

핵심 목표 미리 보기

1. ResNet과 스킵 커넥션 (Skip Connection)
스킵 커넥션은 ResNet의 핵심 아이디어로, 신경망에 **'지름길'**을 만들어주는 구조입니다.
일반적으로 데이터는 층을 순서대로 하나씩 통과하지만, 스킵 커넥션은 몇 개의 층을 건너뛰어 입력 데이터를 바로 출력 쪽에 더해줍니다.
•
왜 필요한가요?: 신경망이 너무 깊어지면 오히려 학습이 잘 안되는 문제가 생깁니다. 스킵 커넥션이라는 지름길을 두면, 정보나 기울기(학습 신호)가 소실되지 않고 네트워크 깊숙한 곳까지 잘 전달될 수 있습니다.
•
ResNet: 바로 이 스킵 커넥션 구조를 활용해서 VGG보다 훨씬 깊은 네트워크를 성공적으로 쌓아 올린 모델입니다.
2. 기울기 소실 (Gradient Vanishing)
기울기 소실은 깊은 신경망에서 학습 신호가 맨 앞까지 전달되지 못하고 중간에 사라져 버리는 현상입니다.
'소문내기 게임'을 생각해보세요. 여러 사람을 거치면서 처음 내용이 점점 변하고 흐려지다가 나중에는 아예 다른 이야기가 되는 것과 비슷합니다. 신경망에서도 층을 거꾸로 거슬러 올라가는 학습 신호(기울기)가 너무 작아져 0에 가까워지면, 앞쪽 층의 가중치들이 업데이트되지 않아 학습이 멈추게 됩니다.
3. 배치 정규화 (Batch Normalization)
배치 정규화는 신경망 각 층을 통과하는 데이터의 분포를 일정하게 **'표준화'**시켜주는 작업입니다.
각 층이 처리하기 좋은 형태로 데이터를 계속해서 정돈해준다고 생각하면 쉽습니다. 데이터가 한쪽으로 쏠리거나 너무 퍼지는 것을 막아주기 때문에, 학습 과정이 훨씬 안정적이고 빨라지는 효과가 있습니다.
4. nn.Sequential vs. nn.Module
이 둘은 파이토치(PyTorch)에서 신경망 모델을 만드는 두 가지 방식입니다.
•
nn.Sequential: 레고 블록을 순서대로 쭉 쌓는 것과 같습니다. 간단하고 편리하지만, A층에서 C층으로 바로 연결하는 등의 복잡한 구조(예: 스킵 커넥션)는 만들 수 없습니다.
•
nn.Module: 다양한 레고 부품으로 자유롭게 조립하는 것과 같습니다. 데이터가 흘러가는 방식(forward 메서드)을 직접 설계해야 해서 조금 더 복잡하지만, ResNet의 스킵 커넥션처럼 원하는 어떤 복잡한 구조든 만들 수 있는 유연성을 제공합니다.
5. 평균 풀링 (Average Pooling)
평균 풀링은 이미지의 특징 맵(Feature Map) 크기를 줄이는 방법 중 하나입니다. 특정 구역(커널)을 정하고, 그 안에 있는 모든 픽셀 값의 평균을 구해 대표값으로 삼습니다.
이는 해당 구역의 특징을 전반적으로 부드럽게 요약하는 효과가 있습니다. (참고로, 가장 큰 값을 대표로 뽑는 방식은 '최대 풀링(Max Pooling)'이라고 합니다.)
ResNet
이번 장에서는 스킵 커넥션을 사용하는 CNN 모델인 ResNet 모델을 알아보고 직접 만들어 CIFAR-10 데이터를 학습해보겠습니다. ResNet은 스킵 커넥션을 사용해서 VGG에 비해 훨씬 더 많은 층을 쌓습니다. 또한 nn.Module을 이용하여 신경망 내부의 데이터 흐름을 제어합니다.
