





그림 1
이전에는 오프라인 렌더링에서만 가능했던 복잡한 외관을 가진 장면을 실시간으로 렌더링할 수 있는 완전한 시스템을 제안합니다.
이 시스템은 알고리즘적 혁신과 시스템 수준의 혁신을 결합하여 구현했습니다.
우리의 외관 모델(appearance model)은 학습된 계층적 텍스처(hierarchical textures)를 활용하며, 이 텍스처는 신경망 디코더(neural decoders)가 해석합니다. 디코더는 반사율(reflectance) 값과 중요도 샘플링된 방향(importance-sampled directions)을 생성합니다.
디코더의 모델링 용량을 최대화하기 위해, 두 가지 그래픽스 사전(prior)을 적용했습니다.
•
첫 번째 사전: 학습된 셰이딩 프레임(shading frames)으로 방향을 변환하여 중간 규모 효과(mesoscale effects)를 정확히 재구성합니다.
•
두 번째 사전: 마이크로패싯 샘플링 분포(microfacet sampling distribution)를 통해 신경망 디코더가 효율적으로 중요도 샘플링을 수행합니다.
이렇게 개발된 외관 모델은 비등방(anisotropic) 샘플링, 레벨 오브 디테일 렌더링, 그리고 깊게 계층화된 머티리얼 그래프를 압축된 단일 신경 표현(neural representation)으로 베이킹을 지원합니다.
또한, 레이 트레이싱 셰이더(ray tracing shaders)에 하드웨어 가속 텐서 연산을 직접 노출시켜 신경망 디코더를 실시간 경로 추적기(path tracer) 내에서 효율적으로 인라인 실행할 수 있음을 증명했습니다.
신경 머티리얼 수가 증가할 때의 확장성(scalability)을 분석하고, 일관적(coherent) 및 비일관적(divergent) 실행 코드 최적화를 통해 성능을 향상시킬 수 있습니다. 우리의 신경 머티리얼 셰이더는 비신경 기반 계층적 머티리얼보다 10배 이상 빠른 속도를 제공합니다.
이 연구는 게임이나 실시간 미리보기와 같은 애플리케이션에서 영화 품질의 비주얼(film-quality visuals)을 실시간으로 구현하는 길을 열어줍니다.

그림2 - 여러분께 [Jakob et al. 2019]와 비슷한 레이어링 방식으로 만든 다섯 가지 멋진 기준 재질의 렌더링 이미지를 보여드립니다! 이 재질들은 BRDF 표현과 중요도 샘플링을 위해 신경망 모델로 근사했어요. 각 객체는 복잡한 반사 특성과 고해상도 텍스처 때문에 실시간 렌더러에게 꽤 까다로운 도전이 되죠(자세한 내용은 표 1을 살펴보세요). 이 재질에 해당하는 셰이딩 그래프는 보충 자료에서 확인하실 수 있답니다.
1. INTRODUCTON
최근 렌더링 알고리즘, 광선 전달 기법, 레이 트레이싱 하드웨어의 발전으로 실시간으로 구현 가능한 이미지 품질의 한계가 크게 높아졌습니다. 그러나 실시간 재질(material) 모델의 발전은 상대적으로 더디게 진행되고 있습니다. 오프라인 렌더링에서는 깊이 있는 다층 재질(layered material)과 정교한 셰이딩 그래프가 일반적이지만, 이러한 접근법은 실시간 환경에서는 계산 비용이 너무 커서 적용하기 어렵습니다.
계산량 외에도 복잡한 재질은 중요도 샘플링과 필터링에서 추가적인 문제를 일으킵니다. 세밀한 재질은 축소 과정에서 심각한 앨리어싱(aliasing)을 발생시키며, 다층 재질의 복잡한 다중 로브(multi-lobe) 반사 특성은 제대로 샘플링되지 않으면 높은 분산(variance)을 초래합니다.
최근 연구들[Kuznetsov et al. 2022; Sztrajman et al. 2021; Zheng et al. 2021]은 다층 퍼셉트론(MLP)이 외관 모델링, 중요도 샘플링, 필터링에 효과적인 도구가 될 수 있음을 보여주었습니다. 그러나 이러한 모델들은 영화 수준의 사실적인 외관을 지원하지 못하며, 실시간 환경에서 고품질 시각 효과를 제공할 수 있는 확장 가능한 해결책은 아직 제시되지 않았습니다.
본 논문의 목표는 바로 여기에 있습니다. 영화 및 VFX 산업에서 사용되는 고품질 재질(예시는 그림 2, 통계는 표 1 참조)을 실시간으로 렌더링하는 것입니다. 이들 재질은 사실성과 시각적 충실도를 최우선으로 하며, 매우 고해상도 텍스처에 크게 의존합니다. 또한 범용 셰이더(ubershader)가 아닌 반사 성분의 레이어링을 통해 재질 외관을 구성하여, 수십 개의 파라미터를 가진 다양한 BRDF 조합을 가능하게 합니다. 이러한 재질을 단순한 해석적 모델로 근사하는 것은 부정확하며(그림 3 참조), 따라서 이를 실시간 애플리케이션에 구현하는 일은 매우 어려운 과제입니다.
이를 위해 본 연구에서는 i) 기존 연구의 효과적인 요소를 선별적으로 활용하고, ii) 새로운 알고리즘적 혁신을 도입하며, iii) 신경망을 고전적 래스터라이제이션과 경로 추적 모두에서 렌더링 루프의 최심부(inner loop)에 효율적으로 통합할 수 있는 확장 가능한 방안을 제안합니다.
또한 우리는 성능을 위해 편집 가능성을 과감히 포기하고, 대신 아티스트가 편집을 마친 재질을 신경망이 해석 가능한 뉴럴 텍스처(Neural Texture)로 '베이킹(baking)'하는 방식을 취합니다. 본 연구의 모델은 빠른 렌더링을 위한 최적화된 표현으로, 편집 이후 최적화 과정을 통해 베이킹됩니다.
영화 수준의 외관을 실시간으로 렌더링하기 위해, i) 기존 연구에서 필요한 요소를 선별적으로 활용하고,
ii) 새로운 알고리즘적 혁신을 도입하며, iii) 신경망을 고전적 래스터라이제이션과 경로 추적 모두의 렌더링 루프 최심부(inner loop)에 효율적으로 통합할 수 있는 확장 가능한 해법을 개발했습니다.
성능 최적화를 위해 편집 가능성을 과감히 포기하고, 참조 재질을 신경망이 해석하는 뉴럴 텍스처로 '베이킹(baking)'합니다. 이 모델은 빠른 렌더링을 위한 최적화된 표현으로, 편집 완료 후 최적화 과정을 통해 베이킹됩니다.
우리의 모델은 인코더(encoder)와 두 개의 디코더(decoder)로 구성되며, 이들 사이에 신경망 기반 잠재(Neural Latent) 텍스처가 위치합니다. 인코더는 BRDF 파라미터를 매핑합니다.
표 1. 그림 2에 제시된 참조 재질의 통계. 셰이딩 그래프의 셰이딩 노드(a)는 프로그래밍적으로 다수의 BRDF 레이어(b)로 변환되며, 이는 파라미터(c)로 제어됩니다. 이러한 파라미터는 RGB 텍스처를 통해 공간적으로 변화하고(괄호 안은 사용된 총 채널 수)(d), 최종적으로 사용된 RGB 메가텍셀 수는 (e) 열에 표시됩니다.
재질 | 노드(a) | 레이어(b) | 파라미터(c) | 텍스처(d) | MTexels(e) |
Teapot ceramic | 37 | 5 | 121 | 5 (11) | 1174 |
Teapot handle | 41 | 2 | 91 | 11 (19) | 152 |
Slicer handle | 20 | 5 | 43 | 3 (7) | 201 |
Slicer blade | 54 | 3 | 114 | 16 (40) | 324 |
Inkwell | 49 | 5 | 143 | 4 (11) | 201 |
모델은 인코더 → (잠재 뉴럴 텍스처) → 2개의 디코더로 구성됩니다.
인코더는 복잡한 BRDF 파라미터(러프니스, 금속성, 굴절 등)를 컴팩트한 뉴럴 표현(잠재 공간)으로 변환합니다.
디코더들은 이 잠재 표현을 다시 렌더링에 필요한 값(반사율, 샘플링 분포 등)으로 해석합니다. 영화 제작용 재질 그래프는 매우 복잡하며 파라미터가 수십~수백 개에 달합니다.
이러한 재질을 실시간으로 계속 편집 가능하게 유지하면 성능이 심각하게 저하되므로,
아티스트가 편집을 완료한 후 → 뉴럴 텍스처로 '베이킹(bake)' → 실시간 엔진에서 빠르게 활용하는 방식을 채택했습니다.
즉, 런타임에서는 "재질을 계산하는 것"이 아니라 "이미 학습된 함수로 재질을 빠르게 조회"하는 것입니다.
표 1의 의의: 각 재질의 복잡성을 수치로 보여주는 자료입니다.
예시: Inkwell은 49개의 노드, 5개의 BRDF 레이어, 143개 파라미터, 4장의 텍스처(총 11채널), 약 201 메가텍셀로 구성됩니다. 이는 전통적인 방식으로는 실시간 렌더링이 불가능할 정도로 복잡하다는 점을 수치로 강조합니다. 이러한 복잡성을 뉴럴 모델로 압축함으로써, 동일한 시각적 품질을 훨씬 효율적으로 렌더링할 수 있음을 입증합니다.

그림3 - 앞의 두 열은 그림 2의 다층 티포트(Teapot) 재질을 단순 해석적 BRDF로 근사한 결과입니다. 이 모델은 총 8개의 공간적으로 변화하는 입력 채널만 사용합니다: 베이스 컬러(3), 스펙큘러 러프니스(1), 스펙큘러 노멀 맵(2), 스펙큘러리티(1), 메탈니스(1). 세 번째 열은 8채널 잠재 텍스처로 파라미터화된 우리의 뉴럴 BRDF 결과입니다. FLIP 시각화는 참조 이미지(마지막 열, 그림 2 및 표 1)와의 지각적 차이를 보여줍니다. 해석적 BRDF의 파라미터는 수치적으로 최적화되거나 수동으로 조정되었으나, 두 경우 모두 참조의 복잡성을 포착할 표현력이 부족해 더 큰 근사 오차가 발생합니다. 특히 도자기 유약(ceramic glazing)의 시점에 따른 파란색 변화(color shift)를 제대로 재현하지 못합니다.
우리의 신경망 기반 모델은 재질의 복잡성과 무관하게 평가 비용이 일정하므로, 복잡한 머티리얼도 실시간 패스 트레이서에서 렌더링할 수 있습니다. 이를 위해 (그림 2와 같은) 레이어드 머티리얼을 적용한 고정밀 자산을 제작했으며, 이는 10 cm 관찰 거리에서도 또렷한 디테일을 제공합니다. 나아가 이러한 고난도 자산의 시각적 충실도를 그대로 재현하면서도, 기존의(적정 수준으로 최적화된) 셰이딩 모델 대비 셰이딩 속도가 최대 10배 빠르고, 샘플링·필터링 기능(그림 1)까지 추가로 제공합니다.
실시간 프레임 속도에서 높은 시각적 충실도를 달성하기 위해 뉴럴 모델과 시스템 차원 모두의 혁신이 필요했습니다. 구체적인 혁신 사항은 다음과 같습니다.
•
필름 퀄리티 뉴럴 머티리얼을 위한 완전하고 확장 가능한 시스템
•
인코더를 이용한 기가텍셀급 자산에 대한 실용적 학습(tracable training)
•
노멀 매핑과 샘플링을 위한 프라이어(prior)를 포함한 디코더
•
실시간 셰이더에서의 신경망 효율적 실행
우리는 모델과 시스템이 함께 발전해야 뉴럴 셰이더의 실시간 구현이 가능하다고 보며, 이를 뒷받침하기 위해 본 시스템을 견고한 기반으로 설계하였다.
2. RELATED WORK
이 절에서는 신경망 기반 재질 표현, 필터링, 샘플링과 관련된 선행 연구를 검토하며, 고전적인 재질 모델에 대한 자세한 개요는 “Physically Based Rendering: From Theory to Implementation” (3rd Edition, 2016)을 참고한다.
2.1 Nerual appearance modeling
우리는 기존 재질을 신경망 기반으로 표현하고, 이를 기하학(classical geometry) 위에서 실시간 렌더링하는데 집중한다. 따라서 ray marching 기반의 신경 필드 (ray marched nerual fields)[Baatz et al. 2022; Mildenhall et al. 2020; Müller et al. 2022] 는 사용하지 않으며, 이러한 방법은 향후 유효한 대안이 될 수 있다.
우리의 연구 목표는 일반적으로 Neural BRDFs [Fan et al. 2022; Kuznetsov et al. 2019, 2021; Rainer et al. 2020, 2019; Sztrajman et al. 2021; Zheng et al. 2021] 과 비슷하다. 이러한 방법들의 공통점은 신경망을 Pair of direction(빛이 들어오는 방향, 카메라나 눈으로 가는 방향)을 조건으로 넣어서 연구 한다. 선택적으로 훈련된 Latent code 를 사용하는 것이다. 이러한 Latent code는 텍스처에 저장되며 [Thies et al. 2019], 고전적인 UV 매핑(classical UV mapping) 을 통해 샘플링되어 공간적으로 변화하는 BRDFs 를 지원한다.
Latent texture 를 얻기 위해서 Kuznetsov et al. [2019]의 NeuMIP 연구에서는 무작위로 초기화된 잠재 텍스처를 역전파를 통해 직접 최적화(direct optimization)하는 방식을 사용한다. 이는 단순하지만 수백만 개의 텍셀을 가진 대규모 텍스처에서는 비용이 많이 든다. 반대로, Rainer et al. [2019]는 오토인코더(auto-encoder) 아키텍처에 의존하여 일련의 반사율 측정값을 잠재 코드로 인코딩한다.
Kuznetsov et al. [2019]의 NeuMIP 연구에서는 무작위로 초기화된 잠재 텍스처를 역전파를 통해 직접 최적화(direct optimization)하는 방식을 사용한다. 이는 단순하지만 수백만 개의 텍셀을 가진 대규모 텍스처에서는 비용이 많이 든다. 반대로, Rainer et al. [2019]는 오토인코더(auto-encoder) 아키텍처에 의존하여 일련의 반사율 측정값을 잠재 코드로 인코딩한다.
우리는 하이브리드 접근 방식을 취한다: 먼저 인코더를 학습시키고, 학습 도중에 이를 사용해 계층적 잠재 텍스처(hierarchical latent texture)를 생성한 후, 이를 직접 최적화를 통해 미세 조정(finetune)한다. 이 접근법은 인코더-디코더 아키텍처의 속도와 직접 최적화의 유연성을 결합한 것이다. Rainer et al. [2019]와 달리, 우리는 반사율 측정값을 인코딩하지 않고, 해당 재질 파라미터 집합(albedo, roughness, normal 등)을 인코딩한다.
Zheng et al. [2021]과 Sztrajman et al. [2021]은 입력 방향(input directions)을 반각 좌표계(half-angle coordinate system) [Rusinkiewicz 1998]로 재파라미터화하였다. 이러한 특정 인코딩은 우리의 경우에는 큰 이점을 제공하지 않았지만, 우리는 이러한 원리를 활용하여 새로운 그래픽스 사전 지식, 즉 신경망이 학습한 셰이딩 좌표계로의 회전을 도입하였으며, 이를 통해 노멀 맵과 여러 겹으로 이루어진 재질을 보다 효과적으로 처리할 수 있도록 하였다.
Fan et al. [2022]은 학습 세트에 포함되지 않은 새로운 BRDF도 잠재 코드(layered latents) 를 층층이 쌓는 방식으로 렌더링할 수 있었다. 하지만 이 방법은 실시간 처리에는 적합하지 않은 대규모 신경망을 필요로 한다.
