


학습 목표
•
CNN과 VGG를 활용하여 CIFAR-10 이미지 분류 모델을 구현한다.
학습 순서
1.
이해하기: CNN 구조 이해
2.
데이터 전처리: 증강 및 정규화
3.
CNN으로 이미지 분류하기: 기본 CNN 모델 구성 및 학습
4.
전이 학습(VGG): 사전 학습된 모델 활용
세부 단계
•
데이터 증강
•
이미지 정규화
•
모델 정의
•
사전 학습된 모델 불러오기
•
학습 루프 정의
•
모델 학습
•
모델 성능 평가
핵심 용어 요약
1.
합성곱(Convolution) – 필터를 사용하여 이미지 특징을 추출하는 연산
2.
CNN – 합성곱층을 반복적으로 쌓아 구성한 신경망
3.
특징 맵(Feature Map) – 합성곱 연산의 결과로 생성된 이미지
4.
데이터 증강(Data Augmentation) – 회전, 자르기 등을 통해 데이터를 다양하게 만드는 기법
5.
데이터 전처리(Data Preprocessing) – 학습 전 데이터를 수정하고 준비하는 과정
6.
이미지 정규화(Normalization) – 채널별 픽셀 값의 분포를 균일하게 조정하는 기법
7.
패딩(Padding) – 이미지 외곽을 0으로 채워 크기를 유지하는 기법
8.
크롭핑(Cropping) – 이미지의 일부를 잘라내는 기법
9.
최대 풀링(Max Pooling) – 커널 내 최댓값을 선택하여 특징 맵 크기를 축소하는 연산
10.
전이 학습(Transfer Learning) – 사전 학습된 모델의 파라미터를 활용하는 학습 방법
CNNconvolutional neural network은 합성곱을 사용하는 신경망입니다. 합성곱 신경망, 콘볼루션 신경망 이라고도 부릅니다. 이미지에 특징이 하나만이 있는 게 아니기 때문에 CNN의 한 층에 필터를 여 러 개 준비합니다. 그래서 셀로판지 필터와 달리 CNN 필터는 여러 색과 모양을 제거할 수 있습 니다. 과거에는 CNN 필터를 사람이 직접 설계했지만 최근에는 인공 신경망을 이용해 만듭니다. CNN를 한마디로 요약하자면 인공 신경망을 이용해 합성곱 필터를 학습하는 신경망입니다.

입력은 1 원본 이미지입니다. 2 합성곱 커널이 CNN에서 특징 추출의 주역으로 학습에 필요한 가중치를 갖고 있습니다. 책을 읽듯이 원본 이미지의 왼쪽 위부터 오른쪽으로 한 칸씩 커널을 옮 기고, 오른쪽 끝에 다다르면 한 칸 내려 다시 커널을 제일 왼쪽으로 옮겨줍니다. 원본 이미지와 커 널의 각각 위치를(여기서는 ○와 △) 곱해주고, 곱한 결과인 9개 숫자를 다 더해 값(여기서는 ☆) 을 출력합니다. 앞의 그림에서는 원본 이미지가 4×4, 커널이 3×3이므로 다음 그림과 같이 총 4 회 픽셀끼리의 곱셈 계산을 합니다.
CNN이 왜 중요할까? 고해상도 이미지(예: 4K UHD)는 약 840만 개의 픽셀로 구성됩니다. 일반 신경망으로 이를 처리하면 각 층마다 매우 많은 가중치가 필요해 연산량이 기하급수적으로 증가합니다. 이러한 문제를 해결하기 위해 합성곱(convolution) 연산이 도입되었습니다. 합성곱은 작은 크기의 필터를 이용해 이미지의 중요한 특징을 효율적으로 추출하는 기법입니다.
이해를 돕기 위한 비유: 색깔이 있는 투명 필름을 통해 특정 색상의 글자만 걸러내듯이, CNN은 이미지에서 중요한 패턴과 특징만을 선택적으로 추출합니다. 불필요한 정보는 제거하고 분류에 필요한 핵심 특징만 남기는 것입니다.
특징 맵 ( feature map ) 합성 곱 의 결과 로부터 얻어지는 이미지 . 합성 곱 으로부터 얻어진 특징 이 그려진 이미지 라서 특징 맵 이라고 불 립니다 .
스트라이드 ( stride ) 커널 의 이동 거리
CNN은 이러한 방식으로 이미지 판별에 유용한 특징을 자동으로 학습합니다. 여기서 특징 추출에 사용되는 작은 필터를 커널(kernel)이라고 합니다.