ResNet은 CNN 중에서 가장 많이 쓰이는 모델입니다. 앞에서 VGG 모델은 층을 많이 쌓으면 기울기 소실 문제가 발생합니다. 그래서 VGG는 합성곱층을 19층 이상 쌓을 수 없었습니다. 하지만 ResNet은 스킵 커넥션(skip connection)을 이용해 기울기 소실 문제를 상당 부분 해결했습니다.
가장 깊은 ResNet 모델은 합성곱층을 100층까지 쌓을 수 있습니다. CNN에서 하나의 층은 곧 한 번의 특징 추출입니다. CNN은 층을 여러 개 쌓아 많은 특징을 확보한 후, 이를 조합해 이미지를 분류합니다. 그렇다면 층이 많으면 많을수록 좋을까요? 옛말에 과유불급, 과한 것은 적은 것만 못하다는 말이 있습니다.
딥러닝에서도 마찬가지로 층을 너무 많이 쌓으면 오히려 성능이 낮아집니다. CNN에서는 층 하나를 거칠 때마다 픽셀 하나가 원본 이미지에서 차지하는 영역이 넓어집니다. 합성곱을 거칠 때마다 이미지 크기가 줄어드니, 특징 맵의 픽셀 하나는 이전 층의 여러 픽셀 정보를 압축한 것이라고 볼 수 있습니다. 따라서 층을 무한정 쌓으면 이미지 전체가 픽셀 하나로 압축되어, 나중에 특징을 조합해 분류할 때 불리하게 작용합니다. 또 다른 부작용으로 기울기 소실이 있습니다.
딥러닝은 모든 파라미터의 협력 과제입니다. 모두가 최선의 결과를 위해 일해준다면 더할 나위 없지만, 항상 문제는 생기기 마련입니다. 오차 역전파를 통해 가중치를 업데이트할 때, 신경망의 앞쪽(입력층에 가까운 쪽)에 올수록 신경망의 뒷쪽(출력층에 가까운 쪽)의 기울기가 누적되어 곱해집니다. 만약 뒤쪽 기울기들이 0에 가까울 정도로 작다면 역전파되는 값이 점점 0에 가까워지고, 반대로 값이 너무 크면 역전파되는 값이 점점 커집니다.
기울기 소실 이미지

학자들은 이 문제를 어떻게 해결했을까요? 다음 그림은 ResNet의 기본 구조입니다.
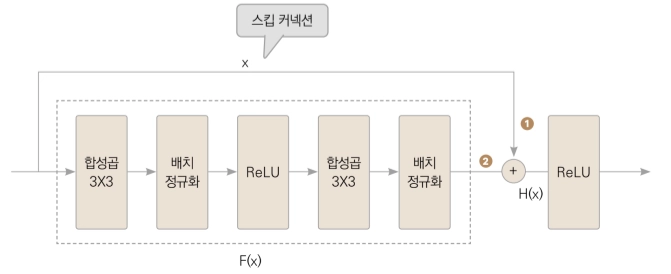

기울기 소실 문제 를 해결 하는 데 스킵 커넥션 을 사용 합니다 . 스킵 커넥션 은 자기 자신 을 미분 하면 1 이 나오기 때문에 신경망 의 출력 부분 에 입력 을 더하는 방식 으로 기울기 를 최소 1 로 확 보 하는 기법 입니다 . 그림 을 보면 합성 곱 되기 전의 입력 이 최종 적인 신경망 의 출력 과 더 해 집니다 . 다시 말하면 출력 가 됩니 다 . 이렇게 입력 값 가 합성 곱층 을 건너 뛰고 출력 에 더 해지 기 때문에 이런 구조 를 스킵 커넥션 이라고 부릅니다 . ● 는 은닉층 을 거친 이후 의 출력 을 과 더 합니다 .
