

C++ 중첩 반복문, 정렬 알고리즘, 문자열 배열
이중 while문
중첩 반복문의 개념
2중 for문과 마찬가지로 2중 while문도 사용이 가능합니다. 자주 사용되지는 않지만 연습삼아 한번쯤도 따라치고 디버깅을 해보자!
#include <iostream>
using namespace std;
int main()
{
int y = 0;
while (y < 10)
{
cout << "Hello World" << endl;
int x = 0;
while (x < 10)
{
cout << "Hello World" << endl;
x++;
}
y++;
}
return 0;
}
C++
복사
중첩 while문의 특징:
•
외부 루프: y가 0부터 9까지 10번 반복
•
내부 루프: 각 y마다 x가 0부터 9까지 10번 반복
•
총 실행 횟수: 외부(10번) × 내부(10번) = 100번의 "Hello World" 출력
•
변수 초기화: 내부 루프 변수(x)는 외부 루프가 한 번 돌 때마다 다시 초기화
실행 흐름:
1.
y=0일 때: "Hello World" 1번 + 내부 루프 10번 = 총 11번 출력
2.
y=1일 때: "Hello World" 1번 + 내부 루프 10번 = 총 11번 출력
3.
... (y=9까지 반복)
버블 정렬 (Bubble Sort)
버블 정렬의 원리
버블 정렬은 인접한 두 원소를 비교하여 순서가 잘못되어 있으면 서로 교환하는 정렬 알고리즘입니다. 마치 물속의 거품(bubble)이 위로 올라오는 것처럼 큰 값이 배열의 끝으로 이동한다고 해서 버블 정렬이라고 합니다.
버블 정렬 단계별 분석
알고리즘 동작 과정:

1차 순회 (i=0):
•
j=0: [1, 10, 5, 8, 7, 6] → 1 < 10 (교환X)
•
j=1: [1, 10, 5, 8, 7, 6] → 10 > 5 (교환O) → [1, 5, 10, 8, 7, 6]
•
j=2: [1, 5, 10, 8, 7, 6] → 10 > 8 (교환O) → [1, 5, 8, 10, 7, 6]
•
j=3: [1, 5, 8, 10, 7, 6] → 10 > 7 (교환O) → [1, 5, 8, 7, 10, 6]
•
j=4: [1, 5, 8, 7, 10, 6] → 10 > 6 (교환O) → [1, 5, 8, 7, 6, 10]
결과: 가장 큰 값(10)이 맨 뒤로 이동
핵심 포인트:
•
외부 루프(i): 정렬된 원소의 개수를 추적
•
내부 루프(j): 실제 비교와 교환을 수행
•
범위 감소: j < 5 - i로 이미 정렬된 뒷부분은 제외
•
교환 조건: arr[j] > arr[j + 1]일 때 오름차순 정렬
버블 정렬 구현
#include <iostream>
using namespace std;
int main()
{
// bubble sort
int arr[6] = { 1, 10, 5, 8, 7, 6 };
for (int i = 0; i < 6; i++)
{
for (int j = 0; j < 5 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
return 0;
}
C++
복사
선택 정렬 (Selection Sort)

선택 정렬의 원리
선택 정렬은 배열에서 최소값을 찾아 맨 앞과 교환하는 과정을 반복하는 알고리즘입니다. 매번 남은 원소 중에서 가장 작은 값을 "선택"한다고 해서 선택 정렬이라고 합니다.
선택 정렬 구현
#include <iostream>
using namespace std;
int main()
{
int arr[6] = { 5, 3, 6, 2, 1, 8 };
for (int y = 0; y < 6; y++)
{
for (int x = y + 1; x < 6; x++)
{
if (arr[y] > arr[x])
{
int temp = arr[y];
arr[y] = arr[x];
arr[x] = temp;
}
}
}
return 0;
}
C++
복사
삽입 정렬 (Insertion Sort)

삽입 정렬의 원리
삽입 정렬은 배열의 각 원소를 이미 정렬된 부분과 비교하여 적절한 위치에 삽입하는 알고리즘입니다. 마치 카드를 한 장씩 받아서 손에 든 카드들 사이의 올바른 위치에 끼워 넣는 것과 같습니다.
