

퀵정렬 (Quick Sort)
기본 개념
퀵정렬은 분할정복 전략을 사용하는 정렬 알고리즘으로, 실무에서 가장 많이 사용되는 정렬 방법입니다.
핵심 아이디어:
1.
배열에서 피벗(pivot)이라는 기준값을 선택합니다.
2.
피벗을 기준으로 배열을 두 부분으로 분할합니다:
•
왼쪽 부분: 피벗보다 작은 값들
•
오른쪽 부분: 피벗보다 큰 값들
3.
분할된 두 부분에 대해 재귀적으로 퀵정렬을 수행합니다.
4.
더 이상 쪼갤 수 없을 때까지 반복하면 정렬이 완료됩니다.

퀵정렬 (Quick Sort) 상세 구현
한 장 요약 그림 (분할정복 흐름)
graph TD A["배열"] --> B["pivot 선택"] B --> C["partition: pivot 기준으로 좌/우 분리"] C --> D["왼쪽 구간 quicksort"] C --> E["오른쪽 구간 quicksort"] D --> F["결과 병합(실제로는 제자리 정렬로 이어짐)"] E --> F
Mermaid
복사
퀵정렬 특징
•
평균 시간 복잡도: O(n log n)
•
최악 시간 복잡도: O(n²) (분할이 계속 한쪽으로 치우칠 때)
•
추가 공간: 평균 O(log n) (재귀 호출 스택)
•
제자리(in-place) 정렬: 보통 가능 (파티션 과정에서 swap만 수행)
•
안정 정렬(stable) 아님: 같은 값의 상대적 순서가 보장되지 않음
피벗(pivot)은 구현에 따라 첫 원소/끝 원소/중간값/무작위/median-of-3 등으로 선택할 수 있으며, 어떤 피벗 전략을 쓰느냐가 최악 케이스를 얼마나 줄이느냐에 큰 영향을 줍니다.
파티션(Partition)의 불변식(invariant)
파티션 과정은 결국 다음 조건을 만족하는 지점을 만들어내는 작업입니다.
•
피벗의 최종 위치 p를 기준으로
◦
왼쪽 구간: 모든 값 < pivot
◦
오른쪽 구간: 모든 값 > pivot (또는 >= pivot, 구현에 따라 달라짐)
이 불변식을 지키면서 포인터를 움직이고 swap을 수행하면, 피벗이 제자리를 찾고 나머지 구간은 독립적으로 다시 같은 문제(정렬)로 쪼개집니다.
퀵정렬 핵심 아이디어
1. 피벗(Pivot) 선택
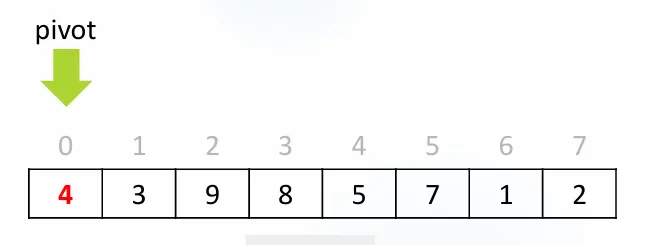
배열: [4, 3, 9, 8, 5, 7, 1, 2]
↑
pivot
특정 범위의 가장 왼쪽 원소를 피벗으로 선택
Plain Text
복사
2. 분할(Partition) 과정
파티션은 "피벗을 기준으로 작은 값은 왼쪽, 큰 값은 오른쪽"이 되도록 만드는 단계입니다.
•
swap을 여러 번 수행하면서 원소들을 양쪽으로 보내고
•
마지막에 피벗이 들어갈 최종 위치를 확정합니다.
주의: 같은 값(= pivot) 처리는 구현마다 다릅니다.
•
어떤 구현은 <= pivot을 왼쪽으로 보내고, 어떤 구현은 < pivot만 왼쪽으로 보냅니다.
•
이 선택이 "중복 값이 많을 때" 성능과 분할 균형에 영향을 줄 수 있습니다.
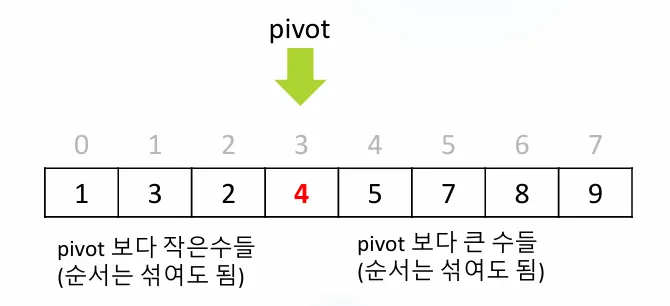
목표: pivot(4)를 기준으로 분할
- 왼쪽: 4보다 작은 수들 (순서는 섞여도 됨)
- 오른쪽: 4보다 큰 수들 (순서는 섞여도 됨)
Plain Text
복사
분할 과정 상세 분석
이번에는 구간을 나누어서 같은 작업을 진행하면 된다.