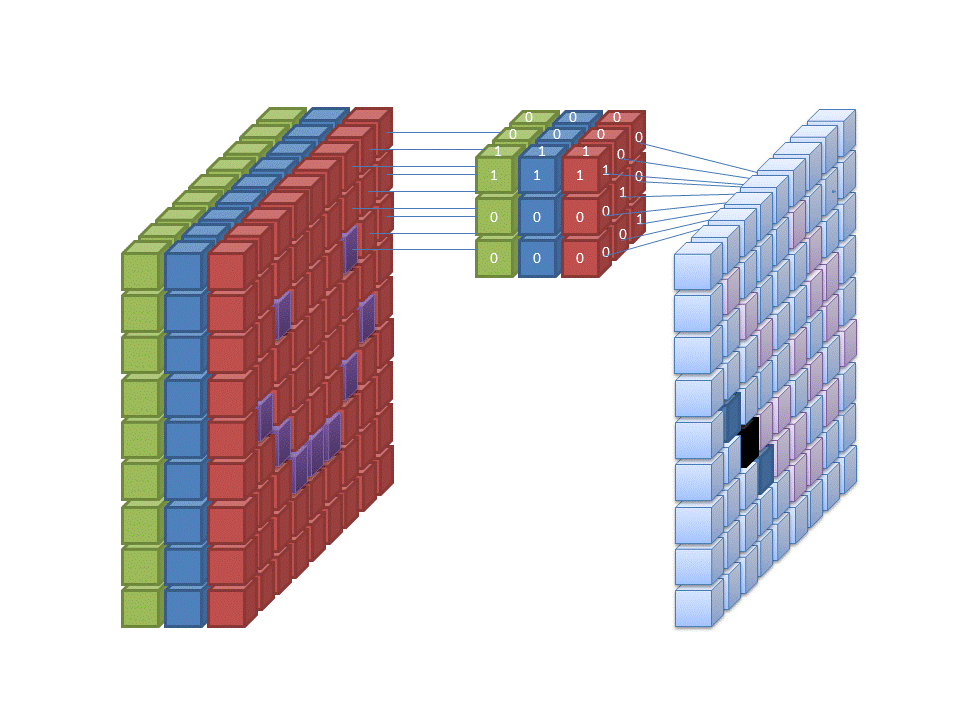
기존 모델은 모든 픽셀에 대해 가중치를 갖고 있습니다. 이미지 전체를 특징으로 이용하기 때문에 학습에 사용된 데이터에 관해서는 완벽에 가까울 정도로 특징을 잡아낼 수 있는데, 특징 위치가 바뀌게 되면 무용지물이 됩니다. 반대로 합성곱은 커널을 이미지 안에서 이리저리 움직이며 특징을 추출합니다. 볼 수 있는 시야는 좁아지는 대신, 위치와 무관하게 특징을 잡아낼 수 있습니다. 또 하나의 장점이 있습니다. 이미지 전체에 가중치를 두는 모델은 이미지 크기가 커지면 학습해야 하는 가중치 개수도 늘어나는데, CNN 커널 크기는 변화가 없습니다. 즉 커널을 사용하면 이미지 크기와 무관하게 학습해야 하는 가중치 개수가 같습니다. 학습할 가중치도 줄어들고, 특징의 위치에 대해 어느 정도 자유로워졌으니 두 마리 토끼를 다 잡은 셈이죠.
CNN 이해하기
CNN은 합성곱을 사용하는 신경망입니다. 합성곱 신경망, 콘불루션 신경망 다양하게 불리고 있습니다. 이미지에 특징이 하나만 있는게 아니라서 CNN은여러 층의 필터를 사용하여 이미지를 분류합니다. 그래서 셀로판지 필터와 달리 CNN의 필터는 여러층의 색, 모양을 제거 할 수 있습니다. 과거에는 CNN필터를 사람이 직접 설계 했지만 최근에는 딥러닝을 이용하여 만들고 있습니다. CNN은 딥러닝을 이용해 합성곱 필터를 학습하는 신경망 입니다.

합성곱(Convolution): 특징을 추출하는 과정
•
원본 이미지 (Input Image): 우리가 분석하고 싶은 사진입니다.
•
커널 (Kernel): '특징 돋보기'나 '필터'라고 생각하면 쉽습니다. 이 커널은 '수직선', '수평선', '특정 색상' 등 이미지의 아주 기본적인 특징을 찾아내는 역할을 합니다. 커널 안에는 학습을 통해 얻어진 **가중치(weights)**라는 숫자들이 들어있습니다.
•
연산 방식:

1.
커널을 원본 이미지의 왼쪽 맨 위부터 올려놓습니다.
2.
이미지에서 커널과 겹치는 부분의 각 픽셀 값을 커널의 해당 위치 값과 서로 곱합니다. (요소별 곱셈)
3.
곱해진 모든 값들을 전부 더해서 하나의 숫자를 만듭니다. 이 숫자가 바로 해당 위치에서 커널이 찾으려는 특징이 얼마나 강하게 나타나는지를 의미합니다.
4.
정해진 간격(stride)만큼 커널을 옆으로 옮겨가며 이 과정을 반복합니다.
즉 이렇게 추출한 특징들을 조합해 어떤 이미지인지 예측한다고 생각하면 됩니다.

