



그림 1: Radiance Regression Functions을 사용한 실시간 렌더링 결과입니다. 광택 있는 상호 반사(a), 여러 개의 지역 조명(b), 복잡한 기하학과 재료(c)를 가진 장면을 보여줍니다.
Abstract
우리는 동적인 지역 광원들이 있는 장면에서 빠르게 global illumination을 렌더링하기 위해 Radiance Regression Functions(RRF)을 제안해요. RRF는 표면 지점의 위치, 시점 방향, 조명 조건 같은 지역적 및 맥락적 속성에서 간접 조명 값으로의 비선형 매핑을 나타내요. RRF는 미리 계산된 음영 샘플로부터 회귀 분석을 통해 얻어지며, 이는 음영 데이터를 가장 잘 맞추는 함수를 결정해요. 주어진 장면에 대해, 음영 샘플은 오프라인 렌더러에 의해 미리 계산됩니다.
우리 접근 방식의 핵심 아이디어는 간접 조명 데이터의 비선형적인 일관성을 활용해서 RRF를 작고 빠르게 평가할 수 있도록 하는 거예요. RRF를 다층 비순환 피드포워드 신경망으로 모델링해서, 간접 조명의 기능적 근사를 제공하고 실행 시간에 효율적으로 평가할 수 있도록 했어요. 공간적으로 다양한 재질 특성을 가진 장면을 효과적으로 모델링하기 위해, 신경망 RRF의 입력으로 확장된 속성 집합을 사용해서 네트워크가 수행해야 하는 추론의 양을 줄였어요. 더 복잡한 기하학적 구조를 가진 장면을 처리하기 위해, RRF 모델의 입력 공간을 분할하고, 각각의 하위 공간을 별도의 작고 빠른 RRF로 표현했어요. 그 결과, RRF 모델은 점점 복잡해지는 장면의 기하학적 구조와 재질 변화에 잘 확장돼요. RRF 모델은 작고 평가가 쉬워서, 변화하는 카우스틱스와 다중 반사 고주파 광택 상호반사를 포함한 완전한 글로벌 조명 효과로 실시간 렌더링이 가능하답니다.
1 Introduction
글로벌 광선 전송은 장면에 시각적으로 풍부한 음영 효과를 제공하며, 이는 사실적인 렌더링의 필수 요소입니다. 많은 음영 세부 사항은 빛의 여러 번 반사에서 발생해요. 간접 조명으로 알려진 이 반사된 빛은 일반적으로 계산하기에 비용이 많이 듭니다. 간접 조명에 대한 가장 성공적인 기존 접근 방식은 사전 계산된 복사 전송(PRT)입니다 [Sloan et al. 2002; Ramamoorthi 2009]. 이는 글로벌 광선 전송을 사전 계산하고, 실행 시 빠른 렌더링을 위해 결과 PRT 데이터를 저장하죠. 하지만 PRT를 사용하더라도, 동적인 시점과 조명에서 실시간 렌더링은 여전히 어렵습니다.
실시간으로 간접 조명을 렌더링할 때 두 가지 주요 도전 과제가 있어요. 바로 동적인 지역 광원과 고주파수의 광택 있는 상호 반사를 처리하는 것이죠. 대부분의 기존 PRT 방법은 조명 환경을 장면 중앙의 한 지점에서 샘플링하고 그 결과를 환경 맵으로 저장해요. 그래서 이런 방법들은 장면의 다른 부분에서 지역 광원의 입사 복사를 정확하게 표현할 수 없답니다. 이 문제를 해결하기 위해 Kristensen 등 [2005]은 지역 광원의 위치를 촘촘히 설정하고 메쉬 정점은 드문드문 설정하여 사전 계산된 복사 전송을 사용했어요. 이 접근법은 확산 장면에서는 잘 작동하지만, 고주파수의 광택 있는 상호 반사나 카우스틱 같은 효과를 표현하는 데는 어려움이 있어요. 왜냐하면 메쉬 정점을 촘촘히 설정하여 사전 계산된 데이터를 저장하는 것이 너무 비싸기 때문이죠.