스킵 커넥션 을 이용하는 또 다른 이유로 는 학습 이 쉬워 진다 는 겁니다 . 그림 에서 최적화 해야 하 는 함수 는입니다 . 다른 관점 에서 보면 가 되며 는 신경망 의 출력 과 입력 의 차 를 의미 합니다 . 스킵 커넥션 이 없는 학습 은 H ( x ) 의 최적화 였습니 다 . ResNet 의 학습 은 의 최소화 입니다 . x 는 입력 값 이기 때문에 고정 된 값 이므로 , H ( x ) 와 x 의 차이 를 최소화 합니다 . H ( x ) 와 x 의 차이 를 최소화 한다는 것은 H ( x ) 와 x 를 비슷하게 , 즉 F ( x ) 를 0 으로 만드는 겁니다 . 쉽게 말하자면 기존 의 학습 은 알 수 없는 지점 인 최적화 점 을 향해 갔다고 하면 ResNet 은 0 이라는 뚜렷한 목표가 생긴 겁니다 . 애매 모호한 지시 보다는 명확한 지시 가 알기 쉽듯 , 학습 도 목표가 생기면 쉬워 지는 겁니다 .
스킵 커넥션 ( skip connections )
은닉층 을 거치지 않은 입력 값 을 은닉 층 의 출력값 과 더하는 구조
기울기 소실 문제 를 해결 하는 데 스킵 커넥션 을 사용 합니다 . 스킵 커넥션 은 자기 자신 을 미분 하면 1 이 나오기 때문에 신경망 의 출력 부분 에 입력 을 더하는 방식 으로 기울기 를 최소 1 로 확 보 하는 기법 입니다 .
딥러닝 모델이 깊어질수록 흔히 나타나는 문제 중 하나가 바로 기울기 소실(Vanishing Gradient) 입니다. 이 문제를 해결하기 위해 스킵 커넥션(skip connection) 구조가 사용됩니다. 스킵 커넥션은 입력값 x를 그대로 출력단에 더해주는 방식으로, 신경망이 최소한 입력값 자체(즉, 자기 자신)를 전달할 수 있도록 보장해줍니다.
이 덕분에 신경망의 기울기가 1 이상 유지되어, 학습이 안정적으로 진행됩니다. 그림을 보면 입력 x가 합성곱층을 거쳐 얻은 출력 F(x)와 더해져 최종 결과는 다음과 같이 표현됩니다.
즉, 입력 x를 그대로 건너뛰어(skip) 최종 출력에 더해주는 구조이기 때문에 이를 ‘스킵 커넥션’이라고 부릅니다.
장점
• 층을 깊게 쌓을 수 있습니다.
•
VGG에 비해 학습이 안정적입니다.
•
기울기 소실 문제를 어느 정도 해결합니다.
단점
• 가중치가 늘어나기 때문에 계산량이 많아집니다.
•
VGG에 비해 오버피팅이 일어나기 쉽습니다.
유용한 곳
• 이미지 분류, 세그멘테이션, 이미지 생성 등 합성곱을 이용하는 모든 곳에서 이용 가능합니다.
•
이미지의 특징을 추출할 때 사용합니다.
•
스킵 커넥션은 이전 은닉층의 정보를 필요로 하는 텍스트 처리에서도 사용할 수 있습니다.