위 그림은 CNN의 원리를 나타내고 있습니다. 사과 이미지 에는 여러 특징 이 섞여 있습니다 . 특징 으로 빨간 윤곽 , 하얗게 반사 되는 빛 , 갈색 가지 , 녹색 잎 을 추출 했네요 . 추출 된 특징 들 은 계속 합성 곱층 을 거치며 점점 미세한 특징 으로 변 합니다 . 최종적 으로 는 이렇게 모아진 특징 들은 MLP 의 입력 으로 들어 갑니다 . 오른쪽 에 보면 파란 동그라미 ○ 들이 보일 겁니다 . 각각 은 클 래스 를 나타 냅니다 . 각각 사과 , 바나나 , 수박 , 포도 를 가리킨다 고 해봅 시다 . 네 가지 과일 의 특징 을 추출 할 수 있는 커널 에 사과 이미지 를 입력 하면 사과 특징 에 큰 가중치 를 둘 겁니다 . 따라서 다 른 클래스 의 값 은 0 에 가깝게 됩니다 . 그 결과 입력 된 이미지 가 사과 라고 예측할 겁니다 . 즉 추 출한 특징 들을 조합 해 어떤 과일 인지 를 예측 한다 보면 됩니다 .
자주 사용하는 CNN 모델
VGG (Visual Geometry Group)

•
핵심 아이디어: 작고 깊게!
•
특징: VGG 이전의 모델들은 5x5나 7x7 같은 큰 사이즈의 '특징 돋보기'(커널)를 사용했습니다. 하지만 VGG는 3x3 크기의 작은 커널을 여러 층으로 깊게 쌓는 방식을 제안했습니다.
•
장점: 이렇게 작은 커널을 여러 번 사용하면, 큰 커널을 한 번 사용하는 것과 비슷한 효과(넓은 영역을 보는 효과)를 내면서도 학습해야 할 파라미터(가중치) 수를 크게 줄일 수 있습니다. 이는 모델을 더 효율적으로 만들었습니다.
ResNet (Residual Network)

•
핵심 아이디어: 지름길(Shortcut)을 만들자!
•
특징: 신경망이 VGG처럼 매우 깊어지면, 학습 과정에서 기울기가 점점 사라지는 **'기울기 소실 문제(Vanishing Gradient Problem)'**가 발생해 오히려 성능이 떨어지기도 합니다. ResNet은 이 문제를 해결하기 위해 **'스킵 연결(Skip Connection)'**이라는 획기적인 구조를 도입했습니다. 이는 몇 개의 층을 건너뛰어 입력 데이터를 출력에 바로 더해주는 '지름길'과 같습니다.
•
장점: 이 지름길 덕분에 기울기가 뒤쪽까지 잘 전달되어, VGG보다 훨씬 더 깊은 네트워크(수백, 수천 개 층)를 효과적으로 학습시킬 수 있게 되었습니다. 현재도 가장 널리 쓰이는 기본 모델 중 하나입니다.
Inception (GoogLeNet)

•
핵심 아이디어: 다양한 크기의 돋보기를 동시에 쓰자!
•
특징: 이미지 속 객체는 크기가 제각각이라, 어떤 크기의 커널이 가장 효과적일지 알기 어렵습니다. Inception 모델은 하나의 층 안에서 1x1, 3x3, 5x5 등 다양한 크기의 커널을 동시에 적용하고 그 결과들을 합치는 **'인셉션 모듈'**을 사용합니다.
•
장점: 이를 통해 모델이 다양한 스케일의 특징을 한 번에 잡아낼 수 있어 성능을 높였습니다. 또한, 3x3 커널을 여러 층 쌓아 큰 커널을 근사하는 등 VGG의 아이디어를 활용해 파라미터 수를 효율적으로 관리했습니다. VGG보다 **"넓은 시야(receptive field)"**를 효율적으로 확보한 셈입니다.
데이터 전처리하기
이제부터 실제로 CNN을 만들어 사물 이미지를 분류해보겠습니다. CIFAR-10은 10개 클래스를 갖는 대표적인 이미지 분류 데이터셋으로, 동물뿐 아니라 비행기/트럭/자동차 등 다양한 물체 이미지가 포함되어 있습니다.
1) 데이터셋 다운로드 및 샘플 확인
import matplotlib.pyplot as plt
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor
# CIFAR-10 불러오기
training_data = CIFAR10(
root="./", # 데이터를 내려받을 위치
train=True, # 학습용 데이터
download=True, # 없으면 다운로드
transform=ToTensor()# PIL -> Tensor 변환 (C,H,W), [0,1] 범위
)
test_data = CIFAR10(
root="./",
train=False, # 평가용 데이터
download=True,
transform=ToTensor()
)
# 샘플 9장 보기
for i in range(9):
plt.subplot(3, 3, i + 1)
plt.imshow(training_data.data[i])
plt.axis("off")
plt.show()
Python
복사