우리는 작은 규모의 네트워크에 집중하며, 학습 시 사용된 재질만 렌더링하고 일반화는 추구하지 않는다. 대신, 여러 겹의 재질(layered materials) 은 각 층을 따로 표현하지 않고 모든 층의 결합 효과를 한 번에 포착하여 지원한다. 이렇게 함으로써 원래 재질의 명시적인 레이어 표현도, 신경망 컴포넌트의 추가적 레이어링도 피할 수 있다.
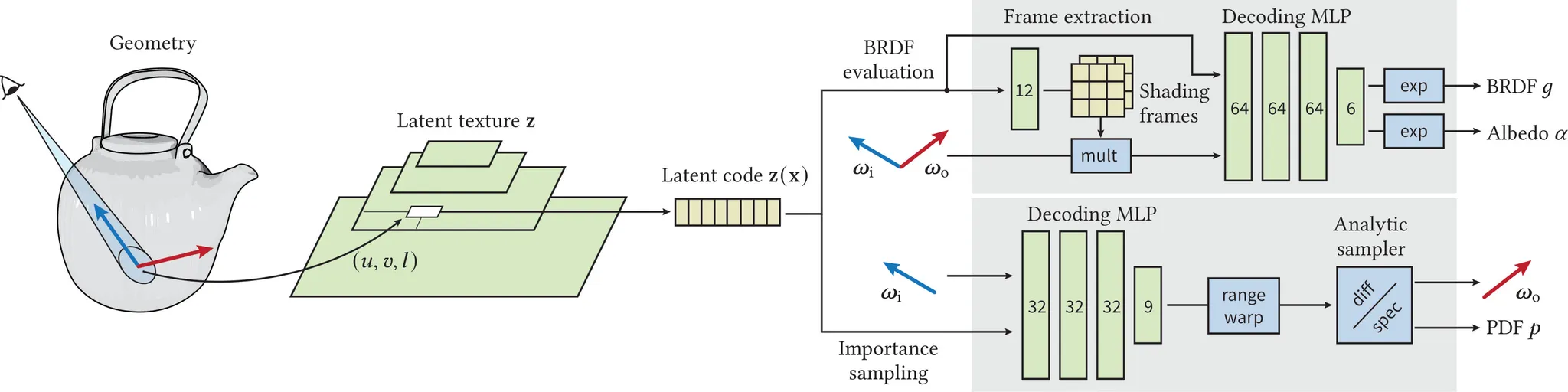
그림 4. 우리의 신경망 기반 BRDF는 다음과 같이 렌더러에서 사용된다. 광선(ray)이 신경망 BRDF가 적용된 표면에 도달하면, 먼저 표준적인 (u, v) 좌표와 MIP 레벨 ℓ을 계산한 뒤, 해당 재질의 잠재 텍스처(latent texture)를 조회한다. 이어서 잠재 코드 z(x)를 렌더링 알고리즘의 필요에 따라 하나 또는 두 개의 신경망 디코더에 입력한다. BRDF 디코더(위 상자): z(x)로부터 두 개의 셰이딩 프레임(shading frame)을 추출하고, 입사 방향 ωi와 출사 방향 ωo를 각각 이 프레임에 맞게 변환한다. 변환된 방향들과 z(x)는 다층 퍼셉트론(MLP)에 입력되어 BRDF 값을 예측하며, 필요에 따라 방향성 알베도(directional albedo)도 함께 출력한다. 중요도 샘플러(아래 상자): 분석적인 two-lobe 분포의 파라미터를 추출한 후, 이를 사용해 출사 방향 ωo를 샘플링하거나 확률밀도함수(PDF) p(x,ωi,ωo)를 평가한다. BRDF 디코더는 “빛의 세기”를 예측하고, Importance Sampler는 “어디로 빛을 추적해야 할지”를 알려줍니다.
왜 Importance Sampling이 필요한가?
2.2 Neural material filtering
셰이딩으로 인한 앨리어싱(aliasing)은 보통 밉매핑(mipmapping)으로 해결하지만, 선형 필터링(linear filtering) 시 외형이 크게 달라질 수 있는 비확산(non-diffuse) 재질에서는 특별한 주의가 필요하다. LEAN [Olano and Baker 2010], LEADR [Dupuy et al. 2013], MIPNet [Gauthier et al. 2022]과 같은 기법들은 통계적 방법이나 신경망 다운샘플링을 활용하여, 사전 필터링된 참조값(prefiltered ground truth)에 더 가깝게 맞춘다. 이러한 접근들이 기존 BRDF의 파라미터를 조정하는 방식인 반면, 우리는 신경망 모델과 계층적 텍스처(hierarchical textures)를 학습하여 필터링된 외형을 직접 표현한다. 이는 Kuznetsov et al. [2021]과 Bako et al. [2023]의 접근과 유사하나, 다른 보간(interpolation) 방식을 사용한다(자세한 내용은 4.1절 참고). 다만, 우리는 여전히 LEAN [Olano and Baker 2010]을 그래픽스 사전 지식(graphics prior)으로 활용하여 인코더의 입력을 필터링한다.
2.3 Neural material importance sampling
신경망 기반 재질의 중요도 샘플링에 관한 기존 연구는 다음 세 가지로 분류할 수 있다.
i) 분석적(analytical) 근사 분포를 사용하는 방법,
ii) 정규화 흐름(normalizing flows)을 활용하는 방법,
iii) 네트워크가 직접 샘플을 워핑(warping)하는 방법.
Neural material sampler에 대한 개요는 Xu et al. [2023]을 참고하라.
우리는 첫 번째 접근 방식을 사용한다. 즉, 신경망이 분석적 분포의 파라미터를 산출하는 방식이다. Sztrajman et al. [2021]과 Fan et al. [2022]이 Phong-Blinn 모델이나 등방성 가우시안(isotropic Gaussian)을 사용한 것과 달리, 우리는 표준 마이크로패싯(microfacet) 모델 [Trowbridge and Reitz 1975; Walter et al. 2007]을 활용한다. 마이크로패싯 모델은 (필터링된) 현실적인 재질에서 흔히 나타나는 비등방성(anisotropy) 을 더 잘 처리할 수 있다.
중요도 샘플링을 위한 정규화 흐름(normalizing flows) [Dinh et al. 2017; Müller et al. 2019]은 Zheng et al. [2021]이 처음으로 신경망 BRDF에 적용하였다. 충분히 큰 네트워크라면 복잡한 분포도 정확히 근사할 수 있지만, 우리는 런타임 성능이 비슷한 수준에서 분석적 근사(distribution proxy)의 품질을 따라잡는 데 어려움이 있었다.
세 번째 접근 방식은 Bai et al. [2023]이 최근 탐구한 것으로, 네트워크가 직접 샘플을 워핑하도록 하되 2D 최적 수송(optimal transport)으로 학습을 보조한다. 그러나 이 방법은 학습된 밀도가 워핑의 실제 야코비안 행렬식(Jacobian determinant)과 완전히 일치하지 않아, 편향(bias)이 무한정 커질 수 있는 단점이 있다. 따라서 우리는 물리 기반 렌더러와의 호환성을 유지하기 위해 이 방법은 제외하였다.
워핑(warping)이란?
3. OVERVIEW
우리의 목표는 빛과 물질의 상호작용에서 비롯되는 실제 재질의 외관을 재현하는 것이다.
이는 공간적으로 변하는 양방향 반사 분포 함수(SVBRDF) 로 표현된다.
이 함수는 입사 복사휘도 에 의해 발생하는 산란된 미소 출사 복사휘도 의 양을 정량화한다:
여기서 는 표면의 한 점이고, 는 각각 입사 및 출사 방향이다.
SVBRDF는 상반구 전체에 대해 적분함으로써 방향 알베도(directional albedo) 를 얻을 수 있다:
우리 모델은 위 두 가지 물리량(즉, SVBRDF와 방향 알베도)을 모두 표현한다(그림 4 참고). 우리는 이 모델을 기존(참조) SVBRDF의 최적화된 표현으로 설계하였다. 즉, 목표 재질가 주어졌을 때, 이를 가깝게 근사하는 함수 를 제공한다. 이 함수는 참조 재질을 충실히 근사하면서도 실시간(real-time) 으로 평가될 수 있다. 따라서 유용하기 위해서는, 우리 시스템은 여러 가지 성질들을 만족해야 한다.
시각적 충실도 (Visual fidelity)
우리의 주요 목표는 다층 재질(low-roughness 유전체 코팅, 반짝임(glints)이 있는 도체, 얼룩(stains), 이방성(anisotropy) 등 다양한 난이도의 재질을 충실하게 재현하는 것이다.
이는 공간적으로 균일한 측정 재질 데이터셋 [Dupuy and Jakob 2018; Matusik et al. 2003]에 단순히 맞추는 수준을 넘어, 고해상도 텍스처(4K 이상)와 정교한 노멀 맵을 가진 재질을 명시적으로 다루고자 한다.
레벨 오브 디테일 (Level of detail)
필터링되지 않은 고해상도 재질은 축소 렌더링 시 앨리어싱(aliasing) 이 발생하기 쉽고, 적절히 필터링된 반사율은 Pixel footprint 내에서 크게 달라질 수 있다.
따라서 우리는 낮은 샘플 수에서도 레벨 오브 디테일(LOD) 렌더링을 가능하게 하는 **필터링된 룩업(filtered lookup)**을 지원하고자 한다.
중요도 샘플링 (Importance sampling)
BRDF를 표현하는 것뿐 아니라, **몬테카를로 추정기(예: 경로 추적, path tracing)**에서 활용할 수 있는 효과적인 중요도 샘플링 전략도 필요하다.
여기에는 특히 어려운 문제 중 하나인 재질의 필터링된 버전에 대한 중요도 샘플링도 포함된다.
성능 (Performance)
우리의 뉴럴 표현(neural representation)은 실시간(real-time) 애플리케이션을 목표로 한다.
따라서 재질 평가(material evaluation)는 전체 프레임 시간의 일부만 사용해야 한다.
또한, 경로 추적(path tracing) 과의 호환성이 필요하다.
이는 재질이 여러 번의 반사(bounce)에 걸쳐 **임의의 위치(random locations)**에서 평가되기 때문이며, 이로 인해 큰 규모의 네트워크나 합성곱(convolution)에 의존하는 모델은 사용할 수 없다.
실용성 (Practicality)
뉴럴 재질 최적화는 오프라인 과정에서 이루어지지만, 고해상도 재질(4K 이상) 에 대해서도 학습 시간이 합리적이어야 한다.
훈련에 며칠이나 걸리는 것은 실용적이지 않으며, 시스템의 활용성을 떨어뜨린다.
우리의 주요 초점은 앞서 언급한 조건들을 충족하는 시스템을 개발하는 데 있다.
이전의 뉴럴 머티리얼 연구들과 마찬가지로, 우리는 에너지 보존(energy conservation) 과 상호성(reciprocity) 에 대한 명시적인 제약을 두지 않고, MLP(다층 퍼셉트론) 이 데이터로부터 이를 학습하도록 한다.
또한, 델타 성분(delta components) 을 포함하는 BRDF나 (거친) 굴절과 같은 특정 특수 케이스는 배제한다.
다만, 초기 실험에서는 우리 모델이 후자의 경우(거친 굴절)는 처리할 수 있음을 보여주었다.
4장과 5장에서는 뉴럴 모델의 아키텍처와 학습 절차를 설명한다.
이어 6장에서는 개별 구성 요소들에 대한 비교 분석을 다룬다.
실시간 성능이 우리의 주요 목표 중 하나이므로, 7장에서는 레이 트레이싱 셰이더 내부에서 뉴럴 모델을 효율적으로 평가하는 방법을 집중적으로 다룬다.
마지막으로 8장에서는 여러 난이도 높은 장면에서의 품질과 실행 성능(runtime performance) 을 시연하며 결론을 맺는다.
4. Neural BRDF Decoder
이 절에서는 그림 4에 제시된 우리의 외관 모델(appearance model) 아키텍처를 설명한다.
이 모델은 크게 두 가지 주요 구성 요소로 이루어져 있다:
1.
잠재 텍스처(latent texture)
2.
두 개의 뉴럴 디코더(neural decoders)
이 모든 구성 요소는 특정 재질(material)이나 여러 재질 집합을 표현하기 위해 공동으로 최적화(jointly optimized) 된다.
잠재 텍스처의 인코딩과 같은 최적화 절차의 세부 사항은 다음 절에서 다룬다.
잠재 텍스처(latent texture)는 재질의 공간적 변화를 표현하며, z라고 표기되는 8차원 코드로 구성된다.
쿼리 위치 x와 그에 대응하는 잠재 코드 z(x가 주어졌을 때, BRDF 값은 학습 가능한 파라미터 θ 를 가진 뉴럴 디코더 g에 의해 추론된다.
여기서 는 입사 방향과 출사 방향을 학습된 셰이딩 프레임(shading frames)으로 변환하는 행렬을 나타낸다.
다음으로 우리는 잠재 텍스처 의 성질에 대해 논의하고, 이어서 를 추출하는 절차를 설명한다.
4.1 잠재 텍스처 (Latent texture)
이전 연구들 [Kuznetsov et al. 2021; Thies et al. 2019]과 유사하게, 우리는 UV 매핑된 계층적 텍스처(hierarchical texture) 안에 잠재 코드를 저장한다.
여기서 각 텍셀(texel)은 주어진 공간적 위치와 스케일에서의 객체 외관을 나타낸다.
원본 재질의 충실도(fidelity)를 유지하기 위해, 가장 세밀한 수준의 해상도를 원본 재질 텍스처의 해상도와 동일하게 설정한다. 또한, UV 파라미터화를 활용하여 원래의 텍셀 밀도를 보존한다.
고해상도 재질은 축소(minification) 렌더링 시 심각한 앨리어싱(aliasing) 을 일으킬 수 있다(그림 5, (a)와 (b)의 왼쪽 열) 기본적으로, 우리의 뉴럴 디코더 역시 이러한 앨리어싱을 그대로 재현하게 된다.