배치 정규화 (batch normalization)


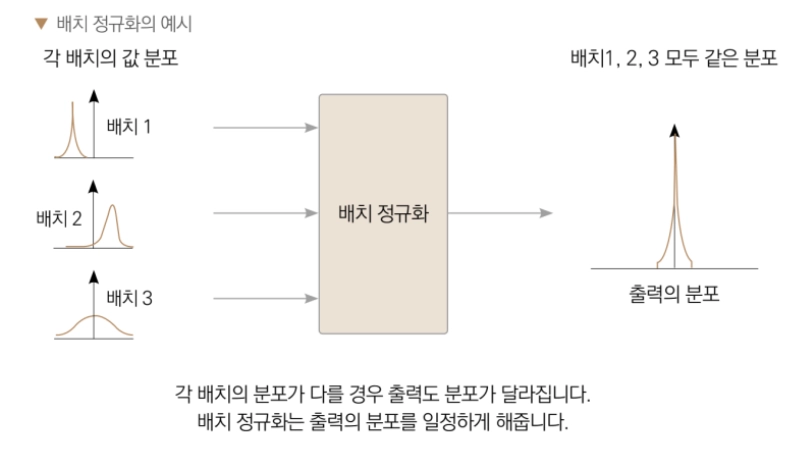
러닝 모델 의 층 이 깊어 지다 보면 각 층 마다 값 의 범위 가 달라지는 경우 가 있습니다 . 모델 을 학 습할 때 모든 데이터 를 한 번 에 이용 하지 않고 , 배치 단위 로 나눠서 학습 하게 되는데 배치 간의 데이터 분 포가 달라서 생기는 현상 입니다 . 배치 정규화 는 이런 분포 의 불균형 을 해결 하는 기법 입니다 . 배치 정규화 층 이 각 층 에서 의 값 의 분포 가 일정 하도록 해줍니다 . 그림 을 보면서 배치 정규화 를 알아 보겠습니다 .
배치 정규화란?
배치 정규화는 신경망 학습 과정에서 각 층을 통과하는 데이터의 분포가 들쭉날쭉 변하지 않도록 일정한 형태로 '표준화'시켜주는 기법입니다.


이미지에서 볼 수 있듯이, **'배치 1, 2, 3'**은 각각 모양(분포)이 다릅니다. 어떤 배치는 평균이 높고, 어떤 배치는 데이터가 넓게 퍼져있죠. 이렇게 제각각인 데이터가 그대로 다음 층으로 전달되면, 신경망이 학습하기 매우 까다로워집니다. 마치 매번 다른 종류의 공을 받아서 던져야 하는 투수와 같아요.
배치 정규화는 이 문제점을 해결하기 위해, 각 배치들을 평균이 0, 분산이 1인 표준 정규분포와 유사한 형태로 바꿔줍니다. 그 결과, 이미지의 오른쪽처럼 모든 배치가 비슷한 분포를 가진 안정적인 출력으로 변환됩니다.
배치 정규화를 왜 사용할까요?
1.
학습 속도 향상 (더 빠른 학습): 각 층에 들어오는 데이터의 분포가 일정해지므로, 신경망이 훨씬 빠르고 안정적으로 학습할 수 있습니다.
2.
기울기 소실/폭주 문제 완화: 데이터 값이 너무 커지거나 작아지는 것을 막아주어, 학습 신호(기울기)가 사라지거나 폭발하는 현상을 줄여줍니다.
3.
규제(Regularization) 효과: 학습 데이터에 약간의 노이즈를 추가하는 것과 비슷한 효과를 주어, 모델이 특정 데이터에만 과도하게 적응하는 **과대적합(Overfitting)**을 방지하는 데 도움이 됩니다.
쉽게 말해, 배치 정규화는 신경망의 각 층마다 **'데이터 정리 도우미'**를 두어, 데이터가 엉망이 되지 않도록 계속해서 정돈해주면서 학습을 돕는 똑똑한 기법이라고 할 수 있습니다.
이제 ResNet 을 이용해 CIFAR-10 데이터를 분류해보자.