•
root: 데이터가 저장될 경로입니다. 여기서는 현재 폴더("./")를 사용합니다.
•
train: True면 학습용(50,000장), False면 테스트용(10,000장)을 불러옵니다.
•
download: 데이터가 없으면 자동으로 다운로드합니다.
•
transform: 데이터를 모델 입력 형태로 변환합니다. 여기서는 가장 기본인 ToTensor()로 텐서 변환만 수행합니다.
2) 데이터 증강(Data Augmentation)
데이터 증강은 학습 데이터를 “살짝 변형”하여 모델이 다양한 상황(위치 변화, 좌우 반전 등)에도 잘 일반화되도록 돕습니다. 특히 CIFAR-10처럼 작은 이미지에서는 간단한 증강만으로도 성능 차이가 크게 날 수 있습니다.
•
RandomCrop: 이미지를 약간 크게 만든 뒤(패딩) 다시 32×32로 랜덤하게 잘라 위치 변화에 강하게 만듭니다.
•
RandomHorizontalFlip: 좌우 반전을 랜덤하게 적용해 좌우 방향 변화에 강하게 만듭니다.
import torchvision.transforms as T
from torchvision.transforms import Compose, RandomCrop, RandomHorizontalFlip
transforms_train = Compose([
T.ToPILImage(),
RandomCrop((32, 32), padding=4),
RandomHorizontalFlip(p=0.5),
T.ToTensor(),
])
Python
복사
3) 이미지 정규화(Normalization)
컬러 이미지는 물체/배경에 따라 R/G/B 값 분포가 크게 치우칠 수 있습니다. 정규화는 채널별 평균과 표준편차로 스케일을 맞춰 학습을 안정화합니다.
•
정규화 형태: (x - mean) / std
•
CIFAR-10에서 자주 쓰는 값:
◦
mean = (0.4914, 0.4822, 0.4465)
◦
std = (0.2470, 0.2430, 0.2610)
from torchvision.transforms import Normalize
transforms_train = Compose([
T.ToPILImage(),
RandomCrop((32, 32), padding=4),
RandomHorizontalFlip(p=0.5),
T.ToTensor(),
Normalize(mean=(0.4914, 0.4822, 0.4465),
std =(0.2470, 0.2430, 0.2610)),
])
# 테스트 데이터는 보통 증강 없이 정규화만 적용합니다.
transforms_test = Compose([
T.ToTensor(),
Normalize(mean=(0.4914, 0.4822, 0.4465),
std =(0.2470, 0.2430, 0.2610)),
])
Python
복사
정규화 값(mean/std)은 데이터셋에 따라 달라집니다. 정확히 구하려면 학습 데이터 전체를 읽어 채널별 평균/표준편차를 계산하면 됩니다.
(참고) mean/std 직접 구하기
import torch
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor
training_data_raw = CIFAR10(root="./", train=True, download=True, transform=ToTensor())
imgs = torch.stack([img for (img, _) in training_data_raw], dim=0) # (N,C,H,W)
mean = imgs.mean(dim=(0, 2, 3))
std = imgs.std(dim=(0, 2, 3))
print("mean:", mean)
print("std :", std)
Python
복사
이제 전처리(증강 + 정규화)가 준비되었습니다. 다음 단계에서 이 데이터를 DataLoader로 묶고 CNN 모델을 학습시켜 보겠습니다.