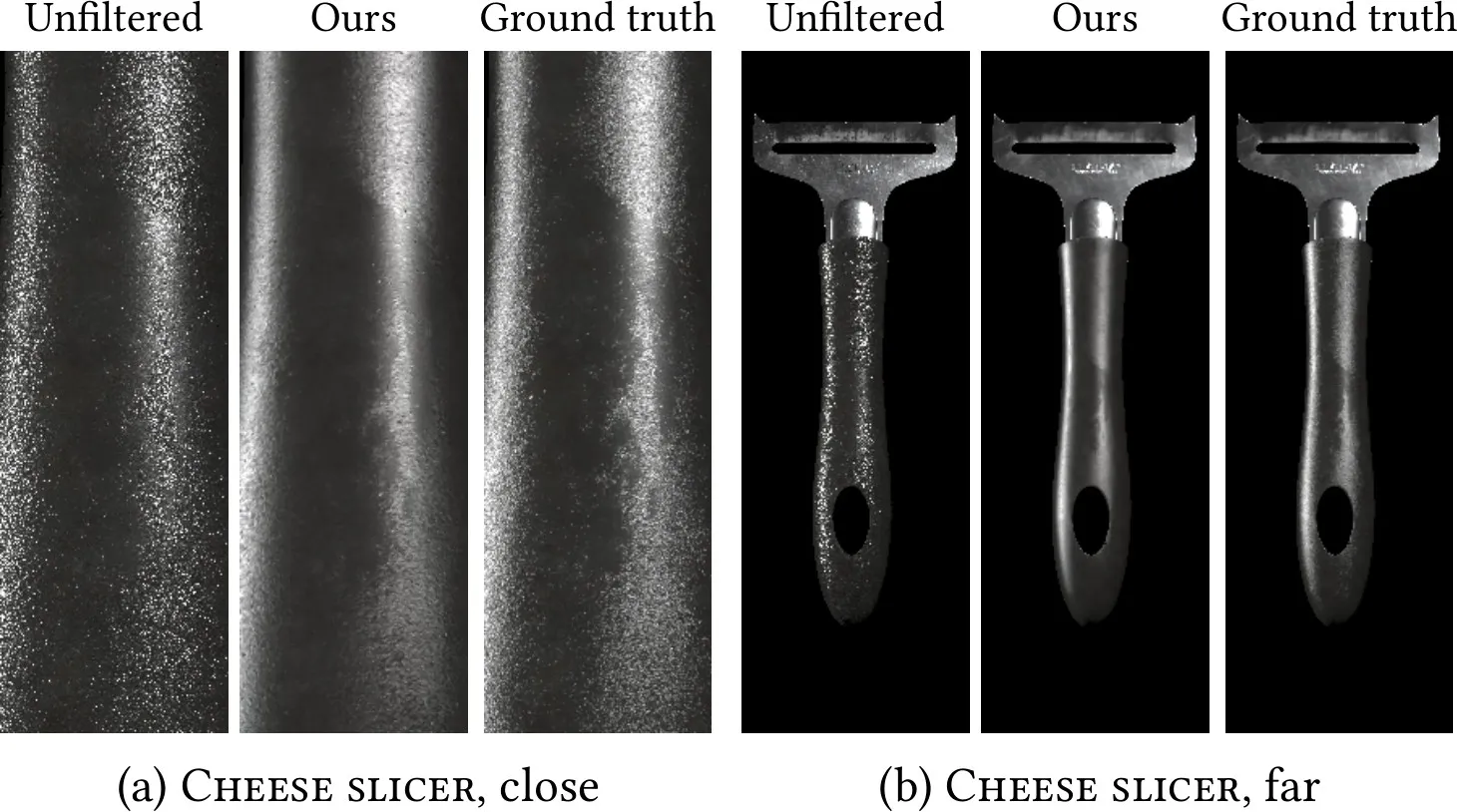
그림 5. 고해상도 재질은 슈퍼샘플링(supersampling) 없이 렌더링할 경우(왼쪽 열, unfiltered) 심각한 앨리어싱(aliasing) 을 일으킨다.슈퍼샘플링은 고주파 반짝임(high-frequency glints)을 평균내어 필터링된 재질을 생성하지만, 실시간(real-time) 렌더링에는 지나치게 많은 샘플 비용이 든다(오른쪽 열, 512 SPP의 ground truth).우리의 뉴럴 재질 모델은 슈퍼샘플링 없이도 어떤 거리에서도 앨리어싱 없는 필터링된 재질을 렌더링할 수 있다(가운데 열, ours).
•
왼쪽 (Unfiltered): 사진을 확대했는데 픽셀 깨짐이 마치 디테일처럼 보이는 경우. (가짜 디테일)
•
가운데 (Ours): 필터링해서 실제 물체가 원래 갖고 있던 디테일만 남긴 경우. (진짜 디테일)
•
오른쪽 (Ground truth): 수많은 사진을 찍어 평균 낸, 가장 정확한 원본 느낌.
이를 방지하기 위해, 계층적 잠재 텍스처(hierarchical latent texture) 는 잠재 코드를 텍스처 피라미드(texture pyramid) 에 저장한다 [Kuznetsov et al. 2021; Thies et al. 2019].
피라미드의 각 레벨은 특정 필터 반경(filter radius)으로 원본 재질을 필터링한 잠재 코드를 포함한다. 디코더는 피라미드의 모든 레벨에서 올바르게 필터링된 BRDF 값을 추론하도록 학습된다 (그림 5, (a)와 (b)의 중간 열 참고).
렌더링 과정에서 우리는 먼저 교차 지점(intersection point)에서의 픽셀 풋프린트(pixel footprint) 를 결정하고, 이를 UV 공간으로 사영(projection)한다 [Akenine-Möller et al. 2021].
그 다음 풋프린트 면적에 따라 텍스처 피라미드(texture pyramid) 에서 샘플링할 적절한 레벨을 결정한다.
레벨 인덱스는 정수가 아닐 수 있으며, 피라미드의 두 레벨 사이에 위치할 수도 있다.
이 경우 우리는 러시안 룰렛(Russian roulette) 방식을 사용해 두 레벨 중 하나를 확률적으로 선택하고, 선택된 레벨 내에서 바이리니어 보간(bilinear interpolation) 을 통해 잠재 코드를 가져온다.
이 방식은 약간의 분산(variance)을 유발하지만, 그 크기는 제한적이다.
실험 결과, 이 방법은 일반적으로 사용되는 트라이리니어 보간(trilinear interpolation) 방식보다 더 높은 품질을 제공함을 확인했다.
그 이유는, 트라이리니어 보간은 레벨 간의 잠재 코드 보간이 항상 그럴듯한 BRDF 값을 만들어야 한다는 추가 제약을 암묵적으로 유발하기 때문인 것으로 보인다. 하지만 실제로는 각 레벨이 매우 다른 내용을 저장할 수 있기 때문에, 오히려 품질 저하가 발생한다.
4.2 Transformation to learned shading frames
우리가 목표로 하는 실시간 애플리케이션(real-time applications)은 디코더 네트워크의 크기에 상당한 제약을 가한다.
따라서 현실적인 재질(그림 2의 예시와 같은)을 다루기 위해서는 아키텍처에 그래픽스 분야의 사전 지식(priors)을 통합하는 것이 필수적이다.
레이어드 재질(layered materials)은 복잡한 SVBRDF를 생성하며, 이때 표면을 따라 이동하면 반사 로브(reflection lobes)의 방향이 함께 변화한다.
전통적인 그래픽스 기법에서는 텍스처 기반 변환(textured transformations), 특히 노멀 맵(normal maps)을 사용해 이러한 효과를 쉽게 모델링할 수 있다.
그러나 일반적인 MLP만으로는 이런 효과를 구현하기 어렵다.
재질(material)은 산란 층(scattering layers)의 수만큼 많은 노멀 맵(normal maps) 을 가질 수 있다.
우리는 이러한 층들을 압축(compress) 하되, 동시에 모델이 여러 노멀 맵을 표현할 수 있는 충분한 자유도를 제공하고자 한다.
이를 위해 네트워크에 변환 모듈(transformation module) 을 포함시켰으며, 이 모듈은 입사 방향 와 출사 방향 을 여러 개의 학습된 셰이딩 프레임(shading frames)으로 변환한다 (그림 4의 mult 연산 참고).
구체적으로, 우리는 하나의 학습 가능한 레이어(trainable layer)를 사용하여 잠재 코드 z로부터 고정된 개수 N의 노멀 벡터 와 탄젠트 벡터 를 추출한다.
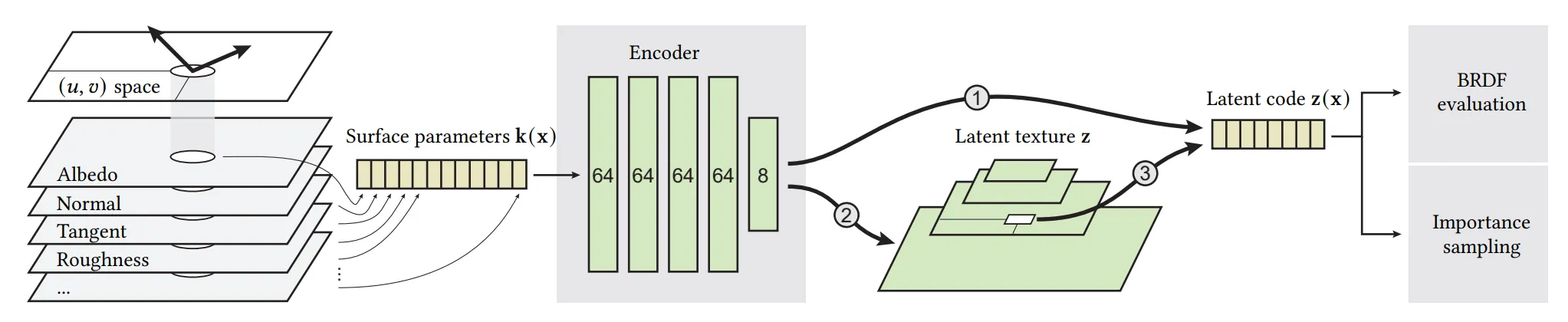
그림 6. 우리는 참조 재질(reference material)의 UV 도메인을 균일하게 샘플링하여 모델을 최적화한다. 1. 먼저 표면 파라미터(예: 알베도)를 가져와서, 이를 MLP로 인코딩하여 잠재 코드(latent code) 로 변환한 뒤, 디코더를 통해 BRDF 값으로 해석한다. (○1 경로) 2. 인코더가 충분히 학습되면, 모든 텍셀(texel)을 처리하여 잠재 텍스처(latent texture) 를 구성하고, 이후 인코더는 버린다. (○2 경로) 3. 이후에는 UV 공간과 텍스처의 MIP 레벨을 샘플링하여, 텍셀을 직접 최적화하는 방식으로 잠재 텍스처를 파인튜닝(finetuning) 한다. (○3 경로) 우리는 지수적으로 분포된 필터 풋프린트(filter footprints)를 샘플링하여 잠재 텍스처의 모든 레벨을 최적화하며, 입력 재질의 사전 필터링된 버전(prefiltered versions) 을 사용해 디코더를 학습시킨다.
각 번째 정규화된 노멀(normal)과 탄젠트(tangent) 쌍에서 기저(basis) 를 구성하고, 이들을 결합하여 통합 변환 행렬(combined transformation matrix) (T)을 생성한다:
이를 통해 N개의 새로운 입사 벡터와 출사 벡터가 생성되며, 각각은 학습된 셰이딩 프레임(shading frame)에 대응하는 한 쌍을 이룬다.
이 벡터들은 이후 디코더(decoder)의 입력으로 전달된다.
이러한 변환을 통해 모델은 입력 방향을 단일 연산으로 여러 개의 공간적으로 변화하는 셰이딩 프레임으로 회전시킬 수 있으며, 이는 네트워크의 표현력을 크게 향상시킨다.
이 방식의 구체적인 장점은 6장에서 분석한다.
Discussion. 바닐라 MLP(vanilla MLP)가 방향 벡터 회전에 어려움을 겪는 이유는 직관적으로 이해하기 어려울 수 있다.
MLP는 기본적으로 행렬 연산으로 구성되어 있지만, 고정된 네트워크 가중치를 통해 입력에 대해 곱셈적(multiplicative) 변환만 수행할 수 있기 때문이다.
즉, MLP는 입력 차원들 간의 직접적인 곱셈 연산을 수행하기 어렵다.
우리의 경우, 디코더가 단순 MLP라면 입사 방향 , 출사 방향와 재질의 공간적 변화를 담고 있는 잠재 코드(latent code)의 곱셈을 자연스럽게 처리하지 못한다.
결과적으로, 디코더는 이 곱셈적 변환을 학습 가능한 레이어만으로 근사해야 하며, 이는 모델의 표현력을 낭비한다.
우리의 접근 방식은 개념적으로 (셀프)어텐션(self-attention) 모델과 유사하다.
어텐션 모델은 활성화 간의 곱셈적 상호작용을 추가하여 신경망의 표현력을 확장한다 [Rebain et al. 2023; Vaswani et al. 2017].
4.3 Importance sampling
우리는 신경망으로 표현하기에 적합한 샘플러에 집중한다.
이는 난수 u∈[0,1)² 를 출사 방향으로 변환하는 가역적(invertible) 변환 W와, 그에 대응하는 확률 밀도 함수(PDF) ) 를 의미한다:
낮은 분산(low variance) 결과는 p의 분포가 f와 잘 일치할 때 얻어진다. 단순히 MLP를 최적화하여 샘플 변환 W를 수행하게 하는 것만으로는, W의 가역성이나 PDF의 효율적인 계산 가능성을 보장할 수 없다. 따라서 중요도 샘플링(importance sampling)은 BRDF 평가와는 다른 접근 방식이 필요하다. 우리는 기존 연구에서 영감을 받아, 닫힌 형태(closed form)로 가역적인 해석적 대리 분포(analytic proxy distribution)를 사용하고, 여기에 신경망을 결합하여 활용한다. 이 방식은 Sztrajman et al. [2021]과 Fan et al. [2022]의 방법과 유사하다.
우리는 [2022]의 방식과 유사하게 코사인 가중된 반구 분포(cosine-weighted hemispherical density)와 정반사(specular reflection) 성분을 선형 혼합(linear blend)하여 사용한다.
다만 정반사 성분의 선택에서 차이가 있다.
이전 연구에서 제안된 등방성(isotropic) 모델 — 예를 들어 Blinn-Phong 모델 [Sztrajman et al. 2021]이나 2D 가우시안 [Fan et al. 2022] — 대신, 우리는 더 일반적이고 최신의 마이크로패싯(microfacet) 모델을 채택했다.
구체적으로 Trowbridge-Reitz (GGX) NDF [Trowbridge and Reitz 1975; Walter et al. 2007]를 기반으로 하며, 여기에 타원형 이방성(elliptical anisotropy)과 비중심 평균 표면 기울기(non-centered mean surface slopes) [Dupuy 2015]를 포함시켰다.
이 접근법은 우리의 타깃 재질처럼 노멀맵 효과가 두드러진 재질에 적합할 뿐만 아니라, 필터링된 BRDF가 자연스럽게 생성하는 이방성(anisotropic) 분포에도 효과적으로 대응한다.
6장에서 이러한 장점들을 상세히 보여주며, 샘플러에 관한 추가 세부사항은 부록 A에 수록했다.
[2022]에서와 유사하게, 우리는 코사인 가중 반구 분포(cosine-weighted hemispherical density) 와 정반사(specular reflection) 성분 사이의 선형 혼합(linear blend)을 사용한다. 다만, 정반사 성분의 선택에서 차이를 둔다.
이전 연구들이 제안했던 등방성(isotropic) 모델 ― 예: Blinn-Phong 모델 [Sztrajman et al. 2021] 또는 2D Gaussian [Fan et al. 2022] ― 과 달리, 우리는 보다 일반적이고 최신(state-of-the-art)인 마이크로패싯(microfacet) 기반 모델을 사용한다.
구체적으로는, Trowbridge-Reitz (GGX) NDF [Trowbridge and Reitz 1975; Walter et al. 2007]에 기반한 모델을 사용하며,
•
타원형 이방성(elliptical anisotropy)
•
중심이 이동된 평균 표면 기울기(non-centered mean surface slopes) [Dupuy 2015]
까지 포함한다. 이 방식은 우리가 목표로 하는 재질들에서 흔히 나타나는 강하게 노멀맵이 적용된 재질과, 자연스럽게 이방성 분포를 만들어내는 필터링된 BRDF 모두에 잘 맞는다.
그 장점은 6장에서 보여주며, 샘플러의 추가적인 세부 사항은 부록 A에서 다룬다.
5. Training
이제 디코더와 잠재 텍스처(latent texture)의 학습 절차(그림 6 참고)와 학습 데이터 생성 방식을 설명한다. 세부 재질(detailed materials) 학습에서 가장 큰 과제는 최적화해야 할 파라미터의 방대한 수이다. 네트워크 자체의 가중치 수는 적지만, 잠재 텍스처는 소스 재질과 동일한 해상도를 가져 그 크기가 매우 클 수 있다.
예를 들어, 티포트(Teapot)의 세라믹 본체(그림 2)는
•
14개의 4k × 4k 텍스처 타일로 정의되며,
•
총 2억 3,500만 개의 텍셀(texel)을 포함하고,
•
이는 25억 개의 잠재 파라미터(latent parameters)에 해당한다.
이 모든 파라미터를 역전파(backpropagation)를 통해 독립적으로 최적화하는 것은 현실적이지 않다.