기본 블록 정의 하기
스킵 커넥션 을 만드는 데 nn.Module 을 이용 합니다 . 간단한 구조 에는 nn.Sequential , 복잡한 구조 에는 nn.Module 을 이용 합니다 . nn.Sequential 은 데이터 흐름 을 제어 할 수가 없기 때문 에 간단한 구조 에만 적합 합니다 . ResNet 에서는 블록 의 입력 이 출력 에 그대로 더해져야 하기 때 문 에 데이터 흐름 이 단방향 이 아닙니다 . 데이터 가 단순히 앞으로 만 전달 되는 간단한 구조 에서만 nn.Sequential 을 이용 해주세요 . 먼저 ResNet 의 기본 합성 곱층 을 정의 하겠습니다
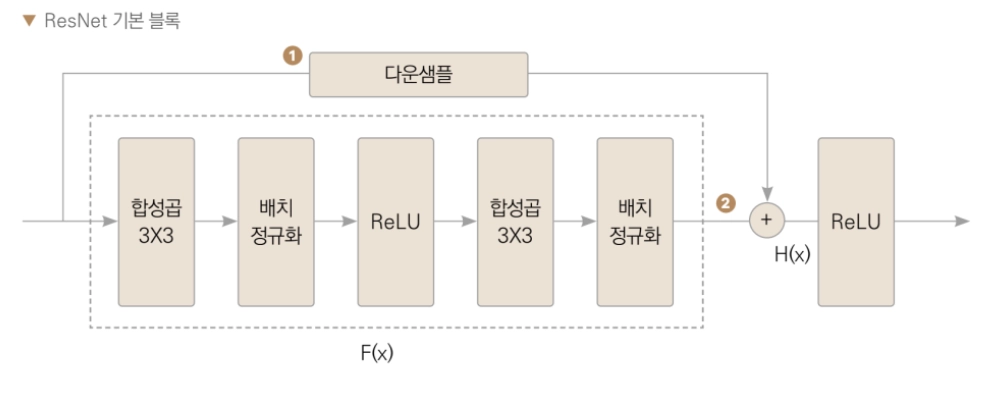
다운샘플(Downsample)
스킵 커넥션에서 입력값과 합성곱의 결과를 더해주기 위해 입력값에 1x1합성곱으로 채널 수를 맞춰주는 기법을 말합니다.
스킵 커넥션은 은닉층의 결과와 입력값을 더하는 구조입니다. 하지만 이미지의 채널은 3개인 데에 반해 특징 맵의 채널은 64개, 많게는 256개까지 늘어납니다. 3채널 이미지와 64채널 이미 지는 서로 더해줄 수 없기 때문에 채널 숫자를 맞춰줘야 합니다. 원본 이미지의 특징을 손상시키 지 않도록 1×1 합성곱을 이용해 채널의 숫자를 맞춰주겠습니다. 그림에서 다운샘플이라고 되 어 있는 층이 1×1 합성곱층입니다(즉 스킵 커넥션을 위 해 입력과 출력의 채널 개수를 맞춰주는 겁니다). 2 은 닉층을 거친 출력과 다운샘플층을 거친 입력을 더해주고 ReLU 함수로 활성화 해줍니다.
import torch
import torch.nn as nn
class BasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3):
super(BasicBlock, self).__init__()
# 1) 합성곱층 정의
self.c1 = nn.Conv2d(
in_channels, out_channels, kernel_size=kernel_size, padding=1
)
self.c2 = nn.Conv2d(
out_channels, out_channels, kernel_size=kernel_size, padding=1
)
# 입력과 출력의 채널 수를 맞추기 위한 1×1 합성곱(다운샘플)
self.downsample = nn.Conv2d(in_channels, out_channels, kernel_size=1)
# 2) 배치 정규화층 정의
self.bn1 = nn.BatchNorm2d(num_features=out_channels)
self.bn2 = nn.BatchNorm2d(num_features=out_channels)
self.relu = nn.ReLU()
Python
복사
1.
합성곱층을 정의합니다.
2.
배치 정규화층도 정의합니다. 배치 정규화층은 앞에 오는 합성곱층 의 출력 채널만큼의 특징을 갖습니다. 즉, num_features 안에 합성곱층의 출력 채널 수, out_ channels가 들어가는 겁니다.
BatchNorm2d(feature) : 배치 정규화를 실행합니다. features개의 특징에 대해서 실행합니다. 이미지의 채널수에 맞추면 됩니다.
