


1. Abstract: Realtime Neural Appearance Models
본 논문은 오프라인 렌더링에서만 가능한 복잡했던 외형을 실시간으로 렌더링하는 새로운 시스템을 제시합니다. 핵심 아이디어는 계층적 텍스처(Hierarchical textures)를 신경 디코더(neural decoder)를 사용 하여 해석함으로써 반사값과 중요도 샘플링된 방향을 생성하는 것입니다. 디코더의 모델링 능력을 최적으로 활용하기 위해 두 가지 방법이 필요합니다.
첫 번째는 사전에 방향을 학습된 셰이딩 프레임(learned shading frames)으로 변환 하는 것으로, 이는 중간 규모 효과(mesoscale effects)의 정확한 재구성을 도와줍니다.
두 번째 사전 지식인 마이크로패싯 샘플링 분포(microfacet sampling distribution)는 신경 디코더가 중요도 샘플링을 효율적으로 수행하도록 돕습니다. 이렇게 생성된 외형 모델은 이방성(anisotropic) 샘플링과 세부 수준(level-of-detail, LOD) 렌더링을 지원합니다. 또한 심층적으로 계층화된 머티리얼 그래프(material graphs)를 압축된 통합 신경 표현(unified neural representation)으로 베이킹(baking)할 수 있습니다.
시스템 수준 구현
하드웨어 가속 텐서 연산을 레이 트레이싱 셰이더에 노출하여 실시간 패스 트레이서 내에서 신경 디코더를 효율적으로 실행합니다. 신경 머티리얼 수가 증가할 때의 확장성을 분석하고, 일관된(coherent) 실행과 분산된(divergent) 실행에 최적화된 코드를 사용해 성능을 향상시킵니다. 이 신경 머티리얼 셰이더는 비신경 계층화 머티리얼보다 10배 이상 빠르며, 게임과 라이브 프리뷰 같은 실시간 애플리케이션에서 영화 품질의 시각 효과를 구현합니다.
모델 구조
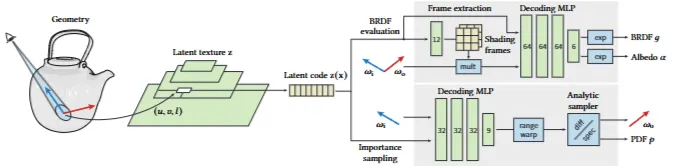
모델은 인코더, 신경 잠재 텍스처, 두 개의 디코더로 구성됩니다. 인코더는 BRDF 파라미터(알베도, 노멀 맵 등)를 잠재 공간으로 매핑하여 전통적인 텍스처 세트를 단일 다채널 잠재 텍스처로 변환합니다. 이는 고해상도 텍스처를 사용하는 머티리얼 지원에 핵심적입니다.
잠재 텍스처는 두 개의 네트워크로 디코딩됩니다. 평가 네트워크는 주어진 방향 쌍에 대한 BRDF 값을 추론합니다. 샘플링 네트워크는 무작위 숫자를 샘플링된 방향으로 매핑합니다.
BRDF 디코더는 잠재 코드 z(x)에서 두 개의 셰이딩 프레임을 추출합니다. 입사 및 반사 방향 를 각 프레임으로 변환한 후, 변환된 방향과 를 MLP에 전달하여 BRDF 값을 예측합니다. 중요도 샘플러는 분석적 2-lobe 분포의 파라미터를 추출합니다. 이를 사용하여 나가는 방향 를 샘플링하고 PDF 를 평가합니다.
학습 과정

인코더는 머티리얼 파라미터 (알베도, 거칠기, 노멀 맵 등)를 입력받아 잠재 벡터 를 출력합니다. 디코더가 수렴하면 인코더를 제거하고, 모든 텍셀에 대해 인코더를 평가하여 잠재 텍스처를 초기화합니다. 이후 디코더를 통한 역전파로 잠재 텍스처를 직접 학습합니다.
학습 데이터는 대상 머티리얼의 UV 공간에서 균일하게 샘플링됩니다. 필터링 효과를 구현하기 위해 계층적 텍스처의 각 MIP 레벨에 해당하는 프리필터링된 머티리얼 파라미터를 사용합니다. BRDF 예측은 로그 공간에서 손실로 최적화되고, 샘플러의 PDF는 학습된 BRDF에 대한 KL 다이버전스로 최적화됩니다.
런타임 시스템
신경 머티리얼 설명을 최적화된 셰이더 코드로 컴파일하며, Slang 셰이딩 언어를 사용하여 Vulkan, Direct3D 12, CUDA와 같은 다양한 타겟을 지원합니다. GPU의 SIMT 실행 모델을 처리하기 위해 다이버전트 및 코히어런트 실행에 최적화된 두 가지 코드 경로를 생성하며, 셰이더는 동적으로 워프당 경로를 선택합니다.
NVIDIA Tensor Cores와 같은 하드웨어 가속 행렬 곱셈 누적 연산을 활용하기 위해 커스텀 명령어를 사용하여 저수준 접근을 구현합니다. 또한 NVIDIA의 Shader Execution Reordering과 같은 기능을 활용하는 메가커널 패스 트레이서를 사용하여 셰이더 실행 효율을 높이고 메모리 접근 비용을 줄입니다.
실험 결과
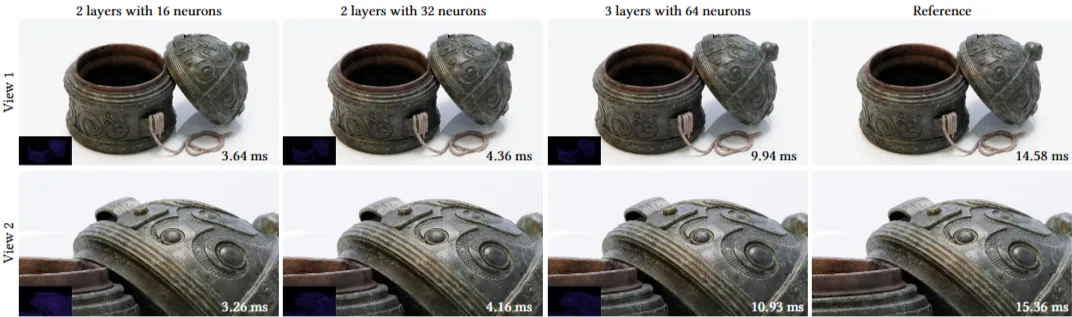
제안된 신경 머티리얼은 단순한 분석적 모델보다 복잡한 다중 레이어 머티리얼의 시각적 복잡성을 훨씬 더 충실하게 재현합니다. 특히 시야각에 따라 변화하는 색상 같은 미묘한 효과를 잘 포착합니다. 가장 큰 신경망 구성(은닉 레이어 3개, 각 64개 뉴런)은 참조 머티리얼을 매우 정확하게 재현합니다.
전체 프레임 렌더링 시간은 참조 머티리얼보다 평균 1.64~4.14배 빠릅니다. 머티리얼 셰이딩 시간은 2.30~9.06배 빠릅니다. 신경 머티리얼 수가 증가해도 렌더링 시간이 거의 일정하게 유지되어 높은 확장성을 보입니다.
복잡한 머티리얼의 베이크된 버전으로 사용할 수 있으며, 성능 향상과 메모리 소비 감소는 물론 다양한 워크플로우 및 도구 간의 복잡한 머티리얼 교환을 용이하게 합니다.
Neural Appearance Models의 목표
재질의 시각적 특성(거칠기, 미세구조, 코팅층, 산란/흡수, 간섭 등)을 조명과 시점 변화에 따라 실시간으로 재현하는 것입니다.
이 관점에서 관련 기술들은 대체로 다음 스펙트럼 위에 위치합니다.
•
물리 모수 표현(Parametric BRDF)  데이터 기반 잠재표현(Latent / Neural)
데이터 기반 잠재표현(Latent / Neural)
데이터 기반 잠재표현(Latent / Neural)•
정확도(physical fidelity) 실시간성(real-time)
실시간성(real-time)•
단층 재질(single-layer) 다층/복합 재질(layered / complex)
다층/복합 재질(layered / complex)•
텍스처/패치 공간(texture/patch-space) 입사·반사 각도 공간(angular / 4D half-angle)
입사·반사 각도 공간(angular / 4D half-angle)RT-NAM의 위치
RT-NAM은 데이터 기반 잠재표현, 실시간성, 복합 외관 쪽으로 강하게 치우친 최신 접근법입니다.
2. Baseline : Real-Time Neural Appearance Models (RT-NAM, 2024)
핵심 아이디어
•
재질을 잠재 텍스처(latent textures) 와 경량 디코더(shading decoders) 로 분해하여, GPU에서 실시간으로 평가 가능한 신경 셰이더(neural shaders) 를 구성.
•
그래픽스 파이프라인 친화적: LOD, 중요도 샘플링, 그래프 기반 머티리얼 구성 등 엔진 호환성을 중시.
•
고급 외관 효과(코팅·미세구조·광택 스트리크 등)를 신경 분포가 대체/보완하며, 비신경(기존) 셰이더 대비 품질/메모리/속도 절충을 개선.