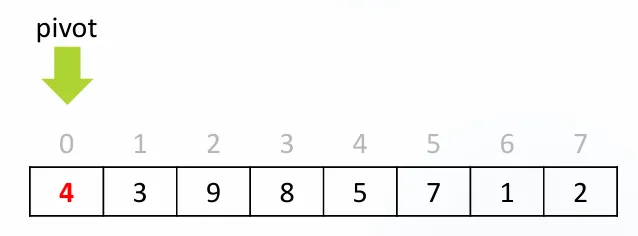
초기 상태:
[4, 3, 9, 8, 5, 7, 1, 2]
Plain Text
복사
가장 작은 구간이 될때까지 재귀호출을 통해서 반복하여 위치를 실행해준다.
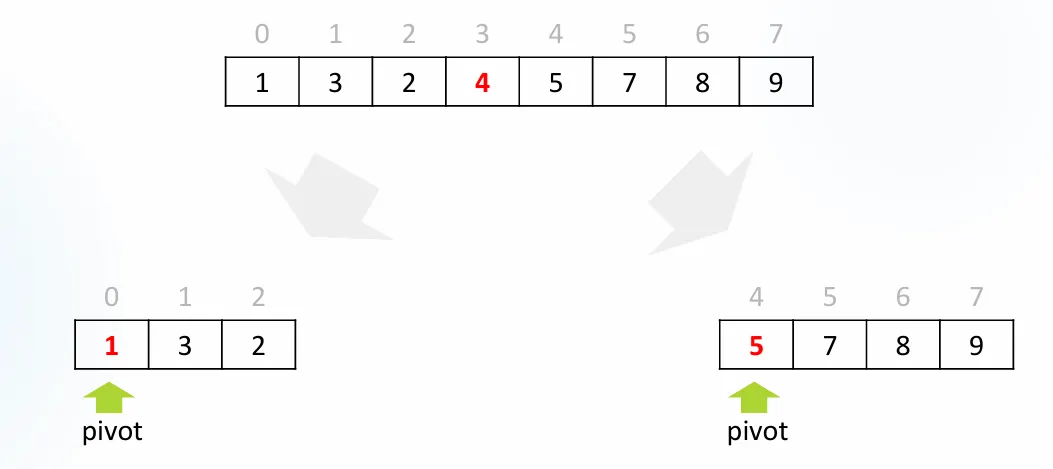
1단계: 두 부분으로 분할
원본: [1, 3, 2, 4, 5, 7, 8, 9]
←----- pivot보다 작은수들 pivot pivot보다 큰 수들 ----→
(순서는 섞여도 됨) (순서는 섞여도 됨)
Plain Text
복사
2단계: 각 부분을 재귀적으로 정렬
왼쪽 부분: [1, 3, 2] → pivot으로 다시 분할
오른쪽 부분: [5, 7, 8, 9] → pivot으로 다시 분할
Plain Text
복사
세부과정: 투 포인터 분할 알고리즘
포인터 a를 start + 1, 포인터 b를 end로 설정한다.
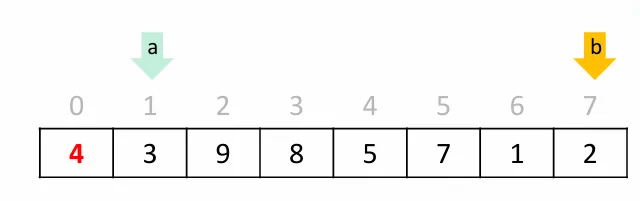
a++ 하면서 pivot보다 큰숫자를 찾는다. b-- 하면서 pivot보다 작은숫자를 찾는다.
1단계: a는 오른쪽으로, b는 왼쪽으로 이동
[4, 3, 9, 8, 5, 7, 1, 2]
↑ ↑
a(9>4 발견) b(2<4 발견)
Plain Text
복사
찾았으면 swap하여 바꿔주고, 이과정을 a와 b가 엇갈리기 전까지 반복해준다.