모델의 순전파 정의
def forward(self, x):
# 스킵 커넥션을 위해 초기 입력 저장
x_ = x
# ResNet 기본 블록에서 F(x) 부분
x = self.c1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.c2(x)
x = self.bn2(x)
# 합성곱 결과와 입력의 채널 수를 맞춤 (다운샘플)
x_ = self.downsample(x_)
# 합성곱층 결과와 저장해 둔 입력을 더해줌 (스킵 커넥션)
x += x_
x = self.relu(x)
return x
Python
복사
3.
스킵 커넥션 은 입력 값 과 합성 곱층 의 출력 을 더 해줘야 합니다 . x_ 변수 를 지정해 값 을 미리 저 장해 줍시다 . 신경망 을 거치기 전의 입력 값 을 저장 해야 하기 때문 입니다 .
4.
하지만 입력 이미지 의 채널 은 3 채널 인데 특징 맵 은 훨씬 많은 채널 을 갖고 있습니다 . 이대로는 더해줄 수 없으니 , self . downsample 을 이용해 채널 개수 를 맞춰 줘야 합니다 .
5.
마지막 으로 합성 곱층 의 출력 , 즉 특징 맵 과 다운 샘플 층 의 특징 맵 을 더 해주면 ResNet 기본 블록 이 완성 됩니다 . 이렇게 입력 값 과 출력 값 을 더해주는 방법 을 스킵 커넥션 이라고 부릅니다 .
ResNet 모델 정의하기
BasicBlock 클래스 정의 를 마쳤 으니 ResNet 모델 을 작성해 봅시다 . 먼저 모델 의 초기화 를 살펴 보겠습니다.
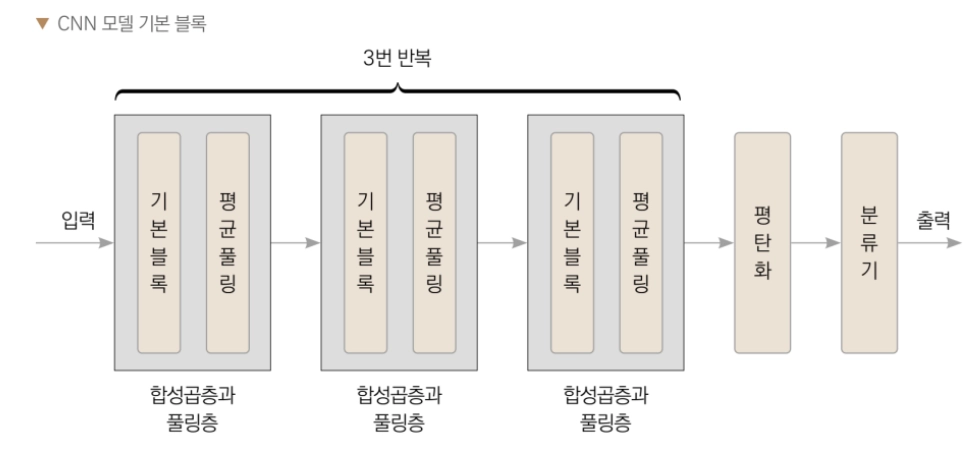
입력 값 은 합성 곱 기본 블록 과 평균 풀링 층 을 거 칩니다 . 총 세 번 , 합성 곱층 과 풀링 층 을 거친 다음 , 분류 기층 으로 들어가 최종 결과 를 예측 합니다 . 여기서 블록 을 몇 번 쌓을 지는 이미지 크기 에 따라 서 결정 됩니다 . 풀링 층 을 한 번 거칠 때 마다 이미지 의 가로 세로 길이 가 절반 이 되므로 , 32 × 32 크기 입력 이미지 가 4 × 4 이미지 가 되려면 블록 을 3 개만 사용해야 합니다 .
class ResNet(nn.Module):
def __init__(self, num_classes=10):
super(ResNet, self).__init__()
# 기본 블록
self.b1 = BasicBlock(in_channels=3, out_channels=64)
self.b2 = BasicBlock(in_channels=64, out_channels=128)
self.b3 = BasicBlock(in_channels=128, out_channels=256)
# 풀링을 최댓값이 아닌 평균값으로
self.pool = nn.AvgPool2d(kernel_size=2, stride=2)
# 분류기
self.fc1 = nn.Linear(in_features=4096, out_features=2048)
self.fc2 = nn.Linear(in_features=2048, out_features=512)
self.fc3 = nn.Linear(in_features=512, out_features=num_classes)
self.relu = nn.ReLU()
Python
복사
1.