Real-time Neural Appearance Models의 주요 장점
영화 품질의 시각적 사실성 구현
뛰어난 런타임 성능 및 효율성
확장성 및 다중 재질 처리
효과적인 중요도 샘플링 및 Level-of-Detail 렌더링
그래픽스 Prior를 통한 모델 표현력 강화
실용적인 훈련 절차
다양한 활용 가능성
종합적으로 이 논문은 실시간 렌더링 분야에서 영화 같은 재질을 효율적으로 처리하는 중요한 기술적 진보를 이끌어냈습니다.
문제점 및 단점
에너지 보존 및 상호성 불완전
변위 매핑 미지원 및 성능 한계
필터링된 MIP 레벨의 정확도 저하
훈련 안정성 및 시간
Fresnel 효과 처리의 한계
굴절 미지원
3. Compare Related Research
3.1 Deep Appearance Prefiltering
"Deep Appearance Prefiltering" 논문은 복잡한 3D 환경의 외형을 다중 스케일 레벨 오브 디테일(LoD)로 사전 필터링하는 최초의 딥 러닝 프레임워크를 제시합니다. 기존 물리 기반 렌더링은 복잡한 장면에서 계산 비용이 매우 높아 증강/가상 현실(AR/VR), 게임, 영화 산업에서 실시간 사용이 어려웠습니다. 기존 사전 필터링 LOD 방법론은 세 가지 주요 한계가 있었습니다: 지원하는 재료의 종류가 제한적이고, 근사 모델에 의존하며, 미시적 기하학(microgeometry)과 거시적 기하학(macrogeometry)의 이질적인 표현 사이에서 선택해야 해 매끄러운 외형 전환이 어려웠습니다.
본 연구는 이러한 한계를 극복하기 위해 SVO(Sparse Voxel Octree)를 데이터 구조로 사용하는 다중 스케일 계층적 복셀(voxel) 표현을 제안합니다. 초기 오프라인 데이터 생성 단계에서는 레이 트레이서(ray tracer)로 각 복셀 내의 광 전송(light transport)을 캡처합니다. 캡처된 정보는 appearance phase function , directional coverage mask , albedo 로 인코딩된 경량 latent representation으로 변환됩니다. 런타임에는 원본 기하학, 재료, 텍스처 없이 미리 학습된 신경망 추론(inference)만으로 이 잠재 표현을 디코딩하여 장면을 렌더링합니다..

핵심 방법론:
1.
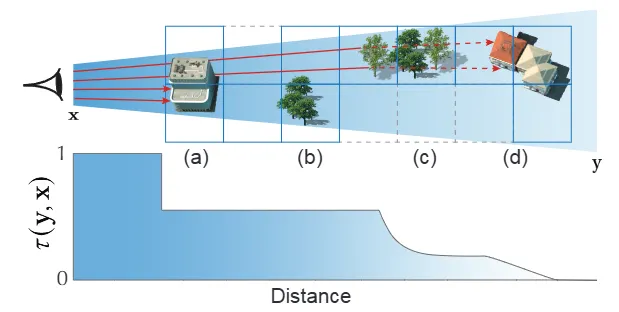
공간 표현 (Spatial Representation): 장면은 월드 공간에서 균일하게 이산화되며, 다중 스케일 희소 복셀 옥트리(SVO)로 표현됩니다. 스케일이 높아질수록 각 차원의 해상도가 두 배씩 증가합니다. 렌더링 시에는 픽셀 필터링 커널(pixel filtering kernel)의 bandlimiting frequency를 넘지 않도록 LoD 스케일이 결정됩니다.
2.
데이터 생성 (Data Generation): 각 LoD 스케일의 모든 복셀에 대해 phase function, albedo, coverage mask를 계산합니다.
•
Phase Function : 복셀을 통해 빛이 산란되는 방식을 나타냅니다. 들어오는 방향 와 나가는 방향 의 쌍을 구면 좌표계로 매개변수화한 고해상도 4D uniform grid로 표현됩니다. 레이 트레이서로 특정 뷰 방향에서 장면의 투영된 단면(projected cross-section)을 샘플링합니다. 그런 다음 복셀을 통과하여 환경 맵에 도달하는 샘플의 누적 radiance를 기록하여 계산합니다.
•
Albedo : 특정 나가는 방향에 대한 phase function의 평균 RGB 기본 색상(diffuse color)입니다. 2D 구면 좌표계로 매개변수화됩니다. 네트워크 최적화를 돕고 저장 비용을 줄이기 위해 phase function과 분리됩니다.
•
Coverage Mask : 고정 해상도(예: 16×16)의 2D 공간 마스크입니다. 빔을 따라 이전 복셀과의 상관 관계를 기반으로 복셀의 기여도를 결정하는 데 사용됩니다. 각 샘플이 복셀 내의 기하학과 교차했는지 여부를 기록하여 생성됩니다.
3.
사전 필터링된 광 전송 (Prefiltered Light Transport): 볼륨 렌더링 방정식(Volume Rendering Equation, RTE)을 기반으로 합니다. 픽셀의 spatio-angular footprint에 걸쳐 radiance를 통합하는 pixel filter 를 사용하여 최종 flux 를 계산합니다.
여기서 는 emission, 는 in-scattering, 는 boundary 항입니다.
•
In-scattering Term : 볼륨 내에서 산란된 빛의 기여도를 나타냅니다. far-field assumption(복셀이 충분히 멀리 떨어져 있어 빔 내의 레이가 거의 평행하다고 가정)과 transmittance separation 기법 을 적용하여 근사화합니다. 여기서 는 prefiltered transmittance function, 는 prefiltered phase function입니다.
•
Transmittance : exponential transmittance 모델은 watertight surface나 aggregate에 적합하지 않습니다. 따라서 deep shadow maps와 유사하게 2D spatial coverage mask 를 사용하여 빔을 따라 다양한 transmittance mode를 수치적으로 모델링합니다. 런타임에는 빔의 tracked coverage 를 계산하여 복셀의 기여도를 결정합니다.
1.
신경망 압축 및 디코딩 (Neural Compression and Decoding):
•
인코더 (Encoders): 4D phase function, 2D coverage mask, 2D directional albedo 테이블을 compact latent representation으로 압축하여 효율적으로 저장하고 접근합니다. CNN으로 구성되며, 2D slice(고정된 나가는 방향에 대한 모든 들어오는 방향의 처리량)를 개별적으로 처리한 후 결과 latent vector를 연결합니다.
•
디코더 (Decoders): 런타임에 latent vector와 방향 쿼리(나가는/들어오는 방향)를 사용하여 원본 데이터의 특정 요소를 재구성합니다. fully connected layer로 구성되며, 원본 데이터의 작은 부분(예: 단일 값)만 출력하여 메모리 사용량을 최소화합니다. phase network는 단일 스칼라 처리량 값을, phase-slice network는 특정 뷰 방향에 대한 모든 들어오는 방향의 처리량 2D 이미지를, coverage network는 2D coverage mask를, albedo network는 RGB 기본 색상을 출력합니다.
•
입력 매개변수화: coordinate frame을 전역 월드 공간 대신 뷰 방향의 local space로 재매개변수화하고, positional encoding을 적용하여 네트워크 학습을 돕습니다. HDR phase data의 경우 range compressor 를 사용하여 네트워크 입력의 값 범위를 압축함으로써 학습 안정성을 높입니다.
2.
학습 및 런타임 (Training and Runtime):
•
학습: 인코더와 디코더는 동시에 end-to-end로 학습됩니다. stratified sampling으로 구 전체를 고르게 커버하고, continuous sampling으로 네트워크가 고정된 뷰에 overfit되지 않고 비선형 보간을 잘 수행하도록 합니다. 손실 함수는 coverage, phase, albedo, phase slice에 대한 relative MSE 및 / norm의 조합으로 구성됩니다.
•
사전 렌더링: 학습 후 각 복셀의 latent vector를 생성하여 저장하고, 인코더는 폐기됩니다. 디코더의 학습된 가중치는 freeze되어 렌더러 내에서 추론용으로 export됩니다.
•
런타임: 빔 트레이서가 SVO를 순회하며 픽셀 footprint 내의 복셀들을 찾습니다. 해당 복셀의 latent vector와 현재 렌더의 방향 정보를 사용하여 디코더를 평가해 phase, albedo, coverage를 얻습니다. 이들을 조합하여 최종 이미지를 합성하며, 원본 기하학 및 재료는 사용되지 않습니다.
결과 및 이점:
Deep Appearance Prefiltering(DAP)는 기존 SGGX, EGGX, MMSS, HybridLoD 같은 최신 방법보다 더 높은 충실도로 복잡한 외형을 보존합니다. 특히 Disney BRDF 같은 복잡한 재료의 anisotropic specularity, glint, local occlusion을 정확하게 캡처하며, 이는 근사 모델로는 달성하기 어려운 부분입니다.