import matplotlib.pyplot as plt
import torchvision.transforms as T
from torchvision.datasets import CIFAR10
from torchvision.transforms import Compose, RandomCrop, RandomHorizontalFlip
# (예시) 데이터 증강 전처리
transforms = Compose([
T.ToPILImage(),
RandomCrop((32, 32), padding=4),
RandomHorizontalFlip(p=0.5),
T.ToTensor(),
])
training_data = CIFAR10(
root="./",
train=True,
download=True,
transform=transforms,
)
test_data = CIFAR10(
root="./",
train=False,
download=True,
transform=transforms,
)
# 증강 결과 샘플 9장 확인
for i in range(9):
plt.subplot(3, 3, i + 1)
img = transforms(training_data.data[i])
# Tensor(C,H,W) -> 이미지로 보려면 HWC로 변환
plt.imshow(img.permute(1, 2, 0))
plt.axis("off")
plt.show()
Python
복사

데이터 증강을 적용한 후의 그림을 보면 일부는 좌우가 뒤집히거나(RandomHorizontalFlip), 일부는 가장자리가 잘린 형태(RandomCrop)로 보입니다. 이때 생기는 검정색 테두리 영역은 padding=4로 0 값이 채워진(제로 패딩) 부분입니다.
핵심 포인트
•
Compose([...]): 전처리 함수를 “리스트에 적은 순서대로” 적용합니다.
•
RandomCrop((32, 32), padding=4): 가장자리에 4픽셀을 패딩으로 붙인 뒤, 32×32를 랜덤하게 잘라냅니다.
•
RandomHorizontalFlip(p=0.5): 50% 확률로 좌우 반전을 적용합니다.
이미지 정규화(Normalization)
컬러 이미지는 R/G/B 채널별 값의 분포가 물체/배경에 따라 쉽게 치우칩니다(예: 붉은 자동차는 R 채널이 상대적으로 큼). 이런 채널별 스케일 차이가 크면 학습이 불안정해질 수 있어, 학습 전에 정규화를 적용하는 경우가 많습니다.
•
정규화는 보통 채널별로 (x - mean) / std 형태로 수행합니다.
•
목표는 각 채널의 분포를 비슷한 스케일로 맞춰, 옵티마이저가 더 안정적으로 학습하도록 돕는 것입니다.
정규화 : 데이터의 분포를 정규분포의 형태로 바꿔주 는 것. 정규분포(normal distribution)는 평 균과 표준편차로 설명하는 분포로, 평균이 0, 표준편차가 1인 정규분포를 표준 정규분포라 고 부른다. 정규화는 표준 정규분포를 주로 사 용합니다. 정규분포를 가우스 분포(Gaussian distribution)라고도 합니다.

그림 과 같이 빨간색 자동차 이미지 가 있을 때 적색 값들 분포 가 높습니다 . 반면 녹색 과 청색 은 낮 습니다 . 정규화 과정 을 거치고 나면 모든 색 의 분포 가 정규 분포 를 따르게 됩니다 . 이렇게 색 이 정규 분포 를 따르 도록 값 을 바꾸면 색도 변 합니다 . 하지만 걱정 하지 마세요 . ( 사람 이 볼 때는 이상 하지만 ) 색 이 변 하더라도 인공 지능 입장 에서는 색 이 갖는 분포 가 일정 해야 학습 이 제대로 이 루어 집니다 .
import matplotlib.pyplot as plt
import torchvision.transforms as T
from torchvision.datasets import CIFAR10
from torchvision.transforms import Compose, Normalize, RandomCrop, RandomHorizontalFlip
# (예시) 증강 + 정규화 전처리
transforms = Compose([
T.ToPILImage(),
RandomCrop((32, 32), padding=4),
RandomHorizontalFlip(p=0.5),
T.ToTensor(),
Normalize(
mean=(0.4914, 0.4822, 0.4465),
std =(0.2470, 0.2430, 0.2610),
),
])
training_data = CIFAR10(
root="./",
train=True,
download=True,
transform=transforms,
)
test_data = CIFAR10(
root="./",
train=False,
download=True,
transform=transforms,
)
# 전처리 적용 결과 샘플 9장 확인
for i in range(9):
plt.subplot(3, 3, i + 1)
img = transforms(training_data.data[i])
plt.imshow(img.permute(1, 2, 0))
plt.axis("off")
plt.show()
Python
복사