삽입 정렬 구현
#include<stdio.h>
using namespace std;
int main()
{
// 삽입정렬
int arr[6] = { 5,3,8,1,2,7 };
for (int i = 1; i < 6; i++)
{
int temp = arr[i];
int j = 0;
for (j = i - 1; j >= 0; j--)
{
if (arr[j] > temp)
arr[j + 1] = arr[j];
else
break;
}
arr[j + 1] = temp;
}
return 0;
}
C++
복사
선택 정렬 vs 버블 정렬 vs 삽입 정렬 비교
특징 | 버블 정렬 | 선택 정렬 | 삽입 정렬 |
비교 방식 | 인접한 원소끼리 비교 | 현재 위치와 나머지 모든 원소 비교 | 정렬된 부분과 현재 원소 비교 |
교환 빈도 | 조건 만족시마다 교환 | 한 번의 순회당 최대 1번 교환 | 적절한 위치를 찾을 때까지 이동 |
내부 루프 | j < 5 - i | x = y + 1; x < 6 | x = y - 1; x >= 0; |
정렬 결과 | 큰 값이 뒤로 이동 | 작은 값이 앞으로 이동 | 현재 값을 올바른 위치에 삽입 |
정렬 알고리즘 장단점 비교
특징 | 버블 정렬 | 선택 정렬 | 삽입 정렬 |
시간 복잡도 (평균) | O(n²) | O(n²) | O(n²) |
시간 복잡도 (최선) | O(n) - 이미 정렬된 경우 | O(n²) - 항상 동일 | O(n) - 이미 정렬된 경우 |
시간 복잡도 (최악) | O(n²) | O(n²) | O(n²) |
공간 복잡도 | O(1) - 추가 메모리 불필요 | O(1) - 추가 메모리 불필요 | O(1) - 추가 메모리 불필요 |
안정성 (Stable) |  안정 정렬 안정 정렬 | 불안정 정렬 | 안정 정렬 |
교환 횟수 | 많음 (최대 n²/2) | 적음 (최대 n) | 중간 (데이터에 따라 다름) |
비교 횟수 | 많음 (항상 n²/2) | 많음 (항상 n²/2) | 적음~많음 (데이터에 따라 다름) |
각 알고리즘의 장점
버블 정렬의 장점:
•
구현이 매우 간단하고 직관적
•
이미 정렬된 배열에서는 O(n)으로 빠르게 동작 가능 (최적화 시)
•
안정 정렬 - 같은 값의 순서가 유지됨
•
추가 메모리 공간 불필요
선택 정렬의 장점:
•
교환 횟수가 적어 교환 비용이 큰 경우 유리
•
구현이 간단
•
메모리 사용량이 최소
•
데이터의 상태와 무관하게 일관된 성능
삽입 정렬의 장점:
•
거의 정렬된 데이터에서 매우 효율적 (O(n))
•
온라인 알고리즘 - 데이터를 하나씩 받으면서 정렬 가능
•
안정 정렬 - 같은 값의 순서가 유지됨
•
작은 데이터셋에서 다른 복잡한 알고리즘보다 빠름
•
적응적(Adaptive) - 데이터 상태에 따라 성능이 향상됨
각 알고리즘의 단점
버블 정렬의 단점:
•
비교와 교환이 모두 많아 비효율적
•
큰 데이터셋에서 매우 느림
•
실무에서 거의 사용되지 않음
선택 정렬의 단점:
•
데이터가 이미 정렬되어 있어도 O(n²) 시간 소요
•
불안정 정렬 - 같은 값의 순서가 바뀔 수 있음
•
큰 데이터셋에서 비효율적
•
비교 횟수가 항상 많음
삽입 정렬의 단점:
•
역순 정렬된 데이터에서 최악의 성능 (O(n²))
•
큰 데이터셋에서는 비효율적
•
배열 크기가 클수록 성능 저하가 심함
여러 문장 입력받기
다차원 문자 배열 (2차원 char 배열)
C++에서 여러 개의 문자열을 저장하려면 2차원 char 배열을 사용합니다. 각 행이 하나의 문자열을 나타내며, 각 문자열은 null 문자(\0)로 끝납니다.