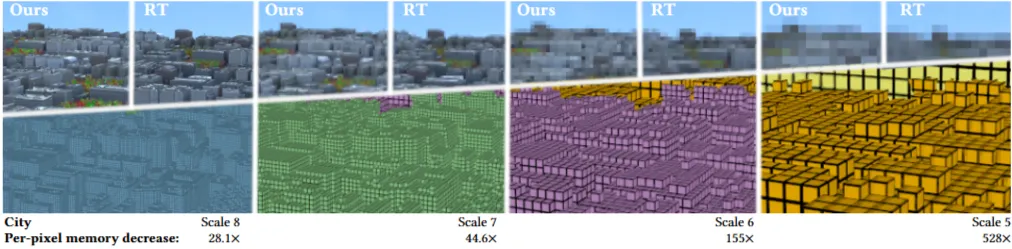
본 방법은 per-pixel memory footprint를 크게 줄입니다. City 장면에서 scale 0(가장 거친 해상도)의 경우 레이 트레이싱 대비 약 280,000배, scale 8(가장 미세한 해상도, 256×256 이미지)의 경우 약 28배의 메모리 절감 효과를 보였습니다. 렌더링 시간은 scale 5까지는 레이 트레이싱보다 빠르지만, 그 이상의 미세한 스케일에서는 네트워크 추론 비용 증가로 인해 레이 트레이싱이 더 빨라지는 변곡점이 있습니다.
또한 이 프레임워크는 temporal coherence를 유지하여 부드러운 애니메이션을 렌더링할 수 있습니다. 학습된 신경망은 원본 데이터의 노이즈를 제거하고 view/light direction을 보간하는 능력도 보여줍니다. diffuse albedo 같은 특정 매개변수를 latent vector를 통해 수정하여 장면의 외형을 손쉽게 변경할 수 있는 유연성도 제공합니다.
한계 및 향후 연구:
•
높은 사전 계산 비용: 각 장면마다 복셀 데이터를 사전 계산하고 네트워크를 학습해야 합니다.
•
복셀 경계 아티팩트: City 장면의 지붕 예시처럼 복셀이 가려진 기하학과 다른 기본 색상을 가진 가려지지 않은 기하학을 걸칠 때 albedo가 부정확하게 평균화되어 아티팩트가 발생할 수 있습니다. RGBA 마스크로 albedo를 공간적으로 표현하는 방안이 제시됩니다.
•
날카로운 하이라이트의 과도한 블러링: 매우 작은 solid angle에서만 발생하는 날카로운 delta highlight는 수백만 개의 복셀을 학습할 때 네트워크가 정확하게 캡처하기 어려워 약간 흐려질 수 있습니다.
•
단일 바운스 초점: 현재 구현은 주로 primary beams에 중점을 둡니다. global illumination 같은 multi-bounce 효과에 대한 효율적인 확장은 향후 연구 과제입니다.
•
importance sampling 부재: 빔 트레이서에서 multiple importance sampling(MIS) 같은 효율적인 샘플링 전략을 구현하려면 phase function의 importance sampling 메커니즘이 필요합니다.
결론적으로, 본 논문은 복잡한 3D 환경의 외형 사전 필터링을 위한 최초의 딥 러닝 프레임워크를 제안합니다. 기존 방법론의 한계를 뛰어넘어 복셀화된 장면에 대한 포괄적인 외형 표현을 제공하며, 렌더링 시 원본 기하학이나 재료 의존성 없이 상당한 메모리 절감과 외형 보존을 가능하게 합니다. 이는 복잡한 장면의 효율적인 렌더링 분야에 새로운 연구 방향을 제시합니다.
3.2 NeuMIP: Multi-Resolution Neural Materials (2022)
본 논문은 다양한 스케일에서 복잡한 재료의 외관을 표현하고 렌더링하기 위한 새로운 신경망 기반 기법인 NeuMIP(Multi-Resolution Neural Materials)를 제안합니다. 기존의 전처리(prefiltering) 기법인 밉매핑(mipmapping)은 확산 색상(diffuse color) 같은 단순한 재료 특성에는 효과적이지만, 노멀(normals), 자기 그림자(self-shadowing), 섬유(fibers) 또는 더 복잡한 미세 구조 및 반사(reflectances)에는 일반화되지 못합니다. NeuMIP는 이 문제를 해결하기 위해 전통적인 밉맵 피라미드를 '신경망 텍스처 피라미드(neural texture pyramid)'로 일반화하고, 이를 완전 연결 신경망(fully connected network)과 결합합니다. 또한 '신경망 오프셋(neural offsets)'이라는 새로운 기법을 도입하여 복잡한 시차 효과(parallax effects)를 가진 재료를 테셀레이션(tessellation) 없이 렌더링할 수 있게 합니다. 이 신경망 오프셋은 명시적인 높이 필드(heightfield)의 지도 없이(unsupervised) 훈련됩니다.
NeuMIP 시스템 내의 신경망 재료는 위치(position), 입사 방향(incoming direction), 출사 방향(outgoing direction), 그리고 필터 커널 크기(filter kernel size)를 포함하는 7차원 쿼리를 지원합니다. 재료 표현은 표준 밉매핑과 유사하게 적은 저장 공간을 요구하며(더 많은 텍스처 채널을 사용하지만), 일반적인 몬테카를로 경로 추적(Monte Carlo path tracing) 시스템에 쉽게 통합될 수 있습니다.
핵심 방법론:
본 논문은 다중 해상도 양방향 텍스처 함수(multi-resolution Bidirectional Texture Function, MBTF)를 정의하고 이를 신경망 아키텍처로 구현합니다.
3.1 다중 해상도 BTF 정의
전통적인 BTF는 고정된 스케일에서 재료를 모델링합니다. 반면 NeuMIP는 연속적인 가우시안 쿼리 커널 크기 σ를 지원하는 MBTF를 통해 임의의 세부 수준(level of detail)에서 재료의 외관을 표현합니다. MBTF는 다음과 같이 정의됩니다:
여기서 G(u, σ; x)는 평균 u와 표준 편차 σ를 가진 정규화된 2D 가우시안 함수이며, B(u, ωᵢ, ωₒ)는 가장 미세한 재료 수준에서의 전통적인 BTF입니다. 이는 특정 위치 u, 커널 반경 σ, 입사 방향 ωᵢ, 출사 방향 ωₒ에 대해 재료 표면에서 반사된 복사휘도(radiance)를 미리 계산합니다.
3.2 신경망 MBTF 기본 모델 (Neural MBTF baseline)
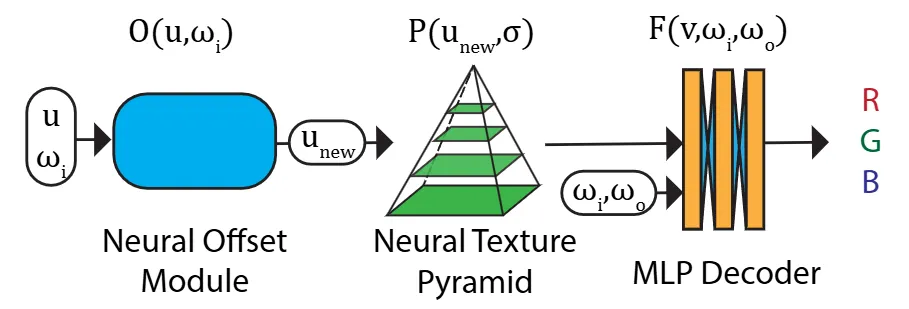
7차원 MBTF를 직접 저장하는 것은 비현실적입니다. 따라서 저자들은 이를 효율적으로 모델링하는 신경망 아키텍처를 제안합니다. 기본 아키텍처는 두 가지 핵심 요소로 구성됩니다: 복잡한 다중 스케일 공간 가변 재료 외관을 인코딩하는 '신경망 텍스처 피라미드 P'와 피라미드에서 방향성 반사율을 계산하는 '재료 디코더 네트워크 F'입니다.
신경망 텍스처 피라미드 (Neural texture pyramid): P = {Tₛ}는 일련의 신경망 텍스처 Tₛ로 구성됩니다. 각 Tₛ는 2ˢ × 2ˢ × c 크기를 가지며, 각 텍셀(texel)은 c 채널 잠재 신경망 특징(latent neural feature)을 포함합니다. s는 이산적인 세부 수준을 나타내며, 0 ≤ s ≤ k입니다. 이 피라미드 구조는 여러 스케일에서 복잡한 재료 외관을 인코딩합니다. 고전적인 밉매핑과 유사하게, 연속적인 수준 σ와 위치 u에서 신경망 특징 P(u, σ)를 얻기 위해 trilinear interpolation을 수행합니다. 공간 차원에서는 bilinear interpolation을, 스케일 차원(로그 스케일)에서는 linear interpolation을 사용합니다.
여기서입니다.
재료 디코더 (Material decoder): 디코더 F는 신경망 피라미드에서 쿼리된 신경망 특징과 입사 및 출사 방향을 입력으로 받아 최종 RGB 반사율 값을 계산하는 다층 퍼셉트론(MLP) 네트워크입니다. 이 네트워크는 4개의 레이어로 구성되며, 각 중간 레이어는 25개의 출력 채널을 가집니다. ReLU 활성화 함수를 사용하며, 마지막 레이어에서도 ReLU를 사용하여 출력이 음수가 되지 않도록 합니다.