따라서 우리는 학습의 첫 단계에서 인코더(encoder)를 사용해 잠재 코드를 초기화(bootstrap)하며, 이에 대해 다음에서 설명한다.
5.1 Encoder
인코더는 간단한 MLP로, 특정 쿼리 위치 x에서 원본 재질의 파라미터 k(x) — 알베도(albedo), 러프니스(roughness), 노멀맵(normal map) 등 모든 재질 레이어의 파라미터 — 를 입력으로 받아 해당하는 잠재 벡터(latent vector) z(x)를 출력한다.
필터링을 초기화하기 위해, 계층(hierarchy)의 거친 MIP 레벨에 대해 재질 파라미터 k(x)를 LEAN [Olano and Baker 2010] 기법으로 사전 필터링(prefiltering)한다.
첫 번째 학습 단계에서 모델은 엔드투엔드(end-to-end) 방식으로 학습되며, 인코더에서 생성된 잠재 코드는 잠재 텍스처를 거치지 않고 바로 디코더로 전달된다.
디코더가 수렴하면 파인튜닝(finetuning) 단계로 전환한다. 이 단계에서는 모든 텍셀에 대해 인코더를 평가하여 잠재 텍스처를 초기화한 후, 인코더를 제거한다.
잠재 텍스처의 내용은 디코더를 통한 역전파(backpropagation)로 직접 학습된다. 인코더는 학습 과정에서만 사용되므로, 렌더링 시 평가 비용에 영향을 주지 않는다.
인코더는 또한 잠재 공간(latent space)의 구조를 개선한다.
유사한 재질 파라미터가 잠재 공간에서 유사한 지점으로 매핑되도록 보장하는 것이다.
이로 인해 보간(interpolation) 결과가 향상되고 디코더의 작업 부담도 줄어든다.
반면, 직접 최적화(direct optimization)만 사용할 경우 잠재 텍스처에 무작위 초기화 노이즈가 일부 남게 되는데, 이는 6.2절에서 자세히 분석한다.
인코더는 여러 재질(material)을 인코딩하도록 학습하거나, 참조 BRDF의 전체 파라미터 공간(예: 균일 샘플링)을 커버하도록 학습할 수 있다. 그러나 잠재 텍스처는 메모리 사용량이 매우 크기 때문에, 실제 구현에서는 각 재질마다 개별적인 인코더를 사용하여 따로 학습하는 방식을 채택한다(별도 언급이 없는 한)
5.2 Data generation and optimization
우리는 목표 재질(멀티 레이어)의 UV 공간을 균일하게 샘플링하여 학습 데이터를 생성한다.
각 샘플에 대해, 우리는 입사 방향 와 출사 방향 를 반각 벡터(half vector)와 차이 벡터(difference vector)를 균일 샘플링하는 방식으로 생성한다 [Rusinkiewicz 1998; Sztrajman et al. 2021].
그 후 참조 BRDF 값을 평가한다.
각 샘플은 추가적으로 다음 정보를 포함한다:
•
노멀(normal)
•
탄젠트(tangent)
•
알베도(albedo)
•
러프니스(roughness)
•
레이어 가중치(layer weight)
각 레이어별로 이 값들이 포함되므로, 레이어 수에 따라 하나의 샘플이 100개가 넘는 부동소수점 수를 가질 수 있다.
우리는 이 샘플들을 학습 중에 GPU에서 온라인(online)으로 생성한다.
Filtering (필터링)
각 학습 샘플마다 피라미드 레벨을 지수 분포(exponential distribution)에서 샘플링하며, 더 정밀한(finer) 레벨을 선호한다.
해당 레벨에 맞는 풋프린트로 가우시안(Gaussian) 분포에서 여러 점을 샘플링해 평균을 취하며, 샘플 개수는 필터 영역 크기에 비례하게 한다.
이 샘플링 과정은 충분히 빠르기 때문에 학습 시간에 큰 영향을 주지 않는다.
Mollification (완화)
재질에 매우 좁은 피크(예: 티포트의 매끄러운 유약층)가 있는 경우, 학습 초기에 큰 에러가 발생하고 네트워크가 학습하기 어렵다.
이를 해결하기 위해, 학습 초반에는 출사 방향 를 중심으로 한 작은 원뿔(cone) 안에서 여러 샘플을 평균내어 재질을 방향적으로 블러(blur) 처리한다.
훈련이 진행됨에 따라 원뿔의 각도를 점점 줄여나가면서, 네트워크가 먼저 재질의 큰 특징을 학습한 후 최종적으로 참조 재질에 수렴하도록 한다.
Optimization (최적화)
우리는 BRDF 디코더와 중요도 샘플러를 동시에 학습시켜, 공유된 잠재 공간(shared latent space)을 구축한다.
•
BRDF 예측은 로그 공간에서의 손실 [Zheng et al. 2021]을 사용해 최적화한다.
•
학습된 샘플러에서 뽑힌 출사 방향의 PDF는, 현재 학습 중인 BRDF 상태와의 KL 발산(KL divergence)으로 평가한다.
또한, 학습 안정성을 높이기 위해 잠재 코드(latent code)를 KL 손실 계산에서 분리(detach) 하는 것이 효과적이었다.
이렇게 하면 샘플러 MLP는 잠재 코드를 해석하는 법을 학습하면서도, 주 BRDF 디코더의 평가 과정에는 간섭하지 않게 된다.
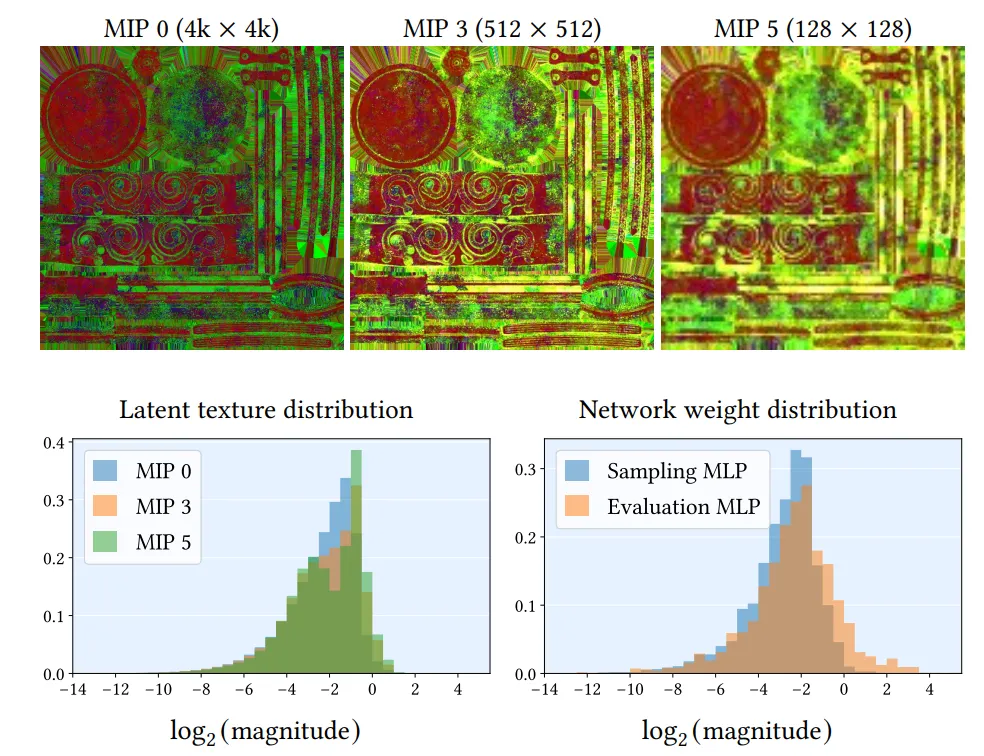
그림 7 설명 상단 행: 뉴럴 잉크웰(Inkwell) 재질의 최적화된 잠재 텍스처(latent texture). (MIP 계층 구조에서 세 가지 레벨을 보여주며, 3개 채널을 RGB로 시각화) 하단 행: 해당 잠재 값들의 분포(왼쪽)와 네트워크 파라미터 크기의 분포(오른쪽). 모든 파라미터는 FP16 부동소수점(FP16 normal numbers, 비정규화 수 제외)의 수치 범위 안에 안정적으로 위치한다. 따라서 양자화(quantization) 가 용이하다. 다른 재질들 또한 매우 유사한 분포를 보인다.
알베도(Albedo) 예측이 활성화된 경우, 식 (2)의 단일 샘플 몬테카를로(MC) 추정치에 대한 L2 손실을 사용해 최적화한다.
모델 최적화를 위해 총 300,000번의 반복 학습을 진행하며, 매 반복마다 65,000개 샘플로 구성된 두 개의 배치를 처리한다 - 하나는 BRDF 디코더용, 다른 하나는 샘플러용이다. 이는 약 400억 개의 온라인 생성 재질 샘플에 해당하며, 단일 NVIDIA GeForce RTX 4090에서 재질당 약 4~5시간이 소요된다. 학습 과정에 대한 추가 세부사항은 보충 문서에서 확인할 수 있다.
정밀도(Precision). BRDF 디코더와 샘플러를 위한 마스터 파라미터는 32비트 부동소수점(FP32) 정밀도로 학습한다. 혼합 정밀도 학습(mixed precision training)을 적절히 활용하면 정확도 손실 없이 학습 성능을 향상시킬 수 있지만, MLP 크기가 작아 이 방법은 탐구하지 않았다. 효율적인 추론을 위해 학습 후 양자화를 적용하여 로드 시 파라미터를 half precision(FP16)으로 변환한다. 그림 7은 평가 및 샘플링 모델의 파라미터 분포 예시를 보여준다. 모든 예제에서 네트워크 파라미터의 수치 범위는 FP16의 정규화된 범위 내에 있었다. 향후에는 런타임 정밀도를 INT8 이하로 줄이기 위한 양자화 인식 학습(quantization aware training)을 탐구할 계획이다.
6. MODEL ANALYSIS AND ABLATION
앞서 외형 모델(appearance model)과 학습 절차를 소개했으므로, 이제 주요 기술적 혁신 요소들을 분석하겠다:
i) 학습된 셰이딩 프레임(shading frames)으로의 변환,
ii) 이방성(anisotropic) 중요도 샘플러,
iii) 인코더의 사용.
또한 필터링 기능과 알베도 추론 옵션의 효과도 함께 시연한다.
그동안 다양한 뉴럴 어피어런스 모델들이 발표되어 왔으며, 이들은 외형 모델링의 여러 측면을 다루어 왔다. 예를 들어:
•
기하학적 디테일 수준(geometric level of detail) [Kuznetsov et al. 2021, 2022]
•
잠재 공간(latent space)의 해석 가능성 [Zheng et al. 2021]
•
뉴럴 컴포넌트의 레이어링(layering) [Fan et al. 2022]
이러한 연구들은 우리 시스템을 보완하는 성격을 가지며, 미래에는 통합될 수도 있다.
본 연구에서는 특히 영화 수준의 비주얼 품질(film-quality visuals)과 현대 GPU에서의 효율적 실행(7장에서 제시)을 목표로 한다.
연구 초점이 다르기 때문에 기존 접근법과 우리의 연구를 직접 비교하기는 어렵다.
대신, 우리는 모델의 두 가지 소거(ablation) 변형 버전을 표 2와 그림 8에서 비교하고, 이들을 기존 연구의 구성 요소들과 연관 지어 논의한다.
Vanilla MLP 디코더 + 잠재 텍스처 기본 변형(basic variant)은 계층적 잠재 텍스처(hierarchical latent texture)와 Vanilla MLP 디코더만을 사용한다.
즉, 디코더 내에서 셰이딩 프레임으로의 명시적 회전은 없으며, 잠재 텍스처의 텍셀은 역전파(backpropagation)를 통해 직접 최적화된다.
이 변형은 Sztrajman et al. [2021]의 디코더를 계층적 뉴럴 텍스처 [Thies et al. 2019]를 사용해 공간적 변화를 처리하도록 확장한 것으로 볼 수 있다.
또한, NeuMIP 모델 [Kuznetsov et al. 2021]과도 개념적으로 유사하지만, NeuMIP는 변위된 표면(displaced surfaces)을 처리하기 위한 UV 오프셋 모듈을 추가로 갖추고 있다.
그러나 이 변형의 결과(그림 8, 첫 번째 열)는 최적화해야 할 잠재 텍셀 수가 방대하여 참조 재질의 공간적 디테일을 제대로 재현하지 못한다.
잠재 텍스처 최적화가 해상도 증가에 따라 어떻게 스케일링 되는지는 6.2절에서 추가로 분석한다.
Latent texture encoder 그림 8의 두 번째 열은 인코더(섹션 5.1)를 추가했을 때의 장점을 보여준다.
텍스처 디테일이 더 충실하게 재현되는 주요 이유는 두 가지가 있다.
1.
인코더는 동일한 BRDF를 갖는 여러 텍셀이 최적화 과정 후 서로 다른 잠재 코드를 갖게 되는 상황을 방지한다.이런 잠재 코드와 BRDF 값 간의 비단사적 매핑(surjective mapping)은 기본 모델(첫 번째 열)에서 자주 발생하며, 디코더의 표현력을 낭비한다.
2.
인코더는 하나의 잠재 텍셀만을 개별적으로 최적화하는 대신, 각 학습 샘플 레코드를 여러 잠재 텍셀에 걸쳐 분산(amortize)시킨다.
이 특정 예제에서는 공간적 변화를 잘 포착했지만, 디코더는 티포트 세라믹의 좁은 반사 로브(narrow reflection lobe)를 제대로 포착하지 못했다.
반면, 이는 바닐라 MLP 디코더에서는 올바르게 재현되었다.
이는 모델이 공간적 변화와 고주파 반사를 동시에 정확히 재현하기에 표현력이 부족(insufficient modelling capacity)함을 시사한다.
이 문제는 디코더의 크기를 키움으로써 해결할 수 있다.
우리의 인코더-디코더 아키텍처는 Rainer et al. [2019]가 BTF(Bidirectional Texture Functions)를 압축하기 위해 사용한 오토인코더(autoencoder)와 유사하다.
그러나 중요한 차이점은 우리가 반사율 측정값을 인코딩하는 대신, 재질 파라미터(알베도, 러프니스, 노멀 등)를 인코딩하도록 설계했다는 점이다.
이 덕분에 인코더가 재질 파라미터화의 중복성을 활용할 수 있어, 시스템은 초고해상도 텍스처로의 확장성을 더욱 개선할 수 있다.
학습된 셰이딩 프레임으로의 변환 (Transformation to learned shading frames)
그림 8의 세 번째 열에서는, MLP 디코더 앞에 입사/출사 방향을 두 개의 학습된 셰이딩 프레임으로 변환하는 과정을 추가한다.
이 프레임들은 잠재 코드(latent code)에서 12개의 뉴런을 가진 추가 학습 가능한 레이어(trainable layer) 를 통해 추출된다. 이것이 곧 우리의 완전한 모델(complete model) 을 구성한다.
4.2절에서 논의했듯이, 입력에 대해 곱셈 연산(multiplicative operation)을 명시적으로 수행하면,
표 2. 그림 8의 네 장 이미지에 대해 세 가지 모델 변형을 비교한 평균 이미지 오류 지표
Variant | Mean FLIP | Mean abs. error | Mean sqr. error | Mean rel. abs. error | Mean rel. sqr. error | SMAPE |
Vanilla MLP | 0.2390 | 0.0769 | 0.0682 | 0.2177 | 0.0798 | 0.2670 |
with encoder | 0.1956 | 0.0652 | 10.1933 | 0.3439 | 265.4018 | 0.2397 |
with frame transform | 0.0815 | 0.0183 | 0.0057 | 0.0656 | 0.0090 | 0.0713 |
MLP가 이를 비선형 레이어를 사용해 억지로 근사할 필요가 없어지게 된다. 그 결과, 단순 노멀맵(normal mapping)과는 직접적으로 관련되지 않은 효과들까지 포함하여 결과의 품질이 향상된다. 이는 명시적인 셰이딩 프레임 변환으로 확보된 모델의 표현력이, BRDF의 형태와 공간적 변화를 더 잘 포착하는 데 투자된다는 것을 시사한다.