이미지 를 정규화 합니다 . 정규 분포 는 평균 과 표준 편차 로 나타내는데 mean 은 평균 을 , std 는 표 준 편차 를 나타 냅니다 . 괄호 안의 값 들은 차례 대로 R , G , B 채널 의 값 을 의미 합니다 . 데이터 셋 에 따 라 값 들이 달라 지기 때문에 직접 구해야 하지만 유명 데이터 셋 의 값 을 사용 하는 경우 도 있습니다 .
import torch
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor
# ToTensor()를 거치면 이미지가 (C, H, W) 형태의 Tensor가 됩니다.
training_data = CIFAR10(
root="./",
train=True,
download=True,
transform=ToTensor(),
)
# (N, C, H, W)로 쌓기
imgs = torch.stack([img for (img, _) in training_data], dim=0)
# 채널별 mean/std 계산 (C 차원만 남기고 나머지 축 평균)
mean = imgs.mean(dim=(0, 2, 3))
std = imgs.std(dim=(0, 2, 3))
print("mean:", mean)
print("std :", std)
Python
복사
여기서 imgs는 “이미지 여러 장”을 담고 있는 파이썬 리스트(list) 입니다. 리스트는 규칙이 느슨해서, 안에 들어있는 데이터의 모양(shape)이 조금씩 달라도(심지어 타입이 달라도) 그대로 담아둘 수 있습니다.
하지만 딥러닝 연산(평균/표준편차 계산, 배치 학습 등)을 하려면 보통 데이터가 하나의 큰 텐서(tensor) 로 묶여 있어야 합니다. 텐서는 배열이기 때문에, 안에 들어있는 모든 원소가 같은 모양(shape) 을 가져야만 합니다.
그래서 다음처럼 리스트에 있는 이미지들을 torch.stack()으로 쌓아 (N, C, H, W) 형태로 만듭니다.
•
예) 한 장이 (224, 224)이면, 3장을 dim=0으로 stack → (3, 224, 224)
•
CIFAR-10은 한 장이 (C, H, W) = (3, 32, 32)이므로, N장을 stack → (N, 3, 32, 32)
torch.stack(tensors, dim)
•
여러 텐서를 “새로운 축(dim)”을 만들어 한 번에 묶습니다.
•
배치 데이터는 보통 dim=0에 쌓아서 맨 앞 차원이 배치 크기 N이 되게 합니다.
정리하면, 리스트는 “그냥 모아두기”에 편하지만 학습/통계 계산엔 불리하고, 텐서는 “모양이 일정한 데이터”를 빠르게 계산하기 위해 필요하다고 생각하면 됩니다.

이로써 원본 이미지에 데이터 증강, 데이터 정규화를 적용했습니다. 학습에 필요한 데이터를 마련 했으니 이제 모델을 만들어봅시다.
CNN으로 사물 이미지 분류해보기
전처리가 끝났으니, 이제는 CNN(Convolutional Neural Network) 으로 CIFAR-10 이미지를 10개 클래스로 분류해 봅니다.
실습 목표
•
입력 이미지(32×32 RGB) 를 10개 클래스(airplane, automobile, …) 중 하나로 분류
•
학습 후 모델을 저장하고 불러온 뒤, 테스트 데이터로 정확도 평가
문제 정의
•
데이터셋: CIFAR-10
•
문제 유형: 다중 분류
•
손실 함수: Cross Entropy (CE)
•
평가 지표: Accuracy
모델 정의: nn.Module로 CNN 구성
파이토치에서는 층을 모듈(nn.Module)이라고 부릅니다. 우리가 만들 모델도 이 모듈 객체를 상속받아 사용하겠습니다. 모듈은 특징을 추출하거나 퍼셉트론의 활성화를 담당하거나 가중치를 업데이트하는 데 필요한 손실을 계산하는 층이 될 수도 있습니다. 모든 것을 모듈로 관리하는 이유는 특징 추출인 순전파와 가중치 업데이트 과정인 역전파에 사용되는 계산 결과와 기울기를 함께 관리하기가 쉽기 때문입니다. 모듈에는 딥러닝에 사용되는 모든 파라미터가 저장되어 있습니다.
간단한 신경망은 nn.Sequential로, 복잡한 신경망은 nn.Module로 만드는 것이 효율적입니다.
nn.Sequential은 층을 쌓기만 하는 간단한 구조에서 사용하기에 편리합니다. 하지만 은닉층에서 순전파 도중의 결과를 저장하거나 데이터 흐름을 제어하는 등 커스터마이징은 어렵습니다. 반면 nn.Module은 원하는 방식으로 신경망의 동작을 정의할 수 있으므로, 복잡한 신경망은 nn.Module을 이용하는 것이 좋습니다.
•
간단한 순차 구조는 nn.Sequential로 빠르게 만들 수 있습니다.
•
하지만 블록을 반복하거나 중간 흐름을 제어하는 등 커스터마이징이 필요하면 nn.Module이 유리합니다.
(1) 디바이스 설정
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
Python
복사
(2) 기본 블록(BasicBlock) 설계
이 예제의 기본 블록은 다음으로 구성됩니다.