3.3 신경망 오프셋을 포함한 신경망 MBTF (Neural MBTF with Neural Offset)
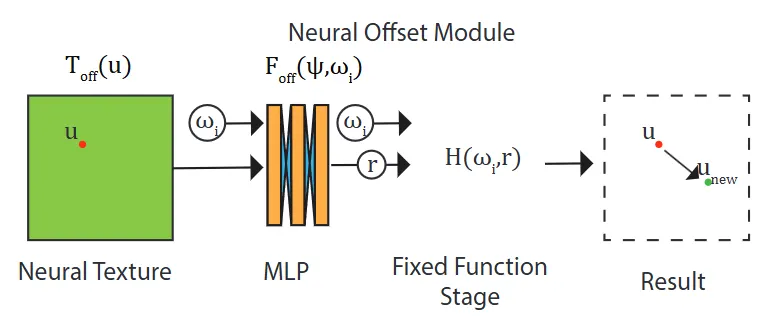
기본 모델은 많은 재료를 모델링할 수 있지만, 시차 및 폐색(occlusion) 효과가 두드러진 비평면 재료(non-flat materials)를 처리하는 데는 한계가 있습니다. 이를 해결하기 위해 텍스처 쿼리 위치의 좌표 오프셋을 예측하는 '신경망 오프셋 모듈 O'를 도입합니다.
신경망 오프셋(Neural offset): 2D 오프셋을 직접 회귀하는 대신, 레이 깊이(ray depth) r을 나타내는 1D 스칼라 값을 회귀하도록 네트워크를 훈련합니다. 이 r 값은 시야 방향 ωₒ가 주어지면 최종 2D 오프셋으로 변환됩니다. 신경망 오프셋 모듈은 '신경망 오프셋 텍스처 T_off', T_off에서 레이 깊이 r을 회귀하는 'MLP F_off', 그리고 오프셋을 출력하는 '고정 함수(fixed function) H'로 구성됩니다.
여기서 ψ = T_off(u)는 초기 위치 u에서 T_off에 대한 잠재 특징 벡터 룩업입니다. F_off는 4개의 레이어로 구성되며 ReLU 활성화 함수를 사용합니다. 추정된 레이 깊이 r이 주어지면 오프셋은 다음과 같이 계산됩니다:
여기서 ωₓ, ωᵧ, ωᵤ는 ωₒ의 구성 요소입니다. 최종 쿼리 위치는 다음과 같습니다:
이 새로운 룩업 위치 u_new는 신경망 텍스처 피라미드에서 잠재 벡터를 룩업하는 데 사용됩니다.
전체 신경망 MBTF 표현은 신경망 오프셋 모듈을 기본 신경망 MBTF 네트워크 앞에 연결하여 모델링됩니다:
이 프레임워크는 완전히 미분 가능(differentiable)하여 신경망 오프셋, 다중 스케일 피라미드 및 디코더를 동시에 최적화하는 엔드-투-엔드 훈련(end-to-end training)이 가능합니다. 신경망 오프셋 모듈은 ground truth 오프셋 없이 비지도 학습 방식으로 훈련됩니다.
데이터 생성 및 훈련:
합성 MBTF 데이터는 마이크로 지오메트리(microgeometry)를 구성하고 CPU 기반 표준 경로 추적기를 사용하여 필요한 쿼리를 렌더링함으로써 생성됩니다. 훈련은 빛 방향, 카메라 방향, UV 위치 및 커널 반경으로 구성된 7D 쿼리를 입력으로 받아 네트워크가 RGB 색상을 생성하고 역전파(back-propagation)를 통해 네트워크 가중치와 신경망 텍스처를 업데이트합니다. 훈련 중에는 신경망 텍스처에 가우시안 블러(Gaussian blur)를 적용하고, 훈련이 진행됨에 따라 표준 편차를 지수적으로 감소시켜 노이즈를 방지합니다.
렌더링:
NeuMIP 재료는 Mitsuba 렌더링 엔진에 통합되어 일반 오브젝트와 신경망 재료 오브젝트 간에 빛이 원활하게 상호작용할 수 있습니다. 신경망 재료가 히트되면 신경망 모듈을 평가하고, 간접 조명(indirect illumination)을 위해 출사 방향을 샘플링합니다.
NeuMIP는 다양한 복잡한 재료를 여러 스케일에서 정확하게 표현할 수 있는 신경망 아키텍처를 제공합니다. 신경망 오프셋 기법을 통해 테셀레이션 없이 시차 효과를 포함한 복잡한 기하학적 외관을 렌더링하며, 인코더-리스 아키텍처(encoder-less architecture) 덕분에 텍셀당 200~400개의 무작위 쿼리만으로 훈련이 가능합니다. 이는 변위(displacement), 시차, 자기 그림자 및 기타 효과를 정확하게 표현하는 고품질 외관을 제공합니다.
NeuMIP의 장점
•
다양한 재료 표현: normals, self-shadowing, fibers, parallax 등 복잡한 기하학적 특징과 빛 반사 효과를 multi-resolution으로 정확하게 표현할 수 있습니다.
•
3D 모델링 불필요: neural offset 덕분에 복잡한 3D tessellation(세분화)이나 heightfield 없이도 parallax effect 같은 깊이감을 표현할 수 있어 저장 공간과 렌더링 비용을 크게 줄입니다.
•
효율적인 학습: encoder-less architecture 덕분에 새로운 재료를 학습시킬 때 texel당 200~400개의 query(질의)만으로 훈련이 가능하며, 이는 기존 방식보다 훨씬 효율적입니다.
•
작은 모델 크기: Rainer et al. [2020] 같은 이전 연구에 비해 network weights(신경망 가중치)가 10배 이상 적고, texture channels(텍스처 채널)도 절반 이하로 적어 더 가볍고 빠릅니다.
•
기존 렌더링 시스템과 호환: Monte Carlo path tracing과 같은 표준 렌더링 엔진에 쉽게 통합될 수 있습니다.
제한 사항 및 미래 연구 방향
•
Importance Sampling 개선: 빛을 효율적으로 샘플링하는 importance sampling 방식이 아직 단순하여 더 specular(반사성이 강한) 재료에는 개선이 필요합니다. texel별로 parametric pdf model을 학습시키는 것을 고려하고 있습니다.
•
Glinty 재료: 반짝이는(glinty) 재료는 blurring(흐림) 없이 처리하기 어려울 수 있습니다. decoder에 random vector(무작위 벡터)를 추가하여 stochastic detail(확률적 디테일)을 생성하고 GAN loss로 훈련하는 방법을 연구할 수 있습니다.
•
반투명 재료 지원: reflectance 외에 alpha transparency를 예측하여 반투명 재료를 지원할 수도 있습니다.
3.3 Neural Layered BRDFs

본 논문은 레이어드 BRDF(Bidirectional Reflectance Distribution Functions)를 사실적으로 렌더링하는 데 있어 기존 Monte Carlo 시뮬레이션의 높은 계산 비용과 노이즈 문제를 해결하기 위한 뉴럴 프레임워크를 제안합니다. 이 프레임워크는 BRDF를 잠재 공간(latent space)의 압축된 코드로 표현하고, 이 잠재 벡터들 간의 레이어링 연산을 학습합니다.
핵심 방법론은 두 가지 주요 뉴럴 네트워크로 구성됩니다:
Neural BRDF Representation (신경망 BRDF 표현):
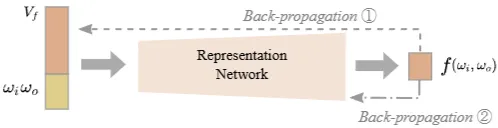
•
임의의 BRDF 를 컴팩트한 잠재 벡터 로 압축하는 것이 목표입니다. 와 는 각각 입사 방향과 출사 방향을 나타냅니다.
•
이를 위해 디코더 역할을 하는 범용 평가 네트워크를 설계합니다. 이 네트워크는 잠재 벡터 와 방향 쌍 을 입력받아 해당 BRDF 값을 출력합니다(그림 2 참조).
•
네트워크 훈련은 학습 데이터셋의 모든 BRDF 값을 사용하며, 두 가지 역전파 경로를 통해 이루어집니다. 첫째, 현재 입력 BRDF의 잠재 벡터를 업데이트합니다. 둘째, 평가 네트워크의 가중치를 업데이트합니다. 이를 통해 네트워크는 다양한 BRDF를 서로 다른 잠재 벡터로 표현하는 방법을 학습합니다.
•
새로운 BRDF를 잠재 공간으로 투영할 때는 학습된 평가 네트워크의 파라미터를 고정하고 잠재 벡터만 최적화합니다. 이 과정은 약 10~45초가 소요됩니다.
•
이 모델은 주로 등방성 BRDF를 가정하며, 스펙큘러한 BRDF를 포함한 다양한 BRDF를 정확하게 표현할 수 있습니다.
Neural BRDF Layering (신경망 BRDF 레이어링):
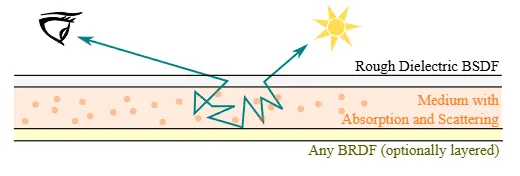
•
기존 Monte Carlo 기반 레이어링 방식은 정확하지만 비용이 많이 들고 분산(variance)이 높습니다. 본 논문은 이러한 복잡한 광원 상호작용을 잠재 공간에서 학습하는 방법을 제안합니다.
•
레이어링 연산은 두 개의 층(top layer, bottom layer)과 그 사이 균일한 매질(homogeneous participating media)을 고려합니다(그림 5 참조). 최상층은 거친 유전체(rough dielectric) BSDF로, 최하층은 임의의 BRDF로 구성됩니다. 매질은 산란 알베도(scattering albedo) 와 소멸 계수(extinction coefficient) 를 가집니다.