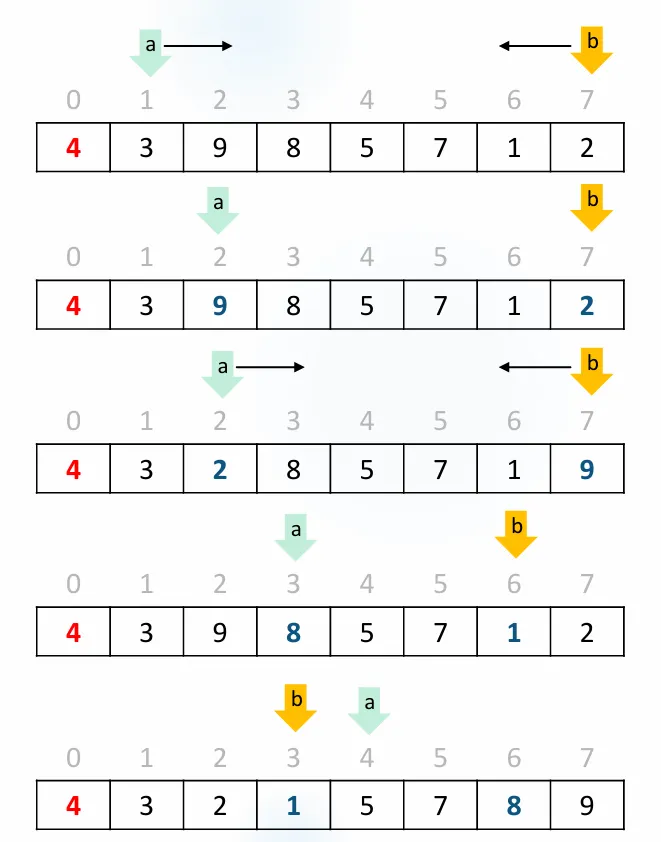
2단계: 9와 2를 교환
[4, 3, 2, 8, 5, 7, 1, 9]
↑ ↑
a b
3단계: 계속 진행
[4, 3, 2, 1, 5, 7, 8, 9]
↑ ↑
b a (엇갈림!)
Plain Text
복사
엇갈렸으면 마무리 단계로 pivot과 b를 swap하면 된다.
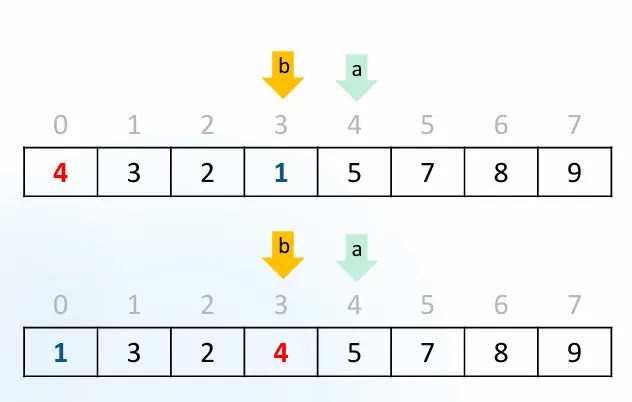
최종: pivot(4)과 b위치(1) 교환
[1, 3, 2, 4, 5, 7, 8, 9]
↑
pivot 최종 위치
Plain Text
복사
정리하면, 피벗의 최종 위치를 기준으로
•
왼쪽에는 피벗보다 작은 값(또는 작거나 같은 값)
•
오른쪽에는 피벗보다 큰 값(또는 큰거나 같은 값)
이 오도록 재배치가 끝납니다. 이제 남은 것은 왼쪽/오른쪽 구간을 "서로 독립적으로" 다시 정렬하는 것입니다.
투 포인터 방식 구현
#include <iostream>
int vect[10] = { 4,3,9,8,5,7,1,2 };
int n = 8;
void quicksort(int start, int end)
{
if (start >= end)
return;
int pivot = start; // 첫 번째 원소를 피벗으로
int a = start + 1; // 왼쪽에서 시작
int b = end; // 오른쪽에서 시작
while (true)
{
// a: pivot보다 큰 원소를 찾을 때까지 오른쪽으로 이동
while (a <= end && vect[a] <= vect[pivot])
a++;
// b: pivot보다 작은 원소를 찾을 때까지 왼쪽으로 이동
while (b >= start && vect[b] > vect[pivot])
b--;
// a와 b가 엇갈렸으면 종료
if (a > b)
break;
// 찾은 원소들을 교환
std::swap(vect[a], vect[b]);
}
// pivot을 올바른 위치(b)로 이동
std::swap(vect[pivot], vect[b]);
// 재귀 호출로 좌우 부분 정렬
quicksort(start, b - 1); // 왼쪽 부분
quicksort(b + 1, end); // 오른쪽 부분
}
int main()
{
quicksort(0, n - 1);
// 결과 출력
for (int i = 0; i < n; i++) {
std::cout << vect[i] << " ";
}
return 0;
}
C++
복사
퀵정렬 동작 과정 시뮬레이션
초기 배열: [4, 3, 9, 8, 5, 7, 1, 2]
1차 분할 후: [1, 3, 2, 4, 5, 7, 8, 9]
←--left--→ ↑ ←--right--→
pivot(4)
2차 분할:
왼쪽 [1, 3, 2]: pivot=1 → [1, 2, 3]
오른쪽 [5, 7, 8, 9]: 이미 정렬됨
3차 분할:
[2, 3]: pivot=2 → [2, 3]
최종 결과: [1, 2, 3, 4, 5, 7, 8, 9]
Plain Text
복사
퀵정렬의 한계와 해결책
최악의 경우 O(n²)
이미 정렬된 배열: [1, 2, 3, 4, 5]
첫 번째 원소를 피벗으로 선택하면:
- 왼쪽: [] (빈 배열)
- 오른쪽: [2, 3, 4, 5] (거의 모든 원소)
이런 불균형 분할이 계속되면 O(n²)
Plain Text
복사
해결책들
1.