6.1 Filtering
우리는 그림 9에서 잠재 피라미드(latent pyramid)의 개별 레벨을 슈퍼샘플링으로 렌더링한 그라운드 트루스와 비교하여 필터링 품질을 평가한다.
우리의 필터링된 모델은 근거리에서는 잘 맞지만, 중간 거리에서는 작은 디테일이 손실된다.
이는 잠재 최적화(latent optimization)가 레벨 0에서만큼 더 높은 레벨(coarser levels)에서는 잘 작동하지 않아, 결과가 약간 과도하게 블러링(overblur)되기 때문이다.
이 문제는 MIP 레벨 선택을 더 정밀한 레벨 쪽으로 편향(bias)시키는 방법으로 보완할 수 있지만, 약간의 앨리어싱(aliasing) 이 발생하는 대가를 치르게 된다. 멀리서 보면 모든 레벨은 비슷한 외형을 보인다.
6.2 Latent texture optimization
우리는 그림 10에서 인코더 사용의 장점을 더 분석한다. 여기서 MIP 레벨 0에서의 서로 다른 구성의 잠재 텍스처를 비교한다.
•
상단 행: 직접 최적화(direct optimization)로 얻은 잠재 텍스처
•
하단 행: 인코더를 사용했을 때의 결과
•
해상도별: 작은 해상도 (512 × 512, 왼쪽)와 큰 해상도 (4k × 4k, 오른쪽)
아래 인셋(inset)에서는 학습된 텍스처의 클로즈업과 해당 영역의 렌더링 외형을 함께 보여준다.
작은 해상도(예: NeuMIP [Kuznetsov et al. 2021]에서 사용된 수준)에서는 직접 최적화와 인코더가 비슷하게 동작한다.
그러나 큰 해상도에서는 차이가 뚜렷해진다.
예를 들어, 4k × 4k 해상도에서는 직접 최적화된 텍셀들이 512 × 512 잠재 텍스처의 텍셀들보다 약 64배 적은 그래디언트 업데이트를 받게 된다. 그 결과, 디코더는 무작위 초기화로 인해 크게 달라진 잠재 코드들을 같은 BRDF 값으로 매핑해야 하며, 이는 성능을 저해한다.
수렴된 모델에서도 초기화 노이즈가 여전히 눈에 띈다. 반면, 인코더는 데이터와 연산을 더 효율적으로 사용하여 높은 충실도의 시각적 결과를 낸다. 모든 모델은 동일한 양의 학습 데이터를 사용해 학습되었다.
그러나 직접 최적화를 사용한 모델은 더 많은 메모리를 필요로 했기 때문에, 학습이 연산적으로 덜 강도 높은 편이었음에도 불구하고 학습 시간이 거의 두 배(최대 10시간)로 증가했다.

그림 8 설명 동일한 학습 반복 횟수에서 두 가지 소거(ablation) 변형 모델과 우리의 완전한(full) 모델을 정성적으로 비교한 결과이다. 첫 번째 열: 바닐라 MLP 디코더와 직접 최적화된 잠재 텍스처(latent texture)를 사용한 경우 → 품질이 제한적이다. 두 번째 열: 인코더를 학습하여 잠재 텍스처를 생성한 경우 → 동일한 외형(appearance)을 가진 텍셀이 동일한 잠재 코드로 매핑되어 BRDF 값으로의 디코딩이 더 효율적이다. 세 번째 열: MLP 디코더에 입출 방향을 학습된 셰이딩 프레임으로 변환하는 명시적 단계를 추가한 경우(우리의 완전한 모델) → 참조 이미지(마지막 열)의 재현 품질이 크게 향상된다. 왼쪽 아래 모서리의 작은 이미지는 FLIP 차이 지표(FLIP difference metric)를 시각화한 것이다. 또한, 셰이딩 프레임 추출기가 없는 모델들(첫 두 열)은 완전한 모델과 파라미터 수를 맞추기 위해 뉴런 8개로 구성된 첫 번째 레이어를 추가하였다.

그림 9. 우리는 치즈 슬라이서(Cheese slicer) 애셋을 다양한 거리에서 관찰하면서, 풋프린트 기반 레벨 선택(footprint-based level selection) 과 고정된 잠재 피라미드 레벨(fixed latent pyramid levels, 슈퍼샘플링으로 렌더링된 결과) 을 비교하여 필터링 품질을 평가한다. 가까이서 보면, 더 거친(coarser) 레벨들은 작은 디테일(예: 빛 반짝임, glints)을 잃어버리며, 이는 우리의 필터링된 결과에서도 반영된다. 반면, 레벨 0은 앨리어싱(aliasing)의 대가를 치르긴 하지만, 그라운드 트루스와 거의 완벽하게 일치한다. 멀리서 보면, 모든 레벨이 평균적으로 시각적으로 유사한 외형을 보인다.

그림 10. 잉크웰(Inkwell) 애셋의 잠재 텍스처(latent textures). 직접 최적화(direct optimization, 상단 행) 는 작은 텍스처(왼쪽)에서는 잘 동작하지만, 해상도가 높아질수록(오른쪽) 비효율적이다. 텍셀들을 독립적으로 최적화하는 방식은 계산 비용이 매우 크며, 많은 이터레이션 후에도 잠재 텍스처에는 여전히 상당한 초기화 노이즈(initialization noise)가 남아 있다. 따라서 우리는 인코더(bottom row) 를 학습한다. 인코더는 PBR 표면 속성(PBR surface attributes) 을 잠재 코드(latent codes)로 변환하며, 어떤 해상도에서도 실행될 수 있다. 모든 분석된 구성(configuration)은 동일한 양의 데이터를 사용해 최적화되었다. 왼쪽 인셋(inset)은 텍스처의 작은 부분을 확대하여 보여주며, 이는 오른쪽 렌더링 인셋에서도 부분적으로 확인할 수 있다.
6.3 Importance sampling
우리는 4.3절에서 설명한 중요도 샘플러를 Sztrajman et al. [2021] 및 Fan et al. [2022]의 방법과 유사한 단순화된 변형과 비교했다.
이 단순화된 변형은 두 가지 출력만 생성하도록 학습된다:
•
등방성(isotropic) 러프니스 파라미터
•
정반사(specular)와 확산(diffuse) 성분을 혼합하기 위한 상대적 가중치
그림 11은 LOD(level-of-detail) 렌더링 상황에서 더 일반적인 접근법의 장점을 보여준다.
특히, 노멀 맵(normal map)이 적용되거나 필터링된 BRDF의 경우, 비중심(non-centered) 및 이방성(anisotropic) NDF를 샘플링하는 것이 유용하다.
우리는 또한 정규화 흐름(normalizing flows) [Dinh et al. 2017] 기반의 샘플러를 시스템에 적용하는 방안도 검토했다. 구체적으로 Zheng et al. [2021]이 제안한 변형으로, 이 방법은 half-vector 분포를 두 개의 구간별 이차 함수(piecewise quadratic) 워프 [Müller et al. 2019]로 표현하며, 각 함수는 3개 은닉층(각 층 16 뉴런)을 가진 MLP로 파라미터화된다.
이 방법이 우리가 선택한 접근법과 비슷한 샘플링 품질을 제공하지만, 전체 프레임 렌더링 시간이 2~3.8배 증가한다는 사실을 확인했다(그림 12 참조). 이러한 성능 저하로 인해 실시간(real-time) 환경에서는 적합하지 않다. 이는 추가적인 워프 연산 오버헤드와 셰이딩 과정에서 더 많은 MLP를 평가해야 하기 때문이다.
정규화 흐름(normalizing flows)은 각 히트(hit)마다 총 4개의 MLP를 실행해야 한다:
•
출사 방향을 샘플링할 때 2개
•
연관된 PDF를 평가할 때 2개 (예: 다중 중요도 샘플링(MIS) 가중치 [Veach and Guibas 1995] 계산용)
반면, 우리의 방법은 히트당 샘플링 네트워크를 한 번만 호출하고, 그 결과로 얻은 해석적 대리 분포(analytic proxy distribution) 파라미터를 캐싱하여 이후 샘플링 및 PDF 평가 단계에서 재사용한다.
6.4 알베도 추론(Albedo inference)
그림 13은 데이터 기반 BRDF 모델이 추가적인 재질 특성(material characteristics)을 학습할 수 있는 능력을 보여준다. BRDF 디코더는 다층 재질(multilayer material)의 알베도를 근사하는 추가적인 RGB 3채널(triplet)을 출력한다. 우리는 이 RGB 트리플릿을 학습 중에 실제 알베도의 단일 샘플(one-sample) 추정치와 비교하여 손실로 최적화하며, 이를 통해 평균값으로의 수렴을 보장한다.
알베도 예측 능력은 개별 구성 요소의 텍스처 값만 출력할 수 있는 해석적(analytical) 모델 기반의 복잡한 재질 표현과 비교해 우위(advantage)를 제공한다.
이는 경로 추적기(path tracer)에서는 일반적으로 수치적 알베도 추정이 불가능하기 때문이다. 추론된 알베도 값은 디노이저(denoiser)를 안내하는 용도 등으로 활용할 수 있다.
7. Inline Neural Materials
이 절에서는 레이 트레이싱 셰이더(ray tracing shaders) 안에서 우리의 뉴럴 어피어런스 모델(neural appearance model)을 인라인(inline)으로 실행하는 런타임 시스템을 설명한다.
최신 실시간 NeRFs 연구 [Müller et al. 2022]처럼, 우리는 GPU에서 신경망을 완전히 결합(fused)된 형태로 처음부터 구현했다.
그러나 커널을 직접 작성하는 대신, 런타임 코드 생성(run-time code generation)을 사용하여 렌더링 코드와 함께 뉴럴 모델을 인라인 평가한다.
이 접근 방식은 레이 트레이싱 셰이더 프로그램의 모든 히트 포인트(hit point)에서 신경망을 세밀하게 실행하면서, 핸드코드(hand-written code)와 함께 사용할 수 있게 한다.
이를 구현하는 과정에서 몇 가지 기술적 도전 과제가 있었다:
1.
기존 머신러닝 프레임워크의 한계
•
PyTorch, TensorFlow 같은 프레임워크는 대규모 배치(batch)의 신경망을 일관적으로(coherent) 실행하도록 설계되어 있다.
•
GLSL이나 HLSL 같은 실시간 셰이딩 언어에 신경망을 통합(integrate)하는 도구는 거의 없다.
•
특히 레이 트레이싱 환경에서는 실행 경로가 분기(divergent)될 수 있어 더욱 어렵다.
2.
하드웨어 가속 행렬 연산 활용 문제
•
최신 GPU 아키텍처(AMD¹, Intel², NVIDIA³)에서 제공하는 MMA(matrix multiply-accumulate) 연산을 활용하고 싶지만,
•
현재의 셰이딩 언어는 이러한 명령어를 지원하지 않는다.
3.
렌더러에서의 실행 및 데이터 발산(divergence) 문제
•
렌더링 중에는 실행 경로와 데이터 접근이 불규칙적이어서 신경망에 불리하다.
•
신경망은 대량의 파라미터 데이터를 메모리에서 불러와야 하기 때문이다.
7.1 Neural Material Shaders
우리의 뉴럴 모델은 여러 개의 작은 MLP로 구성되어 있으며, 그 사이사이에 비-신경망 연산(non-neural operations) 블록이 연결되어 있다.
재질(materials)은 오프라인에서 학습되고, 최종 모델의 설명(description)과 함께 학습된 계층적(latent) 텍스처가 내보내진다. 이 텍스처들은 mipmap이 적용된 16비트 RGBA 이미지로 저장된다.
잠재 텍스처(latent textures)의 압축(texture compression)은 앞으로 흥미로운 연구 주제가 될 수 있다.
특히, 뉴럴 텍스처 압축(neural texture compression) [Vaidyanathan et al. 2023] 은 매우 유망할 수 있는데, 이는 압축과 뉴럴 머티리얼 모델을 엔드-투-엔드(end-to-end) 로 함께 학습시킬 수 있기 때문이다.
런타임 시스템은 뉴럴 머티리얼 설명을 최적화된 셰이더 코드로 컴파일한다.
우리는 오픈 소스 셰이딩 언어인 Slang [He et al. 2018] 을 목표로 삼았으며, Slang은 Vulkan, Direct3D 12, CUDA 등 다양한 백엔드를 지원한다. Slang은 코드의 논리적 모듈화를 위한 셰이더 모듈(shader modules) 과 인터페이스(interfaces) 를 지원한다. 우리는 각 뉴럴 머티리얼마다 하나의 셰이더 모듈을 생성하고, 이는 수기 작성된(hand-written) 머티리얼과 동일한 인터페이스를 구현한다.
즉, 렌더러에서 뉴럴 머티리얼은 기존의 고전적인 머티리얼과 다르지 않게 실행된다.
구현 세부 사항과 기능 재현성을 위한 의사코드(pseudocode) 예제는 부록(supplemental material)에 수록되어 있다.

그림 11. 중요도 샘플러(위쪽 행)는 등방성(isotropic) 정반사만 지원하는 단순한 변형(아래쪽 행) 과 비교했을 때, 노이즈 수준을 줄여준다. 이는 Sztrajman et al. [2021] 및 Fan et al. [2022]의 방식과 유사한 맥락이다. 왼쪽: 비중심(non-centered) 마이크로패싯 NDF를 사용하여, 노멀 맵의 세밀한 디테일을 포착한다. 오른쪽: 더 거친 MIP 레벨에서는 필터링된 분포가 강하게 이방성(anisotropic)을 띤다. 확대된 뷰는 SPP 4 (samples per pixel) 로 렌더링되었다. 거짓 색상(false-color) 이미지는 픽셀 단위 표준편차와, 인셋 전체에서의 평균값을 보여준다.