•
레이어링 네트워크는 MLP(Multi-Layer Perceptron) 기반 구조를 가지며(그림 3 참조), 최상층 BRDF의 잠재 벡터 , 최하층 BRDF의 잠재 벡터 , 그리고 매질 파라미터 와 를 입력받아 최종 레이어드 BRDF를 나타내는 잠재 벡터 를 출력합니다.
•
이 레이어링 네트워크는 재귀적으로 적용되어 다층(multi-layer) BRDF도 처리할 수 있습니다.
데이터셋 및 훈련:
•
Mitsuba 렌더러를 사용하여 거친 도체(rough conductor), 거친 유전체(rough dielectric) BRDF 및 다양한 파라미터를 갖는 2층, 3층 레이어드 BRDF 데이터셋을 생성합니다.
•
표현 네트워크는 2층 BRDF 데이터로 손실 함수를 사용하여 훈련됩니다. 잠재 벡터와 네트워크 가중치를 동시에 업데이트합니다.
•
레이어링 네트워크는 훈련된 표현 네트워크에서 얻은 잠재 벡터를 입력 및 출력으로 활용하며 손실 함수로 훈련됩니다. 특히 3층 BRDF 데이터로 미세 조정(finetune)됩니다.
렌더링 파이프라인:
•
BRDF를 잠재 벡터로 표현하고, 레이어드 BRDF의 경우 레이어링 연산을 통해 레이어드 잠재 벡터를 얻습니다. SVBRDF(Spatially Varying BRDF)의 경우 각 텍셀에 잠재 벡터를 저장하는 잠재 텍스처(latent texture)를 사용합니다.
•
패스 트레이싱(path tracing) 렌더링에서 교차점의 BRDF 값은 저장된 잠재 벡터와 쿼리 방향을 표현 네트워크에 입력하여 추론합니다.
•
GPU 추론 가속화를 위해 NVIDIA Cutlass CUDA Templates를 활용하여 CUDA로 구현했습니다. BRDF의 중요도 샘플링(importance sampling)을 위해 PDF 프록시를 예측하는 작은 네트워크도 추가로 훈련합니다.
결과:
본 방법은 기존 Guo et al. [2018]의 Monte Carlo 기반 방식과 비교하여 유사한 품질의 결과를 훨씬 적은 비용과 노이즈 없이 생성합니다(그림 1, 6, 7, 10, 11). 특히 GPU를 활용한 네트워크 추론 덕분에 렌더링 시간이 크게 단축됩니다. 측정된 BRDF(MERL 데이터셋)에도 효과적으로 적용됩니다(그림 9). 다층 BRDF에 재귀적으로 적용될 때도 참조 결과에 근접합니다(그림 8).
한계:
현재 모델은 등방성 재질과 매질에 초점을 맞추고 있습니다. 비등방성(anisotropic) 재질, 노멀 매핑된 BRDF, 그리고 BTDF(Bidirectional Transmittance Distribution Functions)에 대한 명시적인 처리는 향후 연구 과제입니다. 또한 재귀적 레이어링 시 오류가 누적될 수 있으며, 신경망의 특성상 에너지 보존 법칙을 완벽하게 만족하지 못할 수 있습니다.
결론적으로, 이 논문은 BRDF를 압축된 잠재 벡터로 표현하고 잠재 공간에서 레이어링 연산을 수행하는 신경망 기반 프레임워크를 제시합니다. 이는 노이즈가 없고 계산 효율적인 레이어드 재질 평가를 가능하게 하는 "Neural BRDF algebra"의 첫걸음으로 평가됩니다.
3.4 Unified Neural Encoding of BTFs (Bidirectional Texture Functions)
본 논문은 실세계 재료의 사실적인 렌더링을 위한 BTF(Bidirectional Texture Function) 표현에 대해 새로운 통합 신경망 인코딩(Unified Neural Encoding) 방식을 제안합니다. 기존 BTF 데이터는 방대한 메모리 요구사항과 불연속적인 측정값으로 인해 렌더링 시 보간 문제와 높은 계산 비용이 발생했습니다. 신경망 기반 접근 방식이 이를 해결하기 위해 등장했으나, 기존 방식들은 각 재료마다 별도의 네트워크를 학습해야 했습니다. 따라서 재료 간 공유된 잠재 공간(latent space)이 없었고, 새로운 재료에 대한 효율적인 인코딩이 어려웠습니다.

저자들은 이러한 한계를 극복하기 위해 오토인코더(autoencoder)에서 영감을 받은 통합 네트워크 아키텍처를 제안합니다. 이 아키텍처는 다양한 재료를 학습하여 반사율 측정값을 공유된 잠재 파라미터 공간으로 투영합니다. 이는 SVBRDF(Spatially-Varying BRDF) 피팅과 유사하게 실세계 재료를 파라미터 맵으로 표현합니다. 디코더 네트워크는 분석적 BRDF 표현처럼 작동합니다.
핵심 방법론:
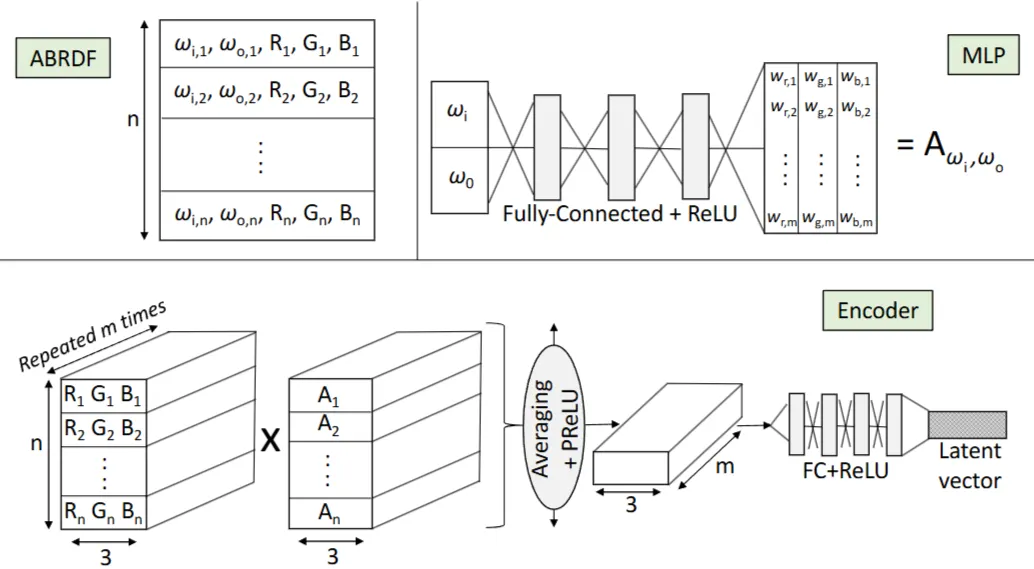
이 논문의 핵심은 입력 ABRDF(Apparent BRDF)의 가변적인 각도 샘플 수와 불규칙한 샘플 위치에 관계없이 작동하는 인코더 아키텍처입니다. ABRDF는 개의 차원 엔트리(, , R, G, B)로 구성됩니다. 여기서 , 는 입사 및 출사 방향의 스테레오그래픽(stereographic) 2D 좌표이며, R, G, B는 반사율 측정값입니다.
1.
인코더 네트워크(Encoder Network): 유연성을 위해 인코더는 두 부분으로 구성됩니다.
•
각도 MLP (Angular Multi-Layer Perceptron): 단일 광원-시점 조합의 각도(, )를 입력받아 차원 가중치 벡터를 출력합니다. 입력 ABRDF의 개 샘플 각각에 대해 이 MLP가 실행되어 크기의 가중치 행렬 를 생성합니다.
•
반사율 확장 및 곱셈: 입력 ABRDF의 RGB 반사율 값을 번 확장합니다. 확장된 RGB 값은 가중치 행렬 와 원소별로 곱해집니다. 이는 반사율 신호와 학습된 각도 필터의 곱을 각도 공간에서 이산적으로 적분하는 것과 유사합니다.
•
평균화 연산 (Averaging Operation): 가장 중요한 단계입니다. 가중치 행렬 와 곱해진 결과에 대해 수직 방향(개 샘플 전체)으로 평균화 연산을 수행합니다. 이를 통해 출력은 입력 샘플의 개수나 순서에 관계없이 항상 고정된 크기의 특징 행렬(feature matrix)이 됩니다. 이는 기존 방식의 1차원 컨볼루션이나 맥스 풀링과 달리 각도 샘플링에 대한 불변성을 제공합니다.
•
완전 연결 계층 (Fully-Connected Layers): 특징 벡터를 펼친 후 PReLU 활성화 함수를 거쳐, 하나의 은닉 계층과 ReLU 활성화 함수를 포함하는 완전 연결 계층을 통해 저차원 잠재 벡터(latent vector)로 투영합니다.
2.
디코더 네트워크(Decoder Network):
•
디코더는 ABRDF의 잠재 좌표와 스테레오그래픽 좌표로 표현된 광원 및 시점 방향을 입력받습니다.
•
4개의 은닉 계층과 ReLU 활성화 함수로 구성된 표준 완전 연결 네트워크로, 주어진 방향에 대한 RGB 반사율 값을 재구성합니다.
