 훑으면서 누적합 위치에 넣고 숫자를 하나씩 줄여나가면, 동일한 값들 사이의 상대적인 순서가 유지됩니다. 이는 정렬 알고리즘에서 매우 중요한 속성입니다.
예제: [5, 2, 2, 1, 2] 정렬
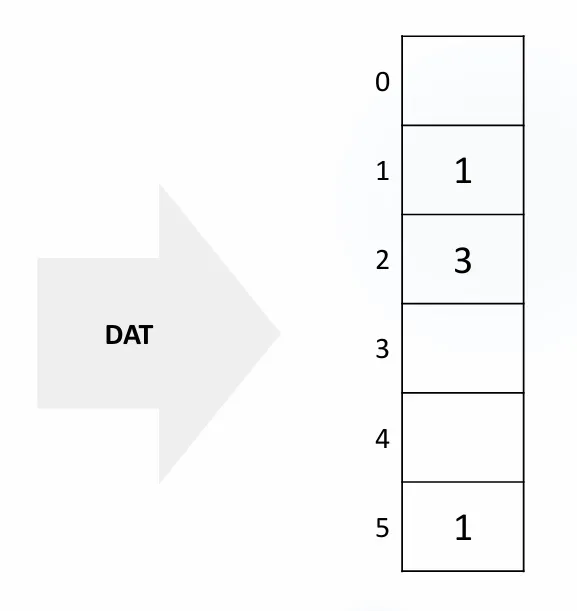
1단계: 정렬할 값들을 count 배열에 저장한다.
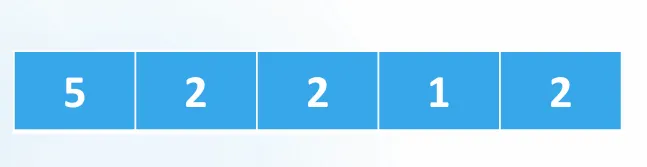
원본 배열: [5, 2, 2, 1, 2]
카운트 배열 구성:
숫자 | 0 | 1 | 2 | 3 | 4 | 5 |
개수 | 0 | 1 | 3 | 0 | 0 | 1 |
각 숫자의 등장 횟수를 센다:
- 1이 1번 등장
- 2가 3번 등장
- 5가 1번 등장
Plain Text
복사
2단계: 누적합을 구해준다.
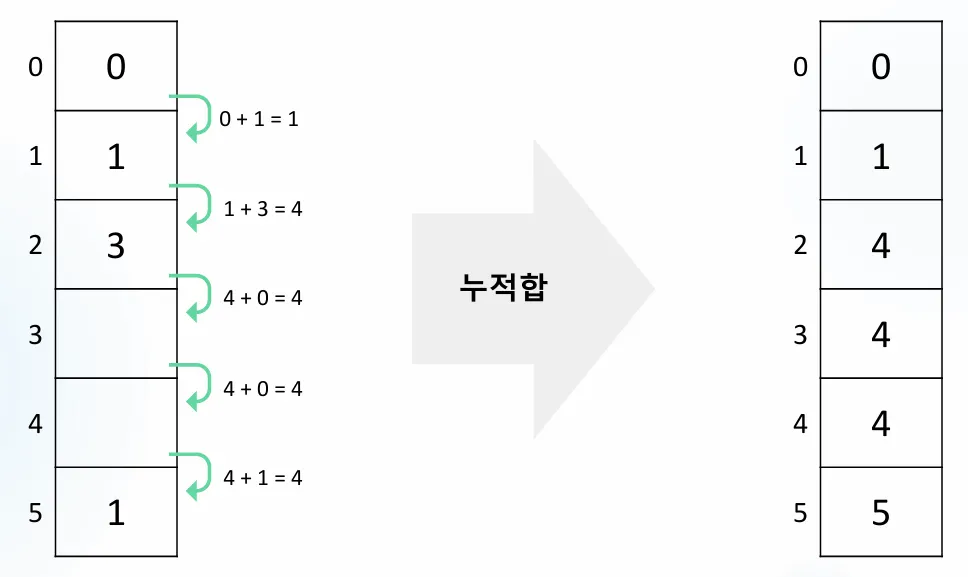
누적합 계산 과정:
index 0: 0
index 1: 0 + 1 = 1
index 2: 1 + 3 = 4
index 3: 4 + 0 = 4
index 4: 4 + 0 = 4
index 5: 4 + 1 = 5
결과 배열: [0, 1, 4, 4, 4, 5]
Plain Text
복사
누적합을 구하는 이유
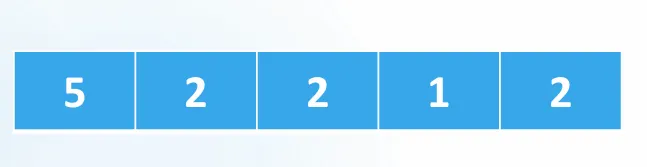
신기하게도 정렬할 값들이 result 배열에 들어 갈 수 있는 LastIndex가 결정된다.