•
Conv(3×3) → ReLU → Conv(3×3) → ReLU → MaxPooling(2×2)
합성 곱 3 × 3 은 커널 크기 가 3 × 3 ( 3 행 3 열 ) 인 합성 곱 연산 을 의미 합니다 . ReLU 는 0 보다 큰 값 만을 다음 뉴런 으로 넘기는 활성화 함수 입니다 . 앞으로는 별도 의 언급 이 없다면 활성화 함수 로 ReLU 를 사용 한다고 생각 해주세요 . 최대 풀링 은 이미지 크기 를 절반 으로 줄이는 연산 으로 합 성 곱을 통해 얻은 특징 의 위치 정보 를 의도적 으로 없애 오버 피팅 을 피하는 기법 입니다 . 커널 을 이 동 하면서 커널 안의 최댓값 만을 남기는 것으로 , 중요한 특징 의 값 을 알 수 있습니다 . 반면 위치 는 알 수 없습니다 .
최대 풀링 은 그림 을 보면서 자세히 살펴 보겠습니다 .
입력 이미지 크기 가 4 × 4 이고 , 커널 은 2 × 2 일 때 이동 거리 를 2 로 정해서 최대 풀링 을 진행 합니다 . 각 영역 에서 출력 결과 는 최댓값 입니다 . 출력 결과 만 봐서는 각 최댓값 의 기존 위치 를 절대 알 수 없습 니다 . 비록 위치 는 알 수 없지만 , 커널 이 이동 하면서 특징 을 조사 하기 때문에 이미지 안에서 특징 을 샅샅이 찾아 낼 수 있는 겁니다 .
최대 풀링
풀링은 최댓값을 적용하는 최대 풀링과 평균값을 적용하는 평균 풀링이 있습니다.

기본 구조를 활용해 VGG의 기본 블록을 만들어봅시다. 기본 블록을 반복적으로 불러와 CNN을 만들게 됩니다. 이번 장부터는 nn.Sequential 클래스를 이용하지 않고 nn.Module 클래스를 사용합니다. nn.Sequential 클래스는 데이터 흐름이 한 방향, 즉 입력층에서부터 출력층까지 순차적으로 흘 러가는 경우에 한해서 사용 가능합니다. 즉, 데이터 흐름을 마음대로 제어할 수 없다는 뜻입니다. 그래서 신경망의 동작을 내가 원하는 대로 커스터마이징할 때는 nn.Module 클래스를 이용합니 다. 앞으로는 점점 더 복잡한 신경망이 차례대로 등장하므로 이번 장에서 nn.Module에 대해서 확실히 알고 넘어갑시다.
import torch.nn as nn
class BasicBlock(nn.Module):
"""합성곱 2개 + MaxPooling으로 구성된 기본 블록"""
def __init__(self, in_channels, out_channels, hidden_dim):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, hidden_dim, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(hidden_dim, out_channels, kernel_size=3, padding=1)
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
x = self.pool(x)
return x
Python
복사
super(...).__init__()는 왜 필요한가?
BasicBlock이 nn.Module을 상속받으면,
•
파라미터 등록
•
GPU/CPU 이동
•
저장/불러오기(state_dict)
같은 기능을 프레임워크가 자동으로 처리할 수 있게 됩니다.
Conv2d 파라미터 해석 : 최대 풀링을 실행합니다.
•
in_channels: 입력 채널 수(예: RGB면 3)
•
out_channels: 출력 채널 수(=필터 개수)
•
kernel_size=3: 3×3 커널
•
padding=1: 가장자리에 0을 채워 공간 크기(높이/너비) 유지
MaxPooling의 의미 : 합성곱을 계산 합니다.
MaxPool2d(kernel_size=2, stride=2)는 2×2 영역에서 최댓값만 남겨서
•
H,W를 절반으로 줄이고
•
위치 정보를 일부 버리는 대신 과적합을 줄이고
•
계산량을 줄이는 효과가 있습니다.
(3) CNN 전체 구조 정의
기본 블록 정의 가 끝났 습니다 . 이제는 전체 CNN 모델 을 정의 해 봅시다 . 먼저 다음 그림 을 봐주세 요 . 앞서 정의한 합성 곱 기본 블록 을 거칠 때 마다 이미지 크기 는 절반 으로 줄어 듭니다 . 세 번째 블록 을 거친 이미지 는 평탄화 flatten 층 을 거치게 됩니다 . 평탄화 층 은 이미지 를 일렬 로 펴주 는 역할 을 합니다 .

MLP 층 은 벡터 만을 입력 으로 받을 수 있기 때문에 가로 세로 로 나열된 이미지 는 MLP 의 입력 으 로 사용할 수 없습니다 . 따라서 평탄화 층 을 이용 하면 이미지 를 MLP 의 입력 으로 사용할 수 있게 됩니다 . 일렬 로 펴진 특징 맵 은 분류기 의 입력 으로 들어가 확률 분포 를 출력 합니다 .