학습 및 결과:
네트워크는 Bonn BTF 데이터베이스의 77개 재료(7개 클래스)에 대해 end-to-end 방식으로 학습됩니다. 학습 시 RGB 채널을 순열(permute)하고 20%에서 100% 사이의 무작위 각도 샘플 부분 집합을 입력하여 데이터 증강(data augmentation)을 수행하고 각도 해상도 변화에 대한 견고성을 확보했습니다. 재료의 높은 동적 범위(HDR)를 처리하기 위해 로그 변환과 정규화를 적용했으며, L1 손실 함수를 사용하여 평균 색조 정확도와 대비 보존을 향상시켰습니다.
제안된 네트워크는 학습되지 않은 재료에 대해서도 재료별로 과적합된 네트워크에 필적하는 재구성 성능을 보였습니다. 특히 공간 세부 사항, 서브서피스 산란(subsurface scattering), 상호 그림자(intershadowing)와 같은 비지역적(non-local) 효과를 잘 재현했습니다. 32차원의 잠재 공간이 정확성과 압축률 간의 최적 절충점으로 선택되었습니다.
이 통합 아키텍처는 각도 샘플 해상도에 대한 견고성을 입증했습니다. 원래 샘플의 10% 미만으로도 안정적인 재구성이 가능했습니다. 잠재 공간에서의 필터링은 거의 눈에 띄지 않는 품질 손실로 가능했으며, 이는 밉매핑(mipmapping)과 같은 응용에 유용합니다. 또한 안정적인 잠재 공간은 잠재 맵을 직접 사용하여 효율적인 BTF 텍스처 합성(texture synthesis)을 가능하게 합니다.
이 연구는 다양한 실세계 재료의 BTF를 효율적으로 인코딩하고 공유된 잠재 공간에서 재료를 표현하는 신경망 아키텍처를 제시합니다. 이는 BTF 렌더링 및 편집 분야에 중요한 진전을 가져왔습니다. 향후 연구로는 더 많은 학습 데이터 확보 및 합성 데이터 활용 방안이 모색될 수 있습니다.
3.5 A Compact Representation of Measured BRDFs Using Neural Processes
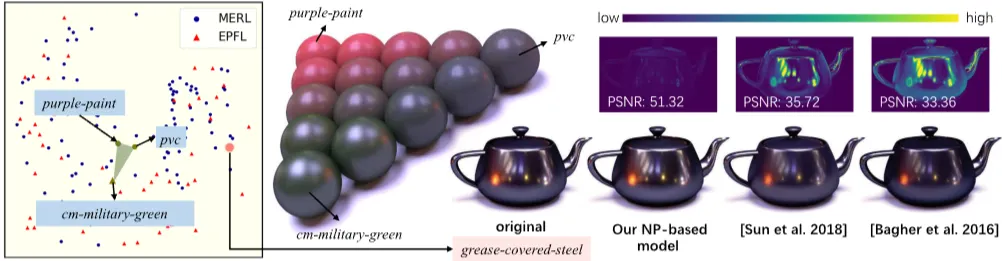
본 논문은 Neural Processes(NPs)를 활용하여 측정된 BRDF(Bidirectional Reflectance Distribution Functions)를 새롭고 압축적으로 표현하는 방식을 제안합니다. 기존 방법론들은 BRDF를 이산적인 고차원 행렬이나 텐서로 표현했습니다. 이와 달리 본 접근 방식은 BRDF를 연속 함수로 간주하고 해당 함수 공간에서 작동합니다. 구체적으로, MERL 및 EPFL 데이터셋과 같은 측정된 BRDF 세트를 활용하여 저차원 잠재 공간(latent space)과 신경망을 학습시킵니다. 이를 통해 BRDF를 비선형 방식으로 인코딩하고 디코딩합니다. NPs 프레임워크의 유연성과 학습된 잠재 공간 덕분에 인코딩된 BRDF는 매우 압축적이며 기존 방법론보다 높은 정확도를 제공합니다. 저자들은 BRDF 압축 및 편집이라는 두 가지 응용 분야를 통해 이 접근 방식의 실용성을 입증합니다. 또한 개별 BRDF에 대한 더 나은 압축률을 달성하고 중요 샘플링(importance sampling)을 가능하게 하는 두 가지 후처리 학습 디코더(post-trained decoders)를 설계했습니다.
핵심 방법론 (Core Methodology)
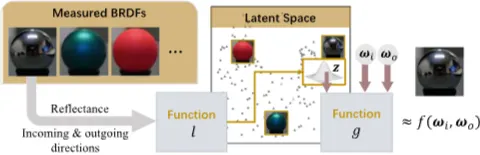
본 연구의 핵심은 BRDF 를 가능한 모든 BRDF 집합 에서 무작위로 추출된 샘플로 간주하는 것입니다. 이 확률 분포를 얻기 위해 측정된 BRDF 컬렉션 을 의 관측값으로 활용하는 데이터 기반 접근 방식을 사용합니다. BRDF 는 고차원 잠재 벡터 와 신경망 함수 를 사용하여 다음 식으로 근사됩니다.
(1)
여기서 는 입사 방향, 는 반사 방향을 나타냅니다. 측정된 BRDF 컬렉션 는 동일한 함수 와 잠재 벡터 세트 로 모델링되며, 를 만족합니다. 각 잠재 벡터 는 평균 , 공분산 를 갖는 정규 분포 를 따른다고 가정합니다. 따라서 를 모델링하는 문제는 두 가지로 요약됩니다:
(i) 식 (1)에서 함수 를 결정하기,
(ii) 모든 에 대해 분포 매개변수 와 를 찾기.
데이터 표현 및 우도 모델링
측정된 BRDF 는 관측값 시퀀스 와 로 표현됩니다. 여기서 는 번째 관측의 조명 및 시야 방향을 인코딩하고, 는 해당 BRDF 값을 나타냅니다.
모든 에 대한 의 관측값을 및 라고 하면, 목표 우도(target likelihood) 는 다음과 같이 표현됩니다:
(2)
여기서 는 재구성 오차와 측정 노이즈를 모델링합니다.
모든 가능한 BRDF의 사전 분포(prior) 는 얻기 어렵습니다. 따라서 조건부 사후 분포(conditional posterior) 로 근사합니다.
함수 은 관측값 가 주어졌을 때 의 분포 매개변수 와 를 예측합니다: .
네트워크 구조 및 훈련
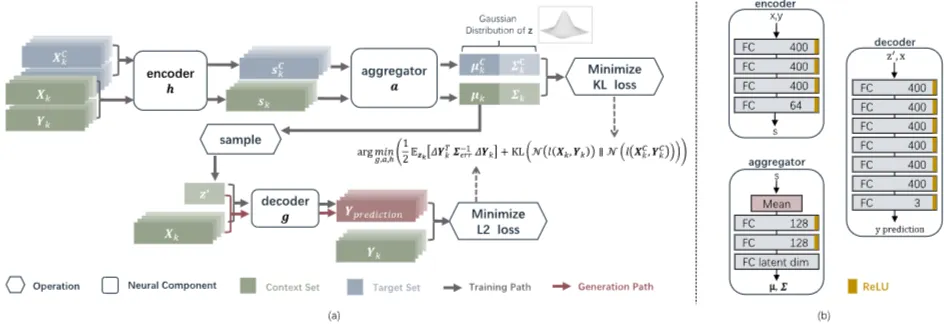
함수 와 은 심층 신경망으로 표현됩니다. 은 두 부분으로 분해됩니다: 개별 관측값을 인코딩하는 비선형 함수 와 인코딩된 관측값 세트를 통합하는 함수 입니다.
. 여기서 를 인코더, 를 어그리게이터, 를 디코더라고 부릅니다. 어그리게이터 는 입력 관측값의 순서 불변성을 보장하기 위해 평균 함수를 사용합니다. 모든 네트워크는 완전 연결(fully connected, FC) 레이어로 구성되며, 디코더의 마지막 레이어에는 ReLU(rectified linear units)를 적용하여 BRDF 반사율의 음수 값을 방지합니다.
훈련 과정은 식 (2)의 변분 사후 분포(variational posterior)를 최대화하는 것을 목표로 합니다. 그러나 직접 최적화가 어렵기 때문에 ELBO(Evidence Lower Bound)를 활용합니다. BRDF에 대한 사전 지식이 부족하므로, 사전 분포 대신 NPs의 아이디어를 따릅니다. 컨텍스트 세트 를 샘플링하고, 컨텍스트 세트의 사후 분포 가 전체 세트의 사전 분포 를 근사하도록 합니다. 이를 위해 다음 손실 함수를 최소화하여 와 을 학습합니다.
(12)
여기서 이며, 은 Kullback-Leibler 발산입니다. 훈련은 MERL 및 EPFL 데이터셋의 BRDF를 사용하여 Adam 옵티마이저로 수행됩니다.