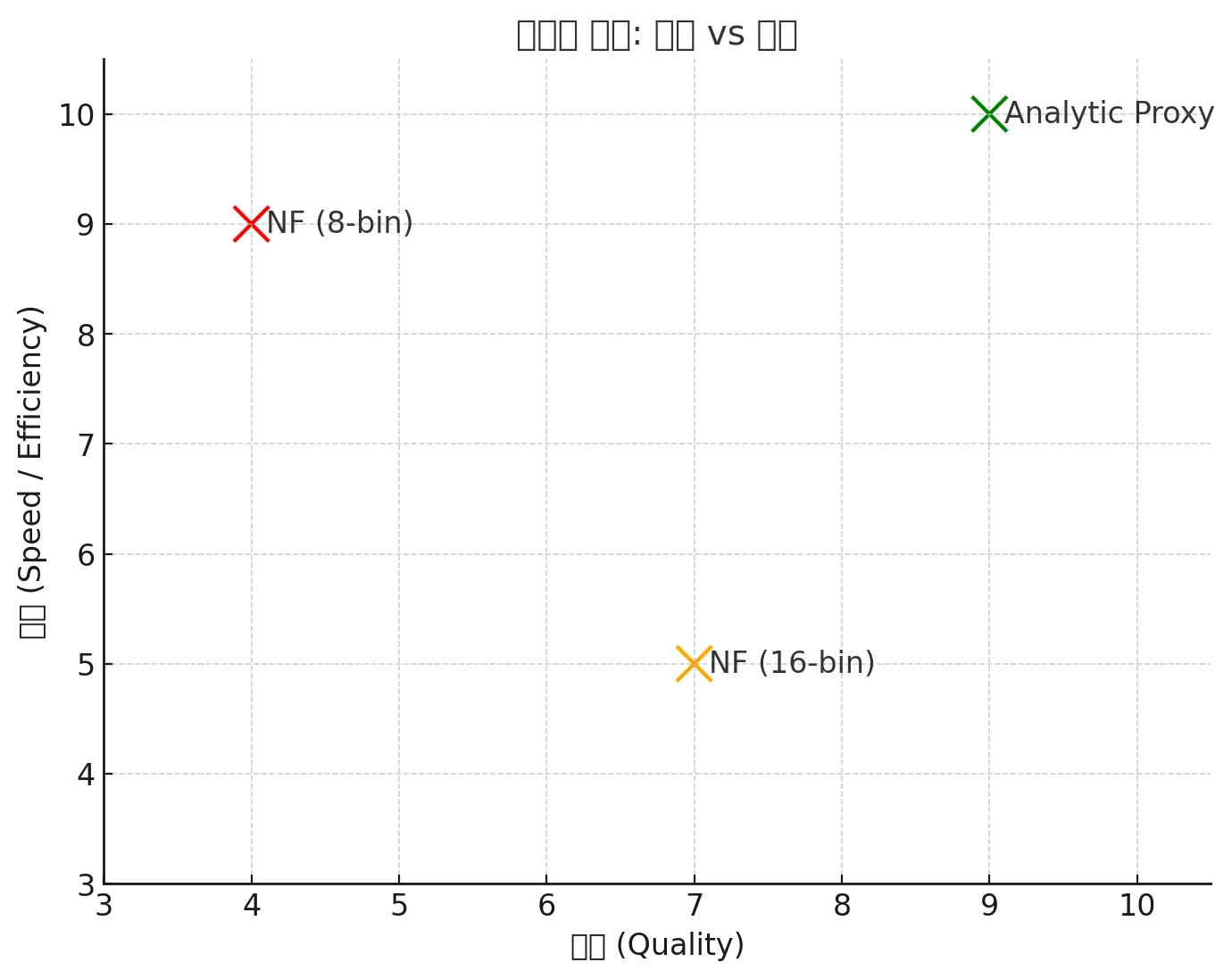
•
X축 (품질, Quality): 높을수록 디테일과 정확도가 좋음
•
Y축 (속도, Speed): 높을수록 실시간 성능이 뛰어남
•
 NF (8-bin) → 빠르지만 품질 낮음
NF (8-bin) → 빠르지만 품질 낮음•
NF (16-bin) → 품질 개선, 속도 저하•
Analytic Proxy (우리 방법) → 품질과 속도 모두 우수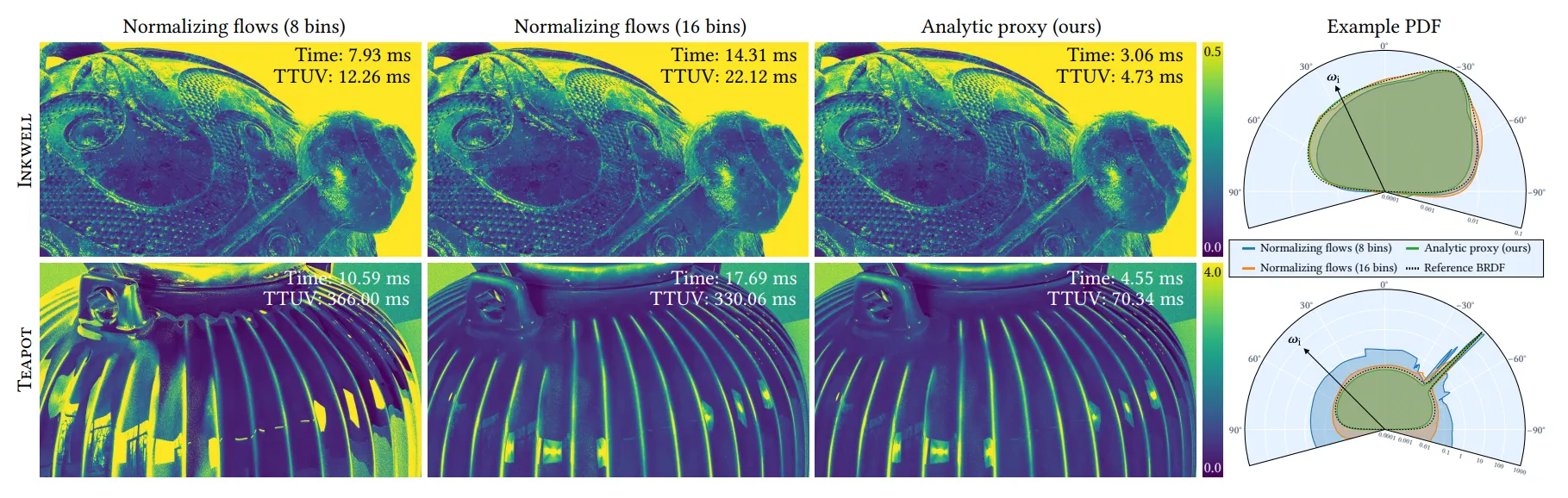
그림 12. 픽셀 단위 표준편차(pixel-wise standard deviation) 이미지를 통해, 우리의 중요도 샘플러와 정규화 흐름(normalizing flows) 기반의 대안 구현을 비교한 결과이다. 첫 번째 열: Zheng et al. [2021]과 동일하게 8개의 bin을 가진 warp를 사용하는 샘플러 구조는, 광택 있는(Inkwell) 금속에는 적절하지만, 매우 강한 정반사 피크를 가진 Teapot 세라믹에서는 제대로 대응하지 못한다. 두 번째 열: 더 고품질인 16 bin warp를 사용하면 피크를 포착할 수 있으며, 대략적으로는 우리가 제안한 해석적 대리(analytic proxy) 기반 샘플러(세 번째 열) 의 분산과 일치한다. 마지막 열: 학습된 분포(learned densities)의 극좌표 플롯(polar plots, 로그 스케일) 을 보여준다. 플롯 위에 표시된 숫자는 다음을 보고한다: 렌더링 시간 (1 SPP로 전체 프레임 렌더링) 단위 분산 도달 시간(TTUV, Time To Unit Variance) → 즉, 평균 분산과 렌더링 시간의 곱 이 수치는 정규화 흐름 기반 접근 방식의 상당한 런타임 오버헤드를 드러낸다. 모든 경우에서 평가 네트워크의 크기는 동일하게, 2개 레이어 / 각 32 뉴런 으로 고정되었다.
Figure 12 비교 (Importance Sampler vs Normalizing Flows)
방식 | 구조 | 성능 (재질별) | 분산(variance) | 런타임 효율 | 비고 |
Normalizing Flow (8-bin warp) | 2 layers × 32 neurons, 8 bin warp | - Inkwell 금속: 적절- Teapot 세라믹: 강한 스펙큘러 피크 표현 실패 | 높음 (노이즈 큼) | 빠르지만 한계 존재 | Zheng et al. [2021]과 동일 구성 |
Normalizing Flow (16-bin warp) | 2 layers × 32 neurons, 16 bin warp | - Inkwell 금속: 적절- Teapot 세라믹: 피크 포착 가능 | 낮음 (우리 방식과 유사) | 런타임 ↑ (오버헤드 큼) | 품질은 개선되지만 실시간성 저하 |
Analytic Proxy 기반 (우리 방식) | 2 layers × 32 neurons + analytic proxy | - Inkwell 금속: 적절- Teapot 세라믹: 피크 정확히 포착 | 낮음 (안정적) | 가장 효율적 (한 번만 샘플링 후 캐싱) | TTUV(Time To Unit Variance) 최적 |

그림 13. BRDF 디코더는 재질의 알베도(albedo) 를 추가적으로 추론하도록 학습될 수 있다. 이를 위해, 디코더의 추가 RGB 출력을 참조 재질(reference material)의 알베도에 대한 몬테카를로 추정치(Monte Carlo estimate) 와 비교하여 최적화한다.
Code Generation GPU는 SIMT (Single Instruction, Multiple Threads) 실행 모델을 사용한다. 여기서는 스레드 묶음(배치, wavefront 또는 warp)이 동일한 명령을 동시에 실행한다. 제어 흐름(control flow)에 따라 일부 스레드가 종료되거나 마스킹(masking)될 수 있다.
문제는 각 스레드가 서로 다른 히트 포인트(hit point) 와 머티리얼(material) 을 처리할 수 있기 때문에, 한 warp 내 모든 스레드가 반드시 같은 신경망을 평가한다고 보장할 수 없다는 점이다. 이를 해결하기 위해, 우리는 두 가지 코드 경로(code path)를 생성한다:
•
발산(divergent) 실행에 최적화된 경로
•
일관(coherent) 실행에 최적화된 경로
셰이더는 warp 단위로 동적으로 어느 경로를 사용할지 선택한다.
•
발산(divergent) 경우:
GPU의 SIMT 모델에 의존하여 발산을 처리하며, 산술(arithmetic)과 메모리 로드(load) 명령어의 언롤(unrolled) 시퀀스를 생성한다.
대부분의 명령어는 MLP feedforward 레이어에서 큰 행렬 곱(matrix multiply) 을 평가하는 데 사용된다. 우리는 FMA (fused multiply-add) 명령을 활용하여, 두 개의 16비트 가중치를 한 번에 연산한다. 가중치는 메모리 접근 순서에 맞게 배열되어 있으며, 128비트 벡터화된 로드(vectorized loads) 를 생성하는 데 특별한 주의를 기울인다.
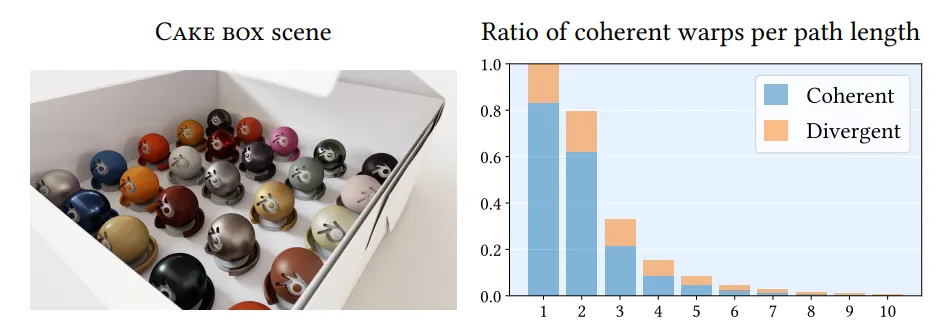
그림 14. 부분적으로 열린 케이크 상자(Cake box) 안에는 25가지 서로 다른 뉴럴 머티리얼(neural materials)이 들어 있다. 통계는, 긴 라이트 패스(light paths)를 따라 모든 버텍스에서 셰이더 실행 재정렬(Shader Execution Reordering, SER) 을 활용할 때, 우리의 메가커널 패스 트레이서(megakernel path tracer)가 높은 수준의 셰이딩 일관성(shading coherency) 을 달성한다는 것을 보여준다.
7.2 Tensor core acceleration
최근 GPU 아키텍처들은 행렬 곱(matrix multiplication) 연산을 가속하기 위한 하드웨어 유닛을 제공한다.
구현 세부 사항은 아키텍처마다 다르지만, 핵심 기능은 유사하다. 우리는 NVIDIA의 텐서 코어(tensor cores) 에 초점을 맞춘다. 텐서 코어는 여러 형태의 행렬 곱(matrix multiply) 명령어를 제공하는데, 같은 아이디어는 다른 아키텍처에도 적용 가능하다.
하지만 이 명령어들은 현재 컴퓨트 API 에만 제한되어 있으며, 셰이더(shaders) 에서는 노출되지 않는다.
이를 해결하기 위해, 우리는 LLVM 기반 오픈 소스 DirectX 셰이더 컴파일러를 수정하여 저수준 접근을 위한 사용자 정의 intrinsic 을 추가했다. 이 메커니즘을 통해 우리는 Slang 셰이더 코드에서 텐서 코어를 활용한 신경망 평가를 매우 효율적으로 수행할 수 있다.
텐서 코어는 가중치 행렬의 16 × 16 블록을 동시에 연산한다.
단, MMA(matrix multiply-accumulate) 명령어는 warp 전체가 협력(cooperation) 해야 한다.
따라서 이 빠른 경로(fast path)는 모든 쓰레드가 동일한 재질(material)을 평가하는 일관된(coherent) warps 에만 적용된다. 또한 네트워크 파라미터를 로드할 때도 일관된(coherent) 접근이 성능에 유리하다. 따라서 어떻게 coherent warps를 구성할 것인가가 중요한데, 이는 다음 절에서 논의한다.
7.3 Shading coherency
뉴럴 머티리얼(neural materials)을 사용하면, 네트워크 가중치와 잠재 텍스처(latent textures)만 교체함으로써 동일한 셰이더 코드로 다양한 재질을 재현할 수 있다.
이는 전통적으로 실행 발산(execution divergence) 이 심한 워크로드(예: 경로 추적, path tracing)에서도 warp 활용도(warp utilization) 와 성능을 향상시킨다.
하지만 데이터 발산(data divergence)의 증가는 메모리 시스템에 부담을 주며, 셰이딩 코히어런시(shading coherence)를 높여 성능을 추가로 개선할 수 있다.
•
기존 접근 (classical coherent approaches)
◦
예: 웨이브프론트 패스 트레이싱 (wavefront path tracing) [Laine et al. 2013; van Antwerpen 2011]
◦
각 bounce 후 히트(hit)를 메모리에 저장하고 전역적으로 재정렬한다.
◦
하지만 높은 메모리 대역폭 요구 때문에 성능이 근본적으로 제한된다.
•
최근 하드웨어 기능 (recent hardware features)
◦
Intel의 Thread Sorting Unit (TSU)
◦
NVIDIA의 Shader Execution Reordering (SER)
◦
이들은 작업(work)을 지역적으로 재정렬하여 효율을 높인다.
우리의 방법에서는 메가커널(megakernel) 패스 트레이서를 사용하여 경로(path)를 칩 온(on-chip)에 유지한다.
그리고 SER이 제공하는 데이터 코히어런시 증가 효과를 활용한다.
그림 14는 우리의 패스 트레이싱 아키텍처에서, 대부분의 warp가 완전히 코히어런트(모든 쓰레드가 동일한 재질을 셰이딩) 함을 보여준다.


8. Runtime Analysis and Results
품질과 성능을 연구하기 위해, 우리는 Falcor 렌더링 프레임워크 [Kallweit et al. 2022] 위에 구축된 실시간 패스 트레이서 [Clarberg et al. 2022a,b] 에 뉴럴 머티리얼 시스템을 구현하였다.
패스 트레이서는 다중 중요도 샘플링(MIS) [Veach and Guibas 1995] 기반의 넥스트 이벤트 추정(next-event estimation) 을 사용하며, 각 경로(path)는 eval, sample, evalPdf 머티리얼 인터페이스를 여러 번 호출한다.
우리 시스템은 Direct3D 12 위에서 DirectX Raytracing (DXR) 을 통한 하드웨어 가속 레이 트레이싱을 사용한다.
별도의 언급이 없는 한, 모든 결과는 NVIDIA GeForce RTX 4090 GPU 에서 1920×1080 해상도로 생성되었다.
우리는 뉴럴 머티리얼을 사용한 패스 트레이싱의 품질과 성능 평가에 집중하기 위해, 결과를 왜곡할 수 있는 디노이징 및 기타 기능은 비활성화하였다.
성능 측정 방법:
•
1920×1080 이미지를 픽셀당 경로 샘플 1개(1 SPP) 로 렌더링하는 데 걸린 총 시간(ms)으로 보고한다.
•
ms/SPP 시간은 실시간 패스 트레이싱을 대표하는 지표이며, 이를 선형적으로 확장해 더 높은 SPP가 필요한 경우(예: 고품질 프리뷰 렌더링)의 시간을 예측할 수 있다.
•
경로 길이(path length)는 최대 6개의 경로 정점(vertex) (카메라와 광원 포함)으로 제한했다.