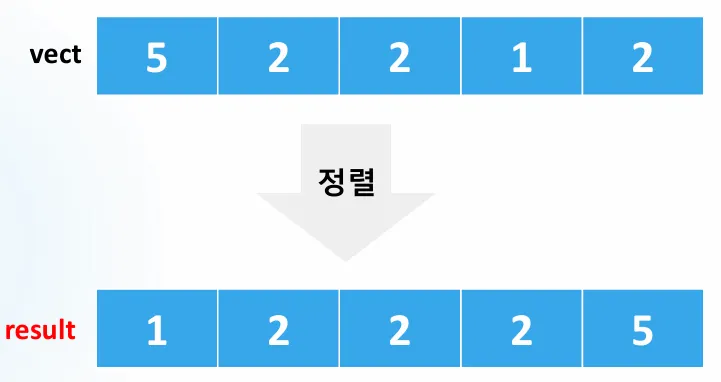
예시 분석:
- 숫자 5는 result[5-1]에 들어가면 된다.
- 숫자 2는 result[4-1]에 들어가면 된다.
- 숫자 1은 result[1-1]에 들어가면 된다.
(index에 -1을 해주면 result[0]부터 채울 수 있다.)
최종 결과: [1, 2, 2, 2, 5]
Plain Text
복사
3단계: 누적합을 이용하여 정렬 결과 저장
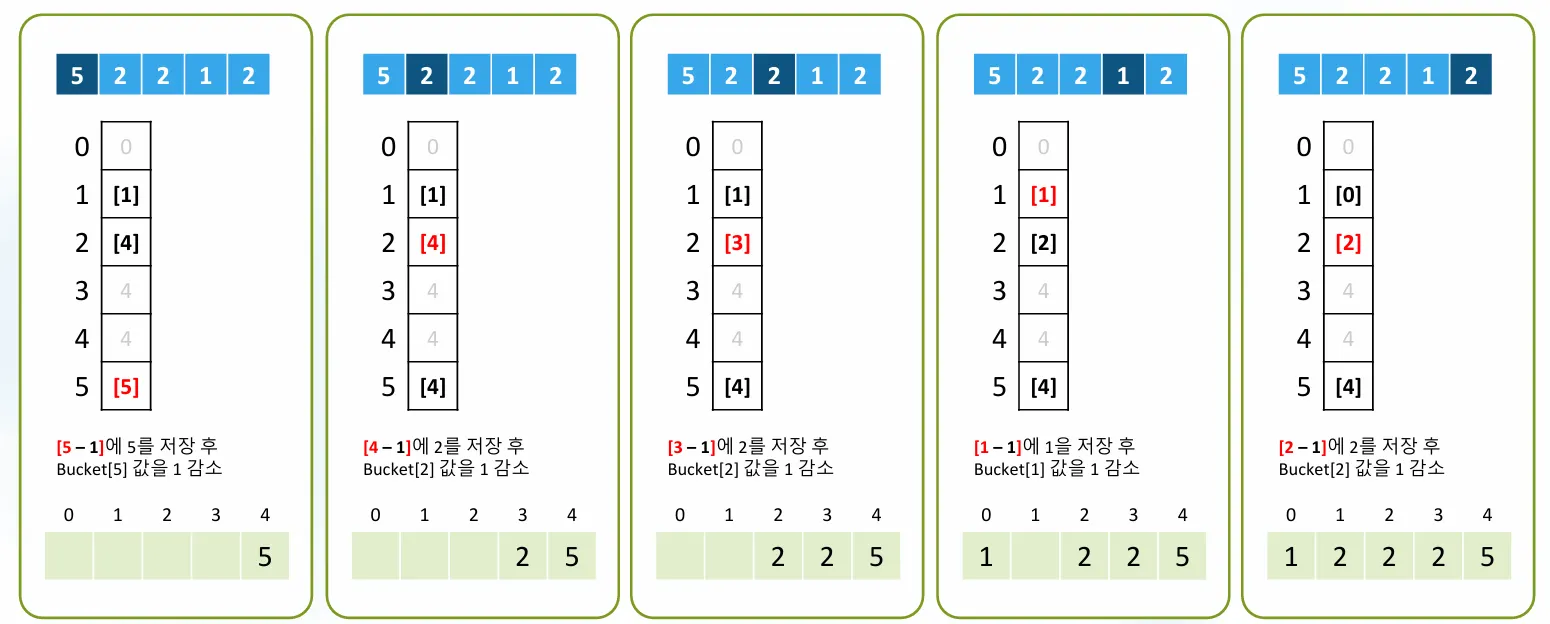
원본 배열을 뒤에서부터 처리하여 안정 정렬 보장:
3단계 과정 (5단계별 세부 처리):
1. 숫자 2 처리: count[2]=4 → result[3]=2, count[2]=3
2. 숫자 1 처리: count[1]=1 → result[0]=1, count[1]=0
3. 숫자 2 처리: count[2]=3 → result[2]=2, count[2]=2
4. 숫자 2 처리: count[2]=2 → result[1]=2, count[2]=1
5. 숫자 5 처리: count[5]=5 → result[4]=5, count[5]=4
정렬된 값을 하나씩 담색하면서, 제 위치에다가 값을 저장한다.