학습된 잠재 공간 분석
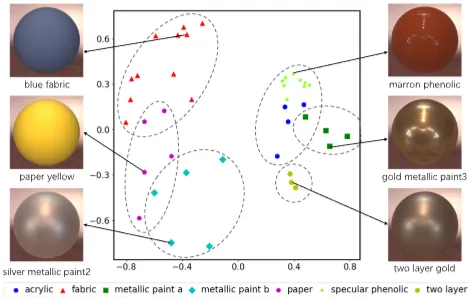
훈련된 인코더 네트워크는 모든 BRDF(관측 쌍 로 표현)를 이 잠재 공간으로 투영할 수 있습니다. 잠재 공간은 2차원부터 7차원까지 평가되었으며, 7D 공간이 여러 응용 분야에서 우수한 성능을 보였습니다. 이 공간은 의미적으로 유의미한 구조를 가집니다. 유사한 외관의 재료들은 잠재 공간에서 클러스터를 형성하고, 확산 반사도(diffuse reflectivity)와 거칠기(roughness)는 각각 특정 주성분(principal component) 축을 따라 단조롭게 변화합니다.
응용 1: 압축
NP 기반 기술은 측정된 BRDF를 최대 7차원의 잠재 벡터로 인코딩하여 데이터셋을 압축합니다. 디코더 네트워크 의 크기는 약 3.11MB이며, 잠재 공간의 차원()이 총 저장 공간에 미치는 영향은 미미합니다. 소수의 BRDF를 압축할 때는 디코더 오버헤드가 커질 수 있어, 각 BRDF에 특화된 경량 "하이퍼네트워크(hypernetworks)"를 후처리 학습하여 디코딩합니다. 하이퍼네트워크는 잠재 벡터 를 입력받아 메인 네트워크(mainNet)의 가중치 를 생성하고, 메인 네트워크는 방향 를 입력받아 BRDF 값을 예측합니다: , 여기서 입니다. 압축 시 만 저장하면 되며, 이는 BRDF당 9KB로 매우 높은 압축률을 제공합니다. PSNR 비교 결과, 본 방법은 기존 최신 압축 방법보다 대부분의 BRDF에서 더 높은 품질을 제공합니다.
응용 2: BRDF 편집
학습된 잠재 공간은 효율적인 BRDF 편집 및 보간을 가능하게 합니다.
1.
BRDF 중요 샘플링: 몬테 카를로 렌더링의 빠른 수렴을 위해 중요 샘플링이 필수적입니다. 본 연구는 NICE(Non-linear Independent Components Estimation)를 활용하여 대상 분포와 분해된 분포(factorized distribution) 사이의 비선형 결정론적 변환을 학습합니다. 코사인 가중 BRDF를 정규화하여 목표 PDF를 얻고, NICE는 외향 방향 와 BRDF 잠재 벡터 가 주어지면 입사 방향 를 효율적으로 중요 샘플링합니다. 중간 벡터(halfway vector) 방향을 샘플링하며, 네트워크는 약 37KB의 저장 공간과 8ms의 샘플 생성 시간을 가집니다. 중요 샘플링 결과는 코사인 가중 샘플링이나 GGX 기반 샘플링보다 노이즈가 적고 우수한 렌더링 품질을 제공합니다.
2.
BRDF 보간 및 편집: 두 BRDF의 잠재 벡터를 선형 혼합하여 보간할 수 있습니다. 이는 반사 하이라이트의 모양과 확산 반사 강도를 부드럽게 변화시킵니다. 또한 잠재 공간의 의미론적 구조를 활용하여 "특성 벡터(trait vectors)"를 따라 BRDF를 편집할 수 있습니다. SVM(Support Vector Machine)으로 13가지 지각적 특성(예: 고무, 금속성, 직물 등)에 대한 하이퍼플레인을 구하고, 이 평면의 법선 방향(특성 벡터)을 따라 이동하여 재료 외관의 변화를 관찰합니다.
결론
본 연구는 NPs를 활용하여 측정된 BRDF를 위한 새롭고 압축적인 표현을 제시합니다. BRDF를 이산적 행렬이 아닌 연속 함수로 처리함으로써, 신경망으로 복잡한 비선형 관계를 학습하여 전례 없는 압축성과 정확도를 달성했습니다. 본 방법은 자세한 통계와 최신 방법과의 비교를 통해 효율성을 입증했으며, BRDF 압축 및 편집이라는 두 가지 응용을 통해 실용성을 보여주었습니다. 후처리 학습된 하이퍼네트워크를 사용하면 소수의 BRDF도 효율적으로 압축할 수 있으며, 중요 샘플링 신경망과 통합된 대화형 편집 도구는 BRDF 탐색과 조작을 용이하게 합니다.
4. 논문 비교
Paper (Year) | RT-NAM (2024) | Deep Appearance Prefiltering (2019) | NeuMIP (2022) | Neural Layered BRDFs | Unified Neural Encoding of BTFs | NPs for Measured BRDFs |
Target Representation | BRDF + unified latent textures | MBTF (volumetric/SVO) | MBTF (7D query) | Layered BRDF (latents) | BTF (image‑based, measured) | BRDF (measured) |
LOD/Filtering | MIP-hierarchy | multi-scale SVO | neural pyramid | | (latent filterable) | |
Importance Sampling | microfacet-prior PDF | | (기본) | (PDF proxy) | | (learned sampler) |
Anisotropy(이방성) | | | | (isotropic focus) | | |
Layered/Graph Bake | bake material graphs | | | (latent-space layering) | | |
Normals/Parallax/Disp. | Normals / Parallax / Displacement. | Normals / Parallax / Displacement. (volumetric) | Normals / Parallax (neural offset) / Displacement. | Normals / Parallax / Displacement. | Normals(implicit) / Parallax / Displacement. | Normals / Parallax / Displacement. |
Transmission(투과) | | | | | | |
Encoder/Decoder Style | Encoder→Latent Tex → 2 Decoders | Shared E/D for all voxels | Encoder-less (latent pyramids + MLP) | Shared decoder + layering net | Autoencoder (shared latent) | Neural Process (g,l) + hypernet |
Latent Storage | c channels / texel | latent per voxel | Latent per texel in MIP pyramid | latent per material/texel | latent per material | 7D latent per BRDF |
Training Time (per material) | ~4–5 h | scene-level hours~days | Relatively fast | minutes per BRDF fit | dataset-wise | dataset-wise |
Runtime Speed vs Ref | Shading ×2.3–9.1, Frame ×1.6–4.1 | scale≤5 faster; fine scales slower | renderer-dependent | faster than MC layering | n/a | n/a |
Physical Guarantees (Energy/Reciprocity) | Energy / Reciprocity | Energy | Energy | Energy | Energy | Energy |
Limitations | coarser MIP softening, Fresnel grazing error, training stability | voxel boundary artifacts, sharp glints blur, precompute heavy | specular MIS 부족, glinty blur, transparency N/A | recursion error acc., isotropy focus, BTDF 미포함 | per-material overfit 방지, sampling 미지원 | requires dataset, editing via latents only |
Primary Use Case | Real-time film-quality | Offline prefiltering/LoD | Multi-scale neural materials | Layered BRDF eval | Measured BTF reconstruction | Compression + IS + edit |
5. Practical Application Scenarios from Research & Development Perspective
"너무 크고, 너무 느리고, 너무 복잡한" 현실의 재질(Material) 데이터를
"작고, 빠르고, 효율적인" 딥러닝 모델로 압축(표현)해서 실시간 렌더링에 쓰자!
1. RT-NAM (Real-Time Neural Appearance Models, 2024)
이 기술은 '복잡한 오프라인 재질을 실시간으로 가져오는 최종 단계'에 해당합니다. 현존하는 게임 엔진이나 실시간 렌더링 환경에 가장 직접적으로 통합될 수 있는 실용적인 기술입니다.
•
활용 방법
1.
Substance Designer, Blender 등에서 영화나 VFX 수준의 복잡한 다층(Multi-layer) 머티리얼을 제작합니다. (예: 여러 장의 텍스처와 복잡한 노드로 구성)
2.
이 머티리얼을 RT-NAM의 학습 파이프라인에 입력하여 '베이킹(Baking)'합니다.
3.
결과물로 나온 고도로 압축된 '통합 잠재 텍스처(Unified Latent Texture)'와 신경망 셰이더를 얻습니다.
4.
이 결과물을 언리얼, 유니티 같은 게임 엔진에 그대로 가져와 고품질 재질을 매우 가볍게 렌더링합니다.
•
구체적인 예시
◦
AAA급 게임 캐릭터: 기사의 갑옷에 표현된 녹, 흠집, 먼지, 코팅 효과 등을 수많은 텍스처 대신 단 한 장의 잠재 텍스처로 구현하여 메모리와 성능을 획기적으로 절약합니다.
◦
자동차 실시간 시각화: 보는 각도에 따라 색이 미묘하게 변하는 다층 자동차 페인트를 웹이나 앱에서 사용자가 실시간으로 돌려보며 확인할 수 있는 인터랙티브 콘텐츠를 제작합니다.
◦
건축 시각화: 오래된 가죽 소파의 닳은 느낌이나 금속의 부식(Patina) 효과처럼 사실적인 재질을 VR/AR 환경에서 끊김 없이 탐색합니다.
•
미래 가능성영화 품질의 에셋을 게임에서 사용하는 '시네마틱 리얼리즘'을 대중화할 핵심 기술입니다. 복잡한 머티리얼을 가볍게 압축하는 산업 표준 포맷으로 발전하여, 다양한 툴과 엔진 간의 재질 호환성을 높일 가능성이 큽니다.
2. Deep Appearance Prefiltering (2019)
이 기술은 개별 재질보다는 '거대한 3D 환경 전체의 외형을 통째로 구워내는' 야심 찬 접근법입니다.