먼저 기본 블록을 정의합니다. 일반적으로 ResNet은 약 34번의 합성곱을 거치게 됩니 다. 여기서는 메모리 사용을 최대한 줄이기 위해 블록 3개를 사용하겠습니다.
2.
이번에는 AvgPool2d( ) 함수를 사용해 평균 풀링을 적용했 습니다. 최댓값이든, 평균값이든 정보 손실은 발생 합니다만 평균값은 풀링의 커널 안에 포함되는 모든 픽셀의 정보를 담을 수 있기 때문에 최댓값보다 조 금은 유리합니다. ▼ 새로 등장한 함수 커널의 평균값을 이용해 이미지를 풀링하는 것을 말합니다. 최대 풀링(max pooling)과 다르게 커 널의 모든 값을 고려한다는 장점이 있습니다. 함수 원형 설명 AvgPool2d(kernel_size, stride) 제공 라이브러리 풀링을 커널의 평균값으로 실행합니다. stride만큼의 보 폭을 갖습니다. nn 3 마지막으로 분류기를 정의합니다. 일반적으로 분류기는 MLP층을 3개 사용합니다. 다음으로 모델의 순전파를 정의하겠습니다.
평균 폴링(average pooling)
커널의 평균값을 이용해 이미지를 풀링하는 것을 말합니다. 최대 풀링(max pooling)과 다르게 커 널의 모든 값을 고려한다는 장점이 있습니다.
AvgPool2d(kernal_size, stride) : 풀링을 커널의 평균값으로 실행합니다. stride만큼의 보폭을 갖습니다.
3.
마지막으로 분류기를 정의합니다. 일반적으로는 분류기는 MLP 층을 3개 사용합니다.
다음으로 모델의 순전파를 정의하겠습니다.
def forward(self, x):
# 1) 기본 블록과 풀링층 통과
x = self.b1(x)
x = self.pool(x)
x = self.b2(x)
x = self.pool(x)
x = self.b3(x)
x = self.pool(x)
# 2) 분류기의 입력으로 사용하기 위한 평탄화
x = torch.flatten(x, start_dim=1)
# 3) 분류기로 예측값 출력
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x
Python
복사
순 전파 는 4 장 에서 사용한 코드 와 다른 점이 크게 없습니다 .
1.
기본 블록 과 풀링 층 을 번갈아 가며 통과 시킵니다 . 풀링 층 을 한 번 통과 할 때 마다 이미지 의 가로 세로 길이 가 절반 으로 줄어 듭니다 .
2.
분류기 의 MLP 층 은 1 차원 벡터 만을 입력 으로 하므로 2 차원 이미지 를 1 차원 벡터 로 변환 해 줍 시다 .
3.
마지막 으로 분류기 의 출력 을 내 보내면 완성 입니다 .
모델 학습하기
이번에도 학습 에 CIFAR - 10 데이터 셋 을 사용 합니다 . 학습 에 이용하는 코드 는 대부분 4 장 과 비슷 합니다 . 이전 과 다른 코드 만 설명 하겠습니다 .