Plain Text
복사
계수정렬 완전 구현
#include <iostream>
#include <queue>
int main()
{
int arr[5] = { 5, 2, 2, 1, 2 };
int bucket[6] = { }; // 카운트 배열
int result[5] = { }; // 결과 배열
//1. bucket에 arr의 값을 넣어준다.
for (size_t i = 0; i < 5; i++)
{
bucket[arr[i]]++;
}
//2. bucket의 값을 누적시킨다.
for (size_t i = 1; i < 6; i++)
{
bucket[i] += bucket[i - 1];
}
//3. result에 bucket의 값을 넣어준다.
for (size_t i = 0; i < 5; i++)
{
int index = bucket[arr[i]] - 1;
result[index] = arr[i];
bucket[arr[i]]--; // 같은 값의 다음 위치를 위해 감소
}
// 결과 출력
std::cout << "정렬 결과: ";
for (int i = 0; i < 5; i++)
{
std::cout << result[i] << " ";
}
std::cout << std::endl;
return 0;
}
C++
복사
계수정렬의 특징
장점
1.
매우 빠른 속도: O(n+k) 시간복잡도
2.
안정 정렬: 같은 값의 상대적 순서 유지
3.
비교 없음: 값의 비교 연산 불필요
단점
1.
범위 제한: 정수만 가능, 범위가 클 수록 비효율
2.
추가 메모리: O(k) 공간 필요 (k = 값의 범위)
3.
범위 의존적: 값의 범위가 크면 사용 불가
사용 적합한 경우
•
정수 데이터
•
값의 범위가 작을 때 (보통 n과 비슷하거나 작을 때)
•
안정 정렬이 필요한 경우
•
최고 성능이 필요한 경우
해시테이블 (Hash Table) - unordered_map
핵심 개념
C++에서 제공하는 해시테이블 기반의 컨테이너입니다. 이 컨테이너는 키값과 데이터값 쌍으로 이루어져있다.
키를 기준으로 인덱스에 접근하기 때문에 데이터를 검색, 삽입할때 빠른속도로 사용 할 수 있다.
해시테이블의 특징
1. 해시 기반: 내부적으로 해시함수를 사용해서 키를 계산하기 때문에, 평균 시간 복잡도가 삽입, 삭제, 검색 전부 O(1)이다.
2. 키의 순서 보장이 되지 않는다: 삽입되는 순서가 유지되지 않는다. 내부적으로 해시테이블에 저장되기때 문에, 순서가 무작위이다.
3. 중복되는 키값을 허용 않는다: 각 키는 고유해야 하며, 중복된 값을 사용하면 그냥 덮어 씌어진다
4. 시간복잡도는 O(1)이다: 그치만 해시 충돌이 많이질 경우 O(n)까지도 늘어날수도 있다.
unordered_map 기본 사용법
#include <iostream>
#include <unordered_map>
int main()
{
std::unordered_map<std::string, int> age_map;
// 삽입
age_map["Alice"] = 25;
age_map.insert(std::make_pair("Bob", 30));
age_map["Bob"] = 30;
age_map["Charlie"] = 22;
// 값 접근
std::cout << "Alice's age: " << age_map["Alice"] << std::endl;
// 존재 여부 확인
if (age_map.find("Bob") != age_map.end())
{
std::cout << "Bob is in the map." << std::endl;
}
// 삭제
age_map.erase("Charlie");
// 전체 순회
for (const auto& pair : age_map)
{
std::cout << pair.first << ": " << pair.second << std::endl;
}
return 0;
}
C++
복사
주요 함수들
삽입 연산
// 방법 1: [] 연산자
map["key"] = value;
// 방법 2: insert 함수
map.insert(std::make_pair("key", value));
map.insert({"key", value}); // C++11 이후
C++
복사
조회 연산
// 방법 1: [] 연산자 (없으면 기본값으로 생성)
int value = map["key"];
// 방법 2: at() 함수 (없으면 예외 발생)
int value = map.at("key");
// 방법 3: find() 함수 (가장 안전)
auto it = map.find("key");
if (it != map.end())
{
int value = it->second;
}
C++
복사
삭제 연산
// 키로 삭제
map.erase("key");
// 반복자로 삭제
auto it = map.find("key");
if (it != map.end())
{
map.erase(it);
}
// 전체 삭제
map.clear();
C++
복사
기타 유용한 함수들
// 크기 확인
size_t size = map.size();
// 비어있는지 확인
bool empty = map.empty();
// 키 존재 여부 (C++20)
bool exists = map.contains("key");
// 개수 세기 (0 또는 1)
size_t count = map.count("key");
C++
복사
해시테이블 vs 다른 자료구조
구분 | unordered_map | map | vector |
평균 시간복잡도 | O(1) | O(log n) | O(n) |
최악 시간복잡도 | O(n) | O(log n) | O(n) |
순서 보장 | | (정렬됨) | (삽입순) |
메모리 사용 | 높음 | 보통 | 낮음 |
사용 적합성 | 빠른 검색 | 정렬된 데이터 | 순차 접근 |