#include <iostream>
using namespace std;
int main()
{
char str[3][256] = {};
// 첫번째 문장 입력
cin >> str[0]; /*&str[0][0]*/
// 두번째 문장 입력
cin >> str[1]; /*&str[1][0]*/
// 세번째 문장 입력
cin >> str[2]; /*&str[2][0]*/
return 0;
}
C++
복사
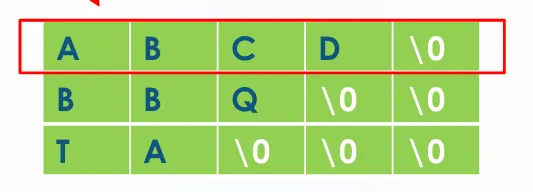
2차원 배열에서의 주소값 (참고)
str[0]의미는 배열 첫 번째 줄의 주소
2차원 char 배열에서 각 행의 이름은 해당 행의 첫 번째 문자의 주소를 나타냅니다.
메모리 구조:
str[0]: A B C D \0 □ □ ... (256개 문자 공간)
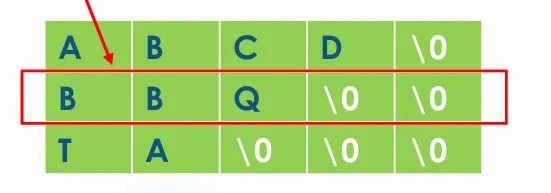
str[1]: B B Q \0 \0 □ □ ... (256개 문자 공간)
str[2]: T A \0 \0 \0 □ □ ... (256개 문자 공간)
Plain Text
복사
주소 관계:
•
str[0] = &str[0][0] (첫 번째 행의 시작 주소)
•
str[1] = &str[1][0] (두 번째 행의 시작 주소)
•
str[2] = &str[2][0] (세 번째 행의 시작 주소)
문자열 출력하기
#include <iostream>
using namespace std;
int main()
{
char str[3][256] = {};
// 문자열 입력 (공백 없는 단어만 가능)
cin >> str[0];
cin >> str[1];
cin >> str[2];
// 첫번째 문장 출력
cout << str[0] << endl;
// 두번째 문장 출력
cout << str[1] << endl;
// 세번째 문장 출력
cout << str[2] << endl;
return 0;
}
C++
복사
문자열 입력의 한계와 해결책
cin >> 의 한계:
•
공백(스페이스)을 만나면 입력이 끝남
•
"Hello World"를 입력하면 "Hello"만 저장됨
공백이 포함된 문자열 입력:
// getline 사용 (권장)
string str;
getline(cin, str);
// cin.getline 사용
char str[256];
cin.getline(str, 256);
C++
복사
실무에서의 활용:
•
게임: 플레이어 이름, 채팅 메시지 저장
•
시스템: 설정 파일의 여러 옵션값 저장
•
데이터베이스: 여러 레코드의 텍스트 필드 저장
2차원배열에서의 주소값(참고)
“str[0]”의미는 배열 첫 번째 줄의 주소
“str[1]”의미는 배열 두 번째 줄의 주소
“강의는 많은데, 왜 나는 아직도 코드를 못 짤까?”
혼자 공부하다 보면 누구나 이런 고민을 하게 됩니다.
•
강의는 다 들었지만 막상 손이 안 움직이고,
•
복습을 하려 해도 무엇을 다시 봐야 할지 모르겠고,
•
질문할 곳도 없고,
•
유튜브는 결국 정답을 따라 치는 것밖에 안 되는 것 같고.
문제는 ‘연습’이 빠졌기 때문입니다.
단순히 강의를 듣는 것만으로는 실력이 늘지 않습니다.
실제 문제를 풀고, 고민하고, 직접 구현해보는 시간이 반드시 필요합니다.
그래서, 얌얌코딩 코칭은 다릅니다.
그냥 가르치지 않습니다.
스스로 설계하고, 코딩할 수 있게 만듭니다.
얌얌코딩 코칭에서는 단순한 예제가 아닌,
스스로 문제를 분석하고 구현해야 하는 연습문제를 제공합니다.
이 연습문제들은 다음과 같은 역량을 키우기 위해 설계되어 있습니다:
•
문제를 스스로 쪼개고 설계하는 힘
•
다양한 조건을 만족시키는 실제 구현 능력
•
기능 단위가 아닌, 프로그램 단위로 사고하는 습관
•
마침내 자신의 힘으로 코드를 끝까지 작성하는 경험
지금 필요한 건 더 많은 강의가 아닙니다.
코드를 스스로 완성해 나가는 훈련,
그것이 지금 실력을 끌어올릴 가장 현실적인 방법입니다.
자세한 안내 보기: 프리미엄 코칭 안내 바로가기 또는 카카오톡 상담방: 얌얌코딩 상담방