랜덤 피벗: 무작위로 피벗 선택
2.
중간값 피벗: 첫째, 중간, 마지막 중 중간값 선택
3.
Median-of-3: 세 값의 중간값을 피벗으로
4.
Intro Sort: 재귀 깊이가 깊어지면 힙정렬로 전환
최적화된 퀵정렬
void optimizedQuickSort(int arr[], int low, int high) {
if (low < high) {
// 작은 배열은 삽입정렬 사용
if (high - low < 10) {
insertionSort(arr, low, high);
return;
}
// Median-of-3 피벗 선택
int mid = (low + high) / 2;
if (arr[mid] < arr[low]) swap(arr[mid], arr[low]);
if (arr[high] < arr[low]) swap(arr[high], arr[low]);
if (arr[high] < arr[mid]) swap(arr[high], arr[mid]);
int pi = partition(arr, low, high);
optimizedQuickSort(arr, low, pi - 1);
optimizedQuickSort(arr, pi + 1, high);
}
}
C++
복사
핵심 포인트 정리
분할(Partition)의 핵심
1.
피벗 선택: 보통 첫 번째, 마지막, 또는 중간 원소
2.
투 포인터: 양쪽에서 접근하여 교환할 원소 찾기
3.
교환: 조건에 맞는 원소들 위치 바꾸기
4.
피벗 배치: 최종적으로 피벗을 올바른 위치에 배치
재귀 호출
•
분할 완료 후: 피벗 기준으로 좌우 부분을 독립적으로 정렬
•
기저 조건: start >= end일 때 재귀 종료
•
점점 작은 문제: 전체 → 부분 → 더 작은 부분
시간복잡도
•
평균: O(nlogn) - 균등 분할
•
최악: O(n²) - 불균등 분할
•
공간: O(logn) - 재귀 스택
퀵정렬은 실제로 가장 많이 사용되는 정렬 알고리즘 중 하나입니다!
“강의는 많은데, 왜 나는 아직도 코드를 못 짤까?”
혼자 공부하다 보면 누구나 이런 고민을 하게 됩니다.
•
강의는 다 들었지만 막상 손이 안 움직이고,
•
복습을 하려 해도 무엇을 다시 봐야 할지 모르겠고,
•
질문할 곳도 없고,
•
유튜브는 결국 정답을 따라 치는 것밖에 안 되는 것 같고.
문제는 ‘연습’이 빠졌기 때문입니다.
단순히 강의를 듣는 것만으로는 실력이 늘지 않습니다.
실제 문제를 풀고, 고민하고, 직접 구현해보는 시간이 반드시 필요합니다.
그래서, 얌얌코딩 코칭은 다릅니다.
그냥 가르치지 않습니다.
스스로 설계하고, 코딩할 수 있게 만듭니다.
얌얌코딩 코칭에서는 단순한 예제가 아닌,
스스로 문제를 분석하고 구현해야 하는 연습문제를 제공합니다.
이 연습문제들은 다음과 같은 역량을 키우기 위해 설계되어 있습니다:
•
문제를 스스로 쪼개고 설계하는 힘
•
다양한 조건을 만족시키는 실제 구현 능력
•
기능 단위가 아닌, 프로그램 단위로 사고하는 습관
•
마침내 자신의 힘으로 코드를 끝까지 작성하는 경험
지금 필요한 건 더 많은 강의가 아닙니다.
코드를 스스로 완성해 나가는 훈련,
그것이 지금 실력을 끌어올릴 가장 현실적인 방법입니다.
자세한 안내 보기: 프리미엄 코칭 안내 바로가기
카카오톡 상담방: 얌얌코딩 상담방