이러한 도전 과제에 맞서기 위해, 우리는 방사 회귀 함수(RRF)를 소개해요. 이 함수는 주어진 시야 방향과 조명 조건에 따라 각 표면 지점의 간접 조명 값을 반환하는 함수랍니다. 우리 접근법의 핵심 아이디어는 RRF를 표면 지점의 속성에 대한 비선형 함수로 설계하여, 간결하게 표현되고 빠르게 평가될 수 있도록 하는 것이에요. RRF는 오프라인 렌더링으로 사전 계산된 훈련 샘플에 대해 비선형 회귀 [Hertzmann 2003]를 사용하여 주어진 장면에 대해 학습돼요. 이 샘플은 무작위 시야와 조명 조건으로 렌더링된 일련의 표면 지점으로 구성되어 있어요. 주어진 장면에서 표면 지점의 간접 조명은 그 위치, 광원 위치, 시야 방향에 의해 결정되기 때문에, 우리는 이러한 속성을 지점의 기본 속성으로 정의하고 RRF를 이들에 대해 학습해요. 렌더링 시, 각 가시 표면 지점의 속성은 직접 조명을 평가하는 동안 얻어집니다. 간접 조명은
각 점의 속성을 사용해서 RRF로 계산한 후, 직접 조명에 더해서 전체 조명 솔루션을 만들어내요.
RRF을 모델링할 때 우리는 multilayer acyclic feed-forward neural network를 사용해요. 이 neural network는 보편적인 함수 근사기라서 [Hornik et al. 1989], 적절한 학습 샘플이 주어지면 간접 조명 함수를 원하는 정확도로 근사할 수 있답니다. 우리 neural network RRF를 설계할 때 주요 기술적 문제는 사전 계산된 학습 샘플을 효율적으로 사용해 좋은 근사를 얻는 방법이에요. 이 문제를 해결하기 위해 두 가지 기술을 제시해요. 첫 번째는 각 지점에서 속성 집합을 확장하여 공간적으로 변하는 표면 속성을 포함시키는 거예요. 기본 속성만으로 회귀를 수행할 수도 있지만, 이렇게 하면 학습 데이터의 최적 사용이 어렵고 근사 결과도 좋지 않아요. 표면의 법선과 재료 속성을 포함한 확장된 속성 집합에 대해 회귀를 수행하면, 확장된 속성에서 간접 조명으로의 매핑이 학습 샘플로부터 훨씬 쉽게 계산될 수 있어서 샘플 사용의 효율성이 크게 높아져요. 두 번째 기술은 RRF 입력 벡터의 공간을 분할하고 각 하위 공간에 대해 별도의 RRF를 맞추는 거예요. 단일 neural network가 간단한 장면의 간접 조명을 효과적으로 모델링할 수 있지만, 복잡한 장면을 모델링하기 위해서는 더 큰 네트워크 크기가 필요하고, 이는 학습 및 평가 시간이 크게 증가하게 돼요. 실행 시간 평가를 빠르게 하기 위해, 우리는 여러 개의 작은 네트워크를 사용해 장면 전체의 간접 조명을 더 효율적으로 표현한답니다.
우리의 주요 기여는 사전 계산된 global illumination을 실시간으로 렌더링하는 완전히 새로운 접근 방식이에요. 이 방법은 간접 global illumination을 직접적으로 근사화하는데, 이는 표면 위치, 시점 방향, 조명 방향의 6차원 함수로 매우 복잡하고 비선형적이랍니다. 신중하게 설계된 neural networks를 통해, 이 함수의 비선형적 일관성을 여섯 차원 모두에서 동시에 효과적으로 활용할 수 있어요. 반면에, PRT 방법은 일부 차원에서만 비선형적 일관성을 활용하고, 다른 차원에서는 밀집 샘플링에 의존하죠. 분석적 neural-network RRFs의 런타임 평가를 screen space에서 수행할 수 있고, 기존 렌더링 파이프라인에 쉽게 통합되는 deferred shading pass로 구현할 수 있어요. 그 결과, 사전 계산된 RRFs는 컴팩트하면서도 평가가 빠르고, 우리