먼저 데이터 전처리 를 정의 하겠습니다 . 이번에 사용할 전처리 기법 은 랜덤 크롭 핑 과 랜덤 y 축 대 칭 입니다 .
import tqdm
from torch.optim.adam import Adam
from torch.utils.data.dataloader import DataLoader
from torchvision.datasets.cifar import CIFAR10
from torchvision.transforms import (
Compose,
Normalize,
RandomCrop,
RandomHorizontalFlip,
ToTensor,
)
transforms = Compose(
[
RandomCrop((32, 32), padding=4), # 랜덤 크롭
RandomHorizontalFlip(p=0.5), # 랜덤 y축 대칭(수평 뒤집기)
ToTensor(),
Normalize(
mean=(0.4914, 0.4822, 0.4465),
std=(0.247, 0.243, 0.261),
),
]
)
Python
복사
랜덤 크롭핑과 랜덤하게 y축 대칭한 뒤, 이미지를 정규화 해줍니다.
다음으로 데이터를 불러오겠습니다.
# 데이터셋 정의
training_data = CIFAR10(
root="./",
train=True,
download=True,
transform=transforms,
)
test_data = CIFAR10(
root="./",
train=False,
download=True,
transform=transforms,
)
# 데이터 로더 정의
train_loader = DataLoader(training_data, batch_size=32, shuffle=True)
test_loader = DataLoader(test_data, batch_size=32, shuffle=False)
Python
복사
배치 단위를 32로 정하고 학습용 데이터와 평가용 데이터를 불러오는 데이터로더를 만들어줍니다.
다음으로 모델을 정의하고 학습할 프로세서를 정의합니다.
device = "cuda" if torch.cuda.is_available() else "cpu"
model = ResNet(num_classes=10)
model.to(device)
Python
복사
이어서 학습 루프와 학습률, 최적화를 정의하겠습니다.
lr = 1e-4
optim = Adam(model.parameters(), lr=lr)
for epoch in range(30):
iterator = tqdm.tqdm(train_loader)
for data, label in iterator:
# 1) 최적화를 위해 기울기를 초기화
optim.zero_grad()
# 2) 모델의 예측값
preds = model(data.to(device))
# 3) 손실 계산 및 역전파
loss = nn.CrossEntropyLoss()(preds, label.to(device))
loss.backward()
optim.step()
iterator.set_description(f"epoch:{epoch+1} loss:{loss.item()}")
# 학습된 모델 저장
torch.save(model.state_dict(), "ResNet.pth")
Python
복사
최적화를 위해 기울기를 초기화해주고, 모델의 예측값을 불러온 다음, 손실을 계산하고 역전파합니다.
모델의 성능 평가하기
model.load_state_dict(torch.load("ResNet.pth", map_location=device))
num_corr = 0
with torch.no_grad():
for data, label in test_loader:
output = model(data.to(device))
preds = output.data.max(1)[1]
corr = preds.eq(label.to(device).data).sum().item()
num_corr += corr
print(f"Accuracy: {num_corr / len(test_data)}")
Python
복사
출력 → Accuracy : 0.8822
앞에서 만든 기본 CNN 모델 은 정확도 가 약 83 % 정도 였습니다 . 앞 절 에서는 100 번 정 도 반복 해서 학습 했지만 30 번 정도 학습 한 ResNet 의 성능 이 더 좋습니다 . 이처럼 딥 러닝 에서는 학습률 , 반복 횟수 같이 미세한 조정 보다는 성능 이 좋은 모델 을 선택 하는 게 더 나은 방법 입니다 . 반면 사전 학습 된 VGG 모델 은 정확도 가 92.7 % 입니다 . ResNet 의 구조 가 아무리 뛰어 나더라 도 사전 학습 된 모델 을 전이 학습 하는 게 성능 이 더 좋습니다 . 물론 충분한 양 을 학습 한다 면 ResNet 이 더 좋은 결과 를 보이 겠지만 , 전이 학습 을 최대한 이용하는 게 효율적 으로 딥 러닝 모 델 을 학습 할 수 있는 방법 입니다 .
이번장에서는 ResNet을 알아봤습니다. ResNet은 기존의 CNN과 다르게 스킵커넥션을 이용해 신경망의 깊이를 크게 늘릴 수 있습니다ㅏ. 배치 정규화는 배치간의 차이를 줄이는 기법으로 학습을 조금 더 안정되게 하는 역할을 합니다.