•
활용 방법
1.
도시, 숲 등 매우 복잡하고 거대한 3D 씬(Scene) 전체를 입력합니다.
2.
오프라인에서 며칠에 걸쳐 이 씬의 모든 지오메트리와 재질 정보를 다중 스케일 복셀(SVO) 데이터로 사전 계산(Prefiltering)합니다.
3.
런타임 시에는 원본 3D 데이터 없이, 이 가벼운 복셀 데이터만을 특수한 렌더러(빔 트레이서)로 읽어와 화면을 그립니다.
•
구체적인 예시
◦
AR/VR 도시 체험: 스마트폰 카메라로 도시를 비추면, 실제 건물 위에 고품질의 가상 건물이 자연스럽게 겹쳐 보이는 AR 앱을 구현합니다. 무거운 3D 모델을 실시간으로 계산할 필요가 없습니다.
◦
디지털 트윈 및 문화유산 아카이빙: 거대한 공장 설비나 소실 위험이 있는 문화유산 전체를 극도로 상세하게 스캔하여, 사용자가 웹이나 VR에서 자유롭게 탐험할 수 있는 디지털 아카이브를 구축합니다.
•
미래 가능성클라우드 기반 렌더링이나 스트리밍 서비스에 매우 적합합니다. 서버에서 미리 모든 계산을 끝내고, 사용자는 가벼운 데이터만 스트리밍 받아 고품질 그래픽을 체험하는 미래형 플랫폼의 기반 기술이 될 수 있습니다.
3. NeuMIP (Multi-Resolution Neural Materials, 2022)
이 기술은 '실제 지오메트리 없이도 미세한 입체감과 깊이감을 표현하는 전문가'입니다. 특히 표면의 시차(Parallax) 효과에 특화되어 있습니다.
•
활용 방법
1.
카펫의 털, 이끼 낀 돌, 짜임이 굵은 직물처럼 미세한 지오메트리가 중요한 재질을 준비합니다.
2.
이 재질을 여러 각도에서 렌더링하여 학습 데이터를 생성합니다.
3.
NeuMIP 모델을 학습시켜 '신경 텍스처 피라미드'를 만듭니다.
4.
고품질 오프라인 렌더러에서 평평한 면에 이 재질을 적용하면, '신경 오프셋' 기술이 작동하여 시점에 따라 표면이 실제로 울퉁불퉁한 것처럼 보이게 합니다.
•
구체적인 예시
◦
실사 영화의 직물 클로즈업: 캐릭터가 입은 스웨터의 털실 짜임이나 카펫의 섬유 한 올 한 올이 살아있는 듯한 극사실적인 장면을 렌더링합니다.
◦
제품 광고: 거친 질감의 스피커 그릴이나 가죽 제품의 표면을 매우 상세하게 보여주는 고품질 제품 광고 이미지를 제작합니다.
•
미래 가능성무거운 변위 매핑(Displacement Mapping)을 대체할 수 있는 강력한 대안입니다. '신경 오프셋' 아이디어는 더욱 발전하여, 미래에는 실시간 렌더링에서도 저비용으로 고품질의 입체감을 표현하는 기술로 진화할 수 있습니다.
4. Neural Layered BRDFs (2021)
이 기술은 '재질 과학자의 복잡한 계산을 대신해주는 AI 계산기'와 같습니다. 다층 재질의 최종 결과를 예측하는 데 특화되어 있습니다.
•
활용 방법
1.
재질 제작 툴에서 여러 재질 층(예: 금속 위에 투명 코팅)을 정의합니다.
2.
기존에는 이 결과를 보려면 노이즈가 많은 느린 시뮬레이션을 돌려야 했습니다.
3.
대신, 각 층의 잠재 벡터를 이 신경망에 입력하면, 즉시 노이즈 없이 깨끗한 최종 결과값을 예측해 줍니다.
•
구체적인 예시
◦
차세대 재질 디자인 툴: 아티스트가 코팅의 두께나 거칠기를 슬라이더로 조절할 때, 그 결과가 물리적으로 정확하면서도 실시간으로 프리뷰에 반영되는 재질 저작 소프트웨어를 구현합니다.
◦
광학 시뮬레이션: 렌즈 코팅이나 특수 필름처럼 여러 얇은 층으로 이루어진 재료의 광학적 특성을 빠르게 시뮬레이션하는 과학 연구에 활용합니다.
•
미래 가능성'잠재 공간에서의 재질 연산(BRDF Algebra)'이라는 개념은 매우 혁신적입니다. 재질을 더하고 빼고 섞는 등의 창의적인 작업이 물리 법칙을 지키면서도 직관적으로 이루어지는 새로운 방식의 재질 디자인 워크플로우를 열 수 있습니다.
5 & 6. Unified Neural Encoding & NPs for Measured BRDFs
이 두 기술은 '현실 세계의 모든 재질을 디지털 도서관에 보관하는 사서' 역할을 합니다. 실제 재질의 측정 데이터를 압축하고, 편집하고, 재창조하는 데 중점을 둡니다.
•
활용 방법
1.
특수 장비로 실제 천, 가죽, 플라스틱, 금속 샘플의 외형 데이터를 스캔합니다. (이 원본 데이터는 용량이 매우 큽니다.)
2.
이 신경망 모델을 사용해 각 재질 샘플을 아주 작은 크기의 '잠재 벡터(Latent Vector)'로 압축합니다.
3.
이제 수천 개의 재질이 담긴 가벼운 디지털 라이브러리가 완성됩니다. 이 라이브러리에서 재질을 검색하고, 섞어서 새로운 재질을 만들 수도 있습니다.
•
구체적인 예시
◦
디지털 패션/자동차 산업: 실제 원단과 페인트 샘플을 스캔하여 만든 라이브러리에서 디자이너가 재질을 고르고, "A 원단과 B 원단의 특징을 50:50으로 섞은 새로운 느낌"을 즉시 시각화합니다.
◦
전자 상거래: 온라인 쇼핑몰에서 가방이나 신발 같은 제품을 선택하고, "가죽 종류를 이걸로 바꾸면 어떨까?"를 시뮬레이션하여 실제와 거의 같은 모습으로 미리 확인하는 가상 피팅을 구현합니다.
•
미래 가능성재질 데이터의 표준화를 이끌 수 있습니다. 미래에는 3D 모델뿐만 아니라 '재질' 자체도 하나의 잠재 벡터 파일로 공유될 수 있습니다. 이는 "데이터 기반의 재질 디자인" 시대를 여는 중요한 기반 기술이며, AI가 새로운 재질을 창조하는 연구로도 이어질 수 있습니다.
6. Conclusion: RT-NAM
RT-NAM은 영화 수준의 복잡한 재질을 실시간 게임에서 구현하기 위해 등장한 혁신적인 기술입니다. 핵심은 AI를 이용해 무거운 재질 데이터를 '베이킹'하여 가벼운 '통합 잠재 텍스처'로 압축하는 것입니다. 이렇게 압축된 재질은 게임 엔진에서 '신경 디코더'가 실시간으로 빠르고 효율적으로 렌더링합니다. 이 기술 덕분에 압도적인 성능으로 영화 같은 비주얼을 게임에서 즐길 수 있게 되어, 실시간 그래픽과 오프라인 VFX의 경계를 허무는 중요한 역할을 하고 있습니다.
•
LOD/메모리 강화 (from NeuMIP): RT-NAM의 MIP-Map 기반 LOD를 NeuMIP의 신경 텍스처 피라미드처럼 더 발전시켜, 메모리 효율과 필터링 품질을 한 단계 끌어올립니다.
•
안티에일리어싱/샘플링 안정화 (from DAP, LEADR): DAP의 사전 필터링 개념이나 LEADR 같은 신경 렌더링 AA 기술을 통합하여, 미세한 텍스처가 반짝이거나 지글거리는 현상 없이 안정적인 이미지를 확보합니다.
•
품질 상한선/정확도 향상 (from Layered BRDFs, BTF Encoding): Neural Layered BRDFs의 정교한 각도별 반응성이나, BTF 인코딩의 사실적인 측정 데이터 표현력을 학습 과정에 도입하여, 재질의 표현력과 물리적 정확도를 극한으로 높입니다.
•
데이터 비용 경감 (from NPs): Neural Processes의 강력한 압축 기술을 활용하여, 잠재 텍스처의 크기를 더욱 줄여 저장 공간과 전송 비용을 최소화합니다.
향후 고민 해봐야 할 부분
1.
동적 조명 일반화 (Dynamic Illumination Generalization)
현재 모델은 특정 조명 환경에 맞춰 '베이킹'되는 경향이 있습니다. 어떤 조명 조건에서도 물리적으로 정확하게 반응하는, 조명 변화에 강건한 모델 개발이 필요합니다.
2.
시간적 안정성 (Temporal Stability)
애니메이션이나 카메라 이동 시, 프레임 간 미세한 떨림(flickering) 없이 안정적인 결과물을 보장하는 기술이 중요합니다.
3.
물리 제약을 반영한 해석 가능한 디코딩 (Physically-Guided Interpretable Decoding)
현재의 신경 디코더는 '블랙박스'처럼 작동합니다. 에너지 보존 법칙 등 물리적 제약을 디코더 설계에 직접 반영하여, 결과물의 신뢰도를 높이고 예측 가능하게 만드는 연구가 필요합니다.