•
측정 목적으로 러시안 룰렛(Russian roulette) 은 비활성화하였다.
참조 재질 (Reference materials):
•
우리는 풍부한 재질들을 연구하기 위해, MaterialX [Smythe and Stone 2021] 로 표현된 물리 기반 레이어드(material graph) 를 지원하도록 확장했다.
•
MaterialX는 VFX와 영화 제작에서 고충실도 재질(high-fidelity materials) 의 일반적인 교환 포맷이다.
•
이를 통해 Houdini 및 기타 도구에서 복잡한 레이어드 재질(그림 2 참조)을 제작할 수 있다.
•
모든 재질은 여러 BRDF를 믹싱(mixing) 또는 코팅(coating) 연산으로 조합해 구성된다.
•
거의 모든 파라미터는 텍스처화되어 있으며, 각 텍스처의 해상도는 4k~8k 수준이다.
•
일부 재질은 더 높은 해상도를 위해 최대 14개의 4k 텍스처 타일을 이어 붙인다.
•
우리는 참조 재질들을 프로그래밍 방식으로 변환하여, Slang 코드로 최적화된 셰이딩 그래프를 구현했다.
◦
이 그래프는 표준 BRDF 모델을 가중치(입사 방향 ωi\omega_iωi 의존) 기반으로 조합하는 구조이다.
•
각 재질은 여러 레이어로 이루어져 있으며, 각 레이어는 여러 텍스처에 의해 구동된다.
•
관련 통계는 표 1(Table 1) 에 제공된다.
8.1 Visual accuracy
그림 3에서는, 우리가 제안한 8채널 잠재 텍스처(latent texture) 로 파라미터화된 뉴럴 머티리얼과, 단순한 해석적 모델(확산 성분 + 등방성 Trowbridge-Reitz(GGX) 로브 조합)을 비교한다.
이 해석적 모델은 총 8채널의 텍스처에 의해 구동된다.
해석적 모델에 대해서는 두 가지 변형을 실험했다:
1.
수치적으로 최적화된 파라미터 – 우리의 기존 학습 파이프라인(뉴럴 머티리얼 학습용으로 조정됨)을 사용해 얻은 경우
2.
전문가가 수동으로 최적화한 파라미터
하지만 두 경우 모두 참조되는 다층 재질(multi-layered material)의 복잡성을 포착하지 못한다.
특히, 단순 해석적 모델의 확산 알베도(diffuse albedo) 는 세라믹 글레이징(ceramic glazing)의 뷰-의존 색(view-dependent color) 중 일부 단면(slice)만을 포착할 수 있다.
따라서 선택된 알베도와 일치하는 특정 시점(view direction)에서만 정확하다.
반면, 뉴럴 머티리얼은 참조를 더 충실하게 재현하며,
고품질이지만 느린 참조 모델과 저품질이지만 빠른 해석적 근사 모델 사이에서 속도와 품질의 균형을 이룬다.
그림 15와 16에서는, 뉴럴 BRDF 디코더의 세 가지 설정(configuration)에 대해 시각적 품질과 렌더링 성능을 비교한다.
(중요도 샘플러는 항상 은닉층 3개, 각 32 뉴런으로 구성된다.)
예상대로, 디코더 크기에 따라 품질이 달라진다.

그림 15. 잉크웰(Inkwell) 장면에서 금속 부분은 우리가 제안한 뉴럴 BRDF 를 사용하고, 나머지 부분은 해석적 BRDF 를 사용한다. 첫 번째 세 열은 BRDF 디코더의 크기(작은 → 큰) 에 따른 결과를 보여준다. 즉, 왼쪽은 가장 빠르지만 덜 정확한 설정이고, 오른쪽으로 갈수록 더 정확하지만 느린 설정이다. 각 이미지의 구석에는 다음이 포함된다: FLIP 오류 이미지1920×1080 해상도에서 픽셀당 1 샘플(1 SPP), 최대 경로 길이 6으로 렌더링했을 때의 렌더링 성능 모든 이미지는 8192 SPP 로 렌더링되어, 경로 추적(path tracing) 노이즈를 억제한 상태에서 비교된다.

그림 16. Stage 장면으로, 네 가지 재질을 우리가 제안한 뉴럴 BRDFs 로 근사(approximate)하였다. 레이아웃은 그림 15와 유사하다. 구석에는 FLIP 오류 이미지가 포함되어 있고, 수치는 1920×1080 해상도, 1 SPP, 경로 길이 최대 6 조건에서 장면을 렌더링하는 데 걸린 시간이다. 모든 이미지는 8192 SPP 로 렌더링되어, 경로 추적 노이즈를 억제한 상태에서 비교된다. 결과: 뉴럴 BRDF로 렌더링한 경우, 참조 재질 대비 전체 프레임 렌더링 시간이 1.64배 ~ 4.14배 더 빠르다. 수치는 그림 15와 여기(Fig. 16)에서의 뷰 평균 기준이다. 장면 및 조명 세팅에 대한 자세한 내용은 보충 문서(supplemental document) 를 참조하라.
•
가장 큰 설정(은닉층 3개, 각 64 뉴런)은 참조 재질을 잘 재현하며, 대부분의 디테일과 색을 정확히 잡아낸다.
•
오류는 주로 거의 정반사(near-specular) 재질의 글레이징 각(grazing angles) 에서 나타난다.
◦
예: 세라믹 티팟(Teapot) 본체의 실루엣 근처
여러 하이퍼파라미터 구성을 실험한 결과, 일부는 글레이징 각의 아티팩트를 줄이는 데 성공했으나 (예: L2L_2L2 손실 사용),
다른 영역의 품질이 저하되었으며, 경우에 따라 크게 저하되기도 했다.
이 “제로섬 게임(zero-sum game)”에서 벗어나기 위해, 우리는 프레넬 효과(Fresnel effects)를 처리할 새로운 그래픽스 사전 지식(prior) 이 필요하다고 주장하며, 이는 미래 연구로 남긴다.
우리는 FLIP [Andersson et al. 2020] 거짓 색상(false-color) 오류 이미지를 구석에 포함하여, 뉴럴 BRDF와 참조 BRDF 렌더링을 전환할 때 지각되는 차이를 시각적으로 보여주었다.
모든 이미지는 보충 자료(supplemental material)에 포함되어 있어, 이러한 검증을 직접 수행할 수 있다.
표 3에는 다양한 표준 이미지 오류 지표(image error metrics)를 이용한 평균 오류가 나와 있으며,
보충 자료에는 디코더 크기에 따른 학습된 재질의 극좌표 플롯(polar plots)도 포함된다.
Table 3. 이미지 에러 지표 (8192 SPP 기준, Fig. 15 & 16 평균)
BRDF 디코더 | Mean FLIP ↓ | Mean abs. error ↓ | Mean sqr. error ↓ | Mean rel. abs. error ↓ | Mean rel. sqr. error ↓ | SMAPE ↓ |
2×16 | 0.1087 | 0.0439 | 1.3855 | 0.1042 | 0.0353 | 0.1449 |
2×32 | 0.0551 | 0.0145 | 0.0107 | 0.0429 | 0.0056 | 0.0468 |
3×64 | 0.0444 | 0.0121 | 0.0101 | 0.0347 | 0.0035 | 0.0363 |
•
디코더가 커질수록 (2×16 → 3×64), 모든 오류 지표에서 점진적 개선
•
특히 FLIP, 절대/상대 오류, SMAPE 값이 뚜렷하게 낮아짐
•
하지만 2×16 → 2×32 전환이 가장 큰 개선폭, 3×64는 소폭 추가 향상
Table 4. 전체 프레임 성능 (ms/SPP, Importance Sampler = 3×32 고정)
장면 & 뷰 | 2×16 | 2×32 | 3×64 | Ref. (기준) |
Inkwell, View 1 | 3.64 (4.01×) | 4.36 (3.34×) | 9.94 (1.47×) | 14.58 |
Inkwell, View 2 | 3.26 (4.71×) | 4.16 (3.69×) | 10.93 (1.41×) | 15.36 |
Stage, View 1 | 3.15 (4.21×) | 3.71 (3.57×) | 6.31 (2.10×) | 13.25 |
Stage, View 2 | 3.30 (4.33×) | 4.32 (3.31×) | 7.67 (1.86×) | 14.29 |
Stage, View 3 | 4.29 (4.66×) | 5.73 (3.49×) | 11.02 (1.81×) | 19.98 |
Stage, View 4 | 3.49 (4.74×) | 4.39 (3.77×) | 8.68 (1.90×) | 16.53 |
Stage, View 5 | 3.45 (2.26×) | 4.12 (1.89×) | 7.68 (1.01×) | 7.78 |
평균 | 3.51 (4.14×) | 4.40 (3.31×) | 8.89 (1.64×) | 14.54 |
•
성능: 작은 디코더일수록 빠름 (2×16이 평균 4.14배 속도 향상)
•
품질: 큰 디코더(3×64)는 품질은 가장 좋지만, 속도는 1.64배로 상대적 향상폭이 낮음
•
트레이드오프:
◦
2×16 → 빠르지만 품질 떨어짐
◦
3×64 → 품질 최고, 성능 향상은 제한적
◦
2×32 → 품질과 성능의 균형점
8.2 런타임 성능
가장 작은 네트워크가 최고의 렌더링 성능을 제공하지만, 재구성 정확도는 떨어진다.
Table 4는 ms/SPP 단위의 절대 성능과, GPU 최적화된 참조 재질을 렌더링했을 때 대비 상대적인 속도 향상을 보여준다 (모두 NVIDIA GeForce RTX 4090 GPU에서 실행).
뉴럴 BRDFs를 사용한 전체 프레임 렌더링 시간은 평균적으로 참조 재질보다 1.64× (3×64) ~ 4.14× (2×16) 더 빠르다.
Table 5.
두 가지 서로 다른 BRDF 디코더 아키텍처에서의 재질 셰이딩 성능(ms/SPP). (중요도 샘플러는 항상 3 × 32).
열 라벨은 은닉층(hidden layer)의 개수와 너비를 나타낸다.
괄호 안 숫자는 참조 재질(마지막 열)에 대한 속도 향상을 의미한다.
장면 & 뷰 | 2 × 32 | 3 × 64 | Ref. |
Stage, View 3 | 1.59 (10.19×) | 6.02 (2.69×) | 16.21 |
Stage, View 4 | 1.23 (12.82×) | 5.06 (3.12×) | 15.77 |
Inkwell, View 1 | 1.59 (6.99×) | 6.01 (1.85×) | 11.11 |
Inkwell, View 2 | 1.74 (7.25×) | 7.15 (1.76×) | 12.61 |
Average | 1.54 (9.06×) | 6.06 (2.30×) | 13.93 |
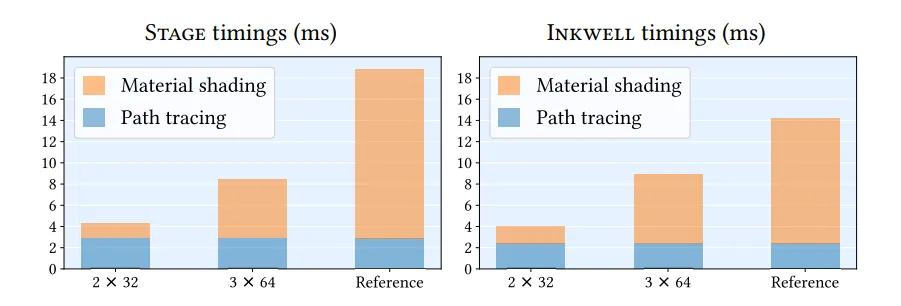
그림 17. 1920×1080 해상도에서 1 SPP 이미지를 렌더링할 때, 경로 길이를 최대 6개의 정점(path vertex)까지 사용하는 경우의 평균 경로 추적(path tracing) 시간과 재질 셰이딩(material shading) 시간(ms 단위). 두 가지 서로 다른 BRDF 디코더 아키텍처가 프로파일링 되었으며, 참조 재질(reference materials)을 이용한 셰이딩 비용과 비교되었다.
프레임 시간(frame time)은 일반적인 패스 트레이싱 연산(광원 샘플링, 레이 트레이싱, 제어 로직)과 재질 샘플링 및 평가(material sampling & evaluation) 를 모두 포함한다.
메테리얼 셰이딩(material shading) 에 얼마나 많은 시간이 소요되는지, 그리고 따라서 우리의 뉴럴 재질(neural materials) 이 참조 재질(reference materials) 대비 얼마나 속도 향상을 가져오는지 추정하기 위해, 우리는 전용 벤치마크를 구성했다.
우리 시스템의 모든 뉴럴 재질 셰이더는 렌더러 내부에서 인라인으로 실행되며, 별도의 커널로 동작하지 않기 때문에 이 과정은 주의 깊게 이루어져야 한다.
•
경로 분포(path distribution)를 단순한 코사인 가중 분포(cosine-weighted distribution) 로 고정하고,
•
컴파일러가 어떤 재질 코드를 최적화 과정에서 제거하지 않도록 보장하였다.
베이스라인(baseline) 으로는, 상수 색상(constant color) 을 가진 재질을 사용하여 순수한 패스 트레이싱 비용만 측정하였다.
Table 5와 Figure 17은 Inkwell 장면(Figure 15, View 1 & 2) 과 Stage 장면(Figure 16, View 3 & 4) 에 대한 대표적인 뷰 두 가지의 결과를 요약한다.
뉴럴 BRDFs를 사용한 셰이딩 시간은 평균적으로 참조 재질 대비 2.30× (3×64)에서 9.06× (2×32)까지 더 빠르며, 일부 뷰에서는 중간 크기의 BRDF 디코더(2×32)에서 10배 이상의 가속을 달성하였다.
종합적으로, 성능과 시각적 충실도(visual fidelity)는 예측 가능한 방식으로 스케일링하며, 뉴럴 BRDFs는 품질과 성능 간의 트레이드오프를 유연하게 조절할 수 있다.
다음 섹션에서는 이러한 스케일링 동작(scaling behavior)을 더 자세히 분석한다.
8.3 Scalability
그림 18은 뉴럴 재질의 수를 증가시킬 때 성능이 유리하게 확장됨을 보여줍니다. 이 테스트에서는 케이크 박스 장면(그림 14)을 렌더링하고 기하학적 구조와 경로 분포를 동일하게 유지하면서 (서로 다른) 뉴럴 재질의 수를 변경했습니다. 최대 열 개의 꼭지점 길이를 가진 경로가 추적되며, 이 장면에는 상당한 실행 및 데이터 분기를 도입하기 위해 소수의 전통적인 재질도 포함되어 있습니다.
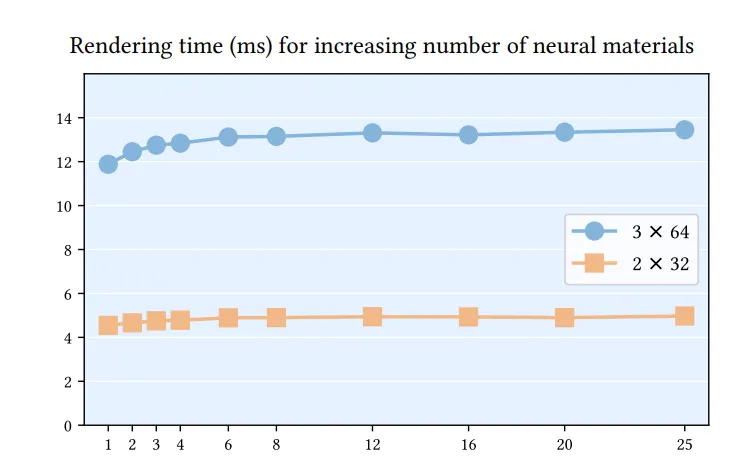
그림 18. Cake box 장면을 1 SPP 이미지로 패스 트레이싱할 때, 뉴럴 재질(neural materials)의 개수를 달리하여 측정한 렌더링 시간. 측정 결과는, 우리가 제안한 방식이 많은 수의 뉴럴 재질을 포함하는 장면을 패스 트레이싱할 때 발생하는 발산(divergence) 에 민감하지 않음을 보여준다. 즉, 재질의 개수가 증가해도 렌더링 시간은 거의 일정하게 유지된다. 여기서는 두 가지 서로 다른 BRDF 디코더 아키텍처를 실험 대상으로 하였으며, 성능에 대한 재질 개수 확장의 영향을 분리하기 위해 경로 분포(path distribution) 는 고정된 상태로 유지하였다.