•
32×32 → 16×16 → 8×8 → 4×4
기본 블록 을 한 번 거칠 때 마다 이미지 크기 가 절반 으로 줄어 듭니다 . 입력 이미지 가 32 × 32 이므 로 기본 블록 을 3 번 호출 하면 이미지 크기 가 4 × 4 로 줄어 듭니다 . 이제 각 합성 곱층 의 커널 개수 를 정의 해주고 , 분류 를 위한 MLP 층 을 정의 하면 CNN 이 완성 됩니다 .
class CNN(nn.Module):
"""BasicBlock 3개 + 완전연결층으로 구성된 CNN 분류기"""
def __init__(self, num_classes):
super(CNN, self).__init__()
self.block1 = BasicBlock(in_channels=3, out_channels=32, hidden_dim=16)
self.block2 = BasicBlock(in_channels=32, out_channels=128, hidden_dim=64)
self.block3 = BasicBlock(in_channels=128, out_channels=256, hidden_dim=128)
# 256 x 4 x 4 = 4096
self.fc1 = nn.Linear(4096, 2048)
self.fc2 = nn.Linear(2048, 256)
self.fc3 = nn.Linear(256, num_classes)
self.relu = nn.ReLU()
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x) # (B, 256, 4, 4)
x = torch.flatten(x, start_dim=1) # (B, 4096)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x) # logits
return x
model = CNN(num_classes=10)
model.to(device)
Python
복사
torch.flatten(x, start_dim=1)의 의미
•
x가 (B, C, H, W)일 때
•
배치 차원(B)은 유지하고(start_dim=1부터)
•
나머지 (C×H×W)를 1차원으로 펼칩니다.
즉, (B, 256, 4, 4) → (B, 4096)
학습(Training)
from torch.optim import Adam
lr = 1e-3
optim = Adam(model.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
for epoch in range(100):
model.train()
for data, label in train_loader:
optim.zero_grad()
preds = model(data.to(device))
loss = criterion(preds, label.to(device))
loss.backward()
optim.step()
if epoch == 0 or (epoch + 1) % 10 == 0:
print(f"epoch {epoch+1:3d} | loss: {loss.item():.4f}")
Python
복사
CE를 쓰면 Softmax는 어디서?
nn.CrossEntropyLoss()는 내부에 LogSoftmax가 포함되어 있으므로,
•
모델은 Softmax 이전의 logits를 출력하고
•
손실 함수가 logits → 확률 변환을 포함해서 처리합니다.
저장/불러오기
torch.save(model.state_dict(), "CIFAR10.pth")
model.load_state_dict(torch.load("CIFAR10.pth", map_location=device, weights_only=True))
Python
복사
•
state_dict()는 학습된 가중치를 딕셔너리로 반환합니다.
•
map_location=device로 CPU/GPU 어디에 올릴지 지정할 수 있습니다.
평가(Evaluation) — Accuracy 계산
model.eval()
num_corr = 0
with torch.no_grad():
for data, label in test_loader:
output = model(data.to(device))
preds = output.data.max(1)[1]
num_corr += preds.eq(label.to(device)).sum().item()
print(f"Accuracy: {num_corr / len(test_data):.4f}")
Python
복사
•
model.eval()로 평가 모드 전환
•
torch.no_grad()로 기울기 계산 비활성화
•
output.data.max(1)[1]는 클래스 차원(dim=1)에서 최댓값의 인덱스(예측 클래스) 를 가져옵니다.
•
eq → sum → item 순서로 “맞춘 개수”를 누적합니다.
샘플 이미지 저장(확인용)
import matplotlib.pyplot as plt
classes = training_data.classes
for i in range(9):
plt.subplot(3, 3, i + 1)
plt.imshow(training_data.data[i])
plt.title(classes[training_data.targets[i]], fontsize=8)
plt.axis("off")
plt.suptitle("CIFAR10 Sample Images")
plt.tight_layout()
plt.savefig("cifar10_samples.png")
print("샘플 이미지 -> cifar10_samples.png 저장 완료")
Python
복사
핵심 정리
•
학습 데이터에는 증강(RandomCrop, Flip)을 적용해 일반화를 높입니다.
•
모델은 BasicBlock을 반복해 특징을 추출하고, flatten 후 FC로 분류합니다.
•
평가는 eval() + no_grad()로 수행하고, argmax로 예측 클래스를 얻어 정확도를 계산합니다.