아주 적은 수의 뉴럴 재질일 경우, 네트워크 파라미터는 셰이더 코어 근처의 캐시에 들어가지만, 재질이 많아질수록 파라미터는 점점 L2 캐시나 글로벌 메모리에서 스트리밍된다.
우리의 메가커널 패스 트레이서(megakernel path tracer) 기반 접근법은 로컬 작업 재정렬(local work reordering) 을 통해 충분한 코히어런시(coherency)를 확보하여 메모리 로드 비용을 효과적으로 상쇄(amortize)한다.
Memory usage. 메모리 풋프린트는 주로 8채널, 하프 프리시전(half-precision) 잠재 텍스처(latent texture) 가 차지하며, 4K 텍스처 타일당 256MB가 필요하다.
네트워크 가중치(network weights)는 상대적으로 매우 작다.
•
3×64 네트워크 구성: 37KB
•
2×16 네트워크 구성: 9.3KB
Discussion. 직접적인 이전 연구와의 비교는 어렵다. 우리의 초점은 다르기 때문이다. 우리는 뉴럴 재질이 패스 트레이싱처럼 발산(divergent)이 심한 워크로드에서도 실시간 셰이더 안에서 효율적으로 동작할 수 있음을 보인다.
전통적 셰이더에서 추론(inferencing) 이 실행된 사례는 거의 없다. 예외적으로 Nalbach et al. (2017)의 Deep Shading 은 GLSL에서 전통적인 디퍼드 셰이딩을 위해 한 번의 forward pass를 실행했다.
뉴럴 어피어런스 모델 연구들은 보통 CUDA 커널을 직접 사용하거나 머신러닝 프레임워크를 통해 실행되었다.
•
Fan et al. (2022): 모든 교차(intersection)를 글로벌 메모리에 기록하고, 디퍼드 방식으로 셰이딩. 이로 인해 적응성(adaptiveness)을 잃고 메모리 전송 비용을 지불한다. 저자들은 1920×1080 해상도에서 NVIDIA RTX 2080Ti로 픽셀당 단일 BRDF 평가 비용이 5ms라고 보고했다.
•
NeuMIP (Kuznetsov et al. 2021): 인터랙티브 CUDA/OptiX 기반 패스 트레이서를 구현했고, 동일 해상도/GPU 조건에서 5ms per evaluation의 유사한 성능을 보고했다. 그러나 세부 내용은 부족하다. 개인적 소통에 따르면, 보고된 60FPS 패스 트레이싱은 비교적 짧은 경로와 단일 재질을 가진 단순 장면에 적용된 것이며, 다중 재질(multiple materials) 로의 확장은 다루지 않았다.
우리는 스케일링 가능성(scalability), 발산 셰이더 처리(divergent shader handling), 그리고 실시간 셰이딩 언어(real-time shading languages)와의 통합 이 뉴럴 재질을 더 널리 채택할 수 있도록 하는 중요한 기여라고 믿는다.
9 LIMITATIONS & FUTURE WORK
에너지 보존(Energy conservation)과 상호성(Reciprocity).
뉴럴 재질은 입력 재질을 근사적으로 맞춘 것에 불과하기 때문에, 에너지 보존(energy conserving) 이 보장되지 않는다.
테스트에서는 문제를 발견하지 못했지만, 고반사율(albedo) 재질이나 다중 반사(bounce)가 많은 경우(예: 흰색 털)에는 문제가 될 수 있다.
에너지 보존을 강제하려면 네트워크 출력이 해석적으로 적분 가능한 형태이거나 알려진 값으로 적분되는 형태여야 한다.
후자는 [Müller et al. 2020]과 같이 노멀라이징 플로우(normalizing flows) 를 사용하면 가능하지만, 평가 비용이 증가한다.
현재 BRDF 모델은 상호성(reciprocity) 을 보장하지 않지만, [Zheng et al. 2021]의 Rusinkiewicz 방향 인코딩 수정 버전을 사용하면 강제할 수 있다.
우리는 실험에서 수치적으로 더 안정적이고 시각적으로 더 나은 결과를 주는 Cartesian 방향 매개변수화를 선택했다.
Displacement
현재 우리는 표면 기하에 영향을 주는 효과(예: 디스플레이스먼트 매핑)는 지원하지 않는다.
[Kuznetsov et al. 2021]의 뉴럴 디스플레이스먼트 접근법을 구현하고, 기하 priors를 포함한 여러 변형을 테스트했지만, 이 접근법은 항상 고정 기능(fixed-function) 레이 마칭(ray marching) 에 비해 성능과 대역폭 측면에서 열세였다.
어떤 접근법도 우리의 실시간 성능 목표를 충족할 만큼 충분히 빠르지 않았지만, 향후 추가 연구를 통해 실행 가능한 대안이 될 수 있다고 본다.
Filtering
뉴럴 프리필터링은 앨리어싱 방지에는 효과적이지만, 보고된 바에 따르면 가장 세밀한 레벨(fine level) 은 매우 정확한 반면, 잠재 피라미드(latent pyramid)의 더 거친 레벨에서는 슈퍼샘플링된 참조 BRDF보다 더 부드럽게(softer) 보이는 경향이 있다.
이는 인코더 입력이 가장 세밀한 레벨에서는 외관(appearance)과 강하게 상관되지만, 거친 레벨에서는 프리필터된 재질 파라미터를 소비하므로 상관성이 약해져서 오토인코더 성능이 떨어지기 때문으로 보인다.
파인튜닝은 어느 정도 품질을 개선하지만, 초기의 로컬 미니멈(local minimum)을 완전히 극복하지는 못한다.
Alternative geometric priors
우리는 회전 prior(섹션 4.2)에 대해 다양한 구현을 테스트했다.
•
제약 없는 고차원 아핀 변환(self-attention 레이어의 일반성에서 영감을 얻음 [Vaswani et al. 2017])부터
•
순수 회전 행렬(rotation-only matrices) 까지 실험했다.
최종적으로는 네트워크 출력에서 정규화된(orthogonal은 아님) 법선 n과 탄젠트 t를 사용하고, 비탄젠트 b = n × t / ∥n × t∥ 로 계산하는 방식을 채택했다.
또한, 추출된 TBN 프레임을 참조 재질의 프레임과 비교하여 명시적으로 지도(supervision)하는 방식도 테스트했으며, 비대칭 손실(asymmetric loss) [Vogels et al. 2018]을 추가하기도 했다.
이 방식은 가끔 (예: glints) 결과를 개선했지만, 훈련 시 광범위한 하이퍼파라미터 튜닝이 필요했기 때문에 최종 결과에는 포함하지 않았다.
학습 안정성(Training stability)과 시간(Time).
우리는 가끔 학습이 로컬 미니멈(local minima) 에 수렴하는 경우를 발견했는데, 이는 작은 하이퍼파라미터 변화나 가중치 초기화 차이에 따라 큰 시각적 차이(visual differences) 를 만들어냈다.
예를 들어, 가장 작은 네트워크 구성은 Teapot의 강한 스펙큘러 유약(specular glazing) 을 안정적으로 재현할 수 없어서, 우리는 결과(Figure 16)에 해당 구성의 버전을 포함하지 않기로 했다.
우리는 향후 더 다양한 목표 재질(target material diversity)로 확장할 때도 강건성(robustness) 을 면밀히 조사하고자 한다.
동시에 학습 시간을 크게 줄여(이상적으로는 몇 시간 → 몇 분) 반복(iteration) 시간을 개선하여, 시스템의 현재 버전을 더 실용적으로 만들고, 향후 개선 연구 개발 과정도 더 원활하게 하고자 한다.
굴절(Refraction)
우리는 현재 방법을 순수 반사 재질(purely reflective materials) 에 대해서만 평가했다.
이를 투명/굴절 재질(transmissive materials) 로 확장하는 데는 다음과 같은 도전 과제가 있다:
물리 기반 렌더러에서는 굴절 후에도 상호성(reciprocity) 을 유지하기 위해 굴절률(index of refraction, IOR) 을 알아야 한다.
네트워크가 이 굴절률을 추가 출력값으로 학습하도록 할 수는 있지만, 이 학습된 값이 실제 BRDF의 거동과 일치한다고 보장하기 어렵다.
따라서 이 주제는 향후 연구에서 특별히 다뤄져야 한다.
10 CONCLUSION
우리는 완전한 실시간 뉴럴 재질 시스템(real-time neural materials system) 을 제시한다.
이 모델은 매우 복잡하고 세밀한 재질의 평가(evaluation), 샘플링(sampling), 필터링(filtering) 을 동시에 해결한다.
우리는 기존 연구의 아이디어를 새로운 그래픽 priors 및 학습 전략과 결합하여 더 높은 품질과 더 빠른 학습 속도를 달성하였다.
우리 연구의 핵심 기여는 이러한 포괄적인 솔루션이 최신 그래픽 하드웨어에서도 효율적으로 구현될 수 있다는 점이다.
우리는 대역폭 요구를 줄이기 위해, 뉴럴 네트워크를 렌더링 루프의 가장 안쪽(inmost rendering loop)에 배치할 것을 제안한다.
실험에서, 뉴럴 BRDFs는 최신 GPU에서 최적화된 참조 멀티 레이어 고전 재질 구현을 능가하며, 장면 내 다중 재질에도 스케일링된다.
우리는 제안한 뉴럴 BRDFs가 복잡한 재질의 “구워진(baked)” 버전 역할을 할 수 있다고 믿는다.
즉, 성능 향상과 메모리 사용량 절감뿐 아니라, 고정된 잠재 텍스처 집합과 소규모 MLP 가중치 테이블만 교환하면, 任의 복잡성을 가진 재질을 다양한 워크플로우와 툴 간에 손쉽게 교환할 수 있게 된다.
마지막으로, 우리는 이 논문이 실시간 렌더링에서 소규모 뉴럴 네트워크의 채택을 촉진하기를 희망한다.
감사의 글 (ACKNOWLEDGMENTS)
•
참조 객체 제작에 도움을 준 Toni Bratincevic, Davide Di Giannantonio Potente, Kevin Margo 에게 감사한다.
•
Slang 언어를 이 프로젝트에 맞게 발전시킨 Yong He,
•
3D 에셋 임포터 지원을 도와준 Craig Kolb,
•
저수준 컴파일러 및 GPU 드라이버 지원을 해준 Justin Holewinski, Patrick Neill,
•
Slang에서 TensorCore 지원을 제공한 Karthik Vaidyanathan 에게도 감사한다.
또한, 귀중한 의견을 제공한 Eugene d’Eon, Steve Marschner, Thomas Müller, Marco Salvi, Bart Wronski 에게도 감사를 전한다.
Figure 14의 material test blob은 Robin Marin이 제작하였으며, CC 라이선스(https://creativecommons.org/licenses/by/3.0/) 하에 배포되었다.
A. IMPORTANCE SAMPLING DETAILS
아래는 우리가 사용한 해석적 대리 모델(analytic proxy model) 기반 중요도 샘플링 구현의 세부 내용이다.
확률 밀도 (Probability density)
이전 연구 [Fan et al. 2022; Sztrajman et al. 2021]와 같이, 샘플링 밀도는 확산(diffuse) 항과 스펙큘러(specular) 항의 선형 혼합(linear blend)으로 표현된다.
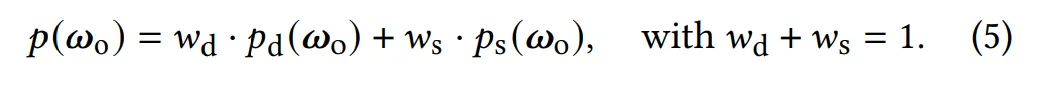
•
확산 PDF 는 코사인 가중 분포(cosine-weighted distribution)이며, 예측된 2D 표면 기울기 로부터 계산된 법선 벡터에 의해 기울어진다.
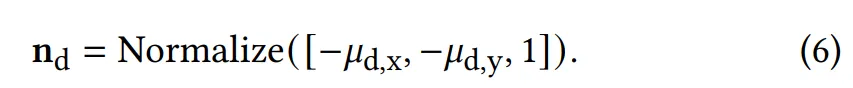
•
스펙큘러 PDF 는 Trowbridge-Reitz (GGX) NDF [Trowbridge and Reitz 1975; Walter et al. 2007]를 사용한 표준 마이크로패싯 분포로, 타원 비등방성(elliptical anisotropy)과 비중심 평균 표면 기울기(non-centered mean surface slopes) [Dupuy 2015]를 포함한다.
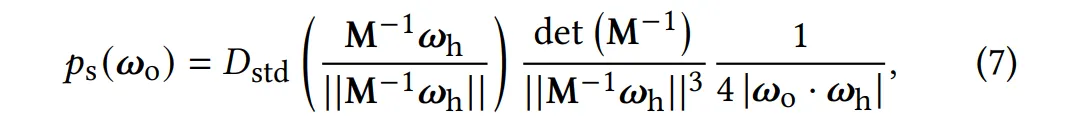
여기서, 는 half vector이고,
는 단위 거칠기(roughness )를 가진 등방성 NDF이다.
변환 행렬 은 다음과 같다:
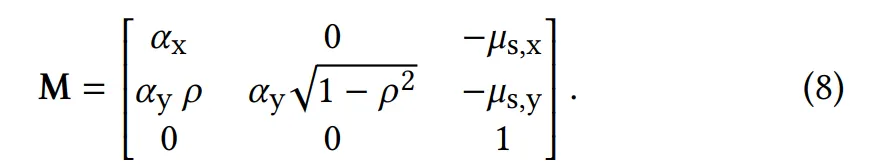
여기서:
•
타원 비등방성(elliptical anisotropy)은 두 개의 직교 거칠기 값 와 상관 계수 로 표현된다.
•
NDF의 평균은 2D 표면 기울기 로 오프셋된다.
식 (7)의 마지막 두 항은:
•
의 변환 및 정규화(normalization)
•
와 사이의 변수 변환(change of variables)을 보정하기 위한 Jacobian 행렬식이다.
샘플링 (Sampling)
샘플 변환 $W$는 먼저 식 (5)에 따라 두 PDF 항 중 하나를 선택한다.
•
Diffuse 선택 시:
◦
코사인 가중 분포로부터 출사 방향 를 생성하고, 에 따라 기울인다.
•
Specular 선택 시:
◦
샘플링된 half-vector에 대해 스펙큘러 반사를 수행한다.
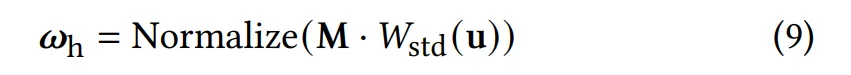
여기서 는 등방성 NDF ()의 표준 샘플링 기법이다.
네트워크 예측 (Network prediction)
위에서는 간결성을 위해 와 의 와 의존성을 생략했지만,
전체 대리 파라미터 집합은 다음과 같다: 이들은 모두 MLP 평가 결과로 나온다.
•
모든 추론된 파라미터가 유효한 범위에 속하도록 하기 위해,
◦
,
◦
,
◦
각각에 대해 tanh(x), sinh(x)의 이차 근사(quadratic approximation)를 활용한 최종 활성화 함수를 적용한다.
•
마지막으로 와 는 softmax 함수로 처리하여, 합이 1이 되는 유효한 혼합 가중치를 형성한다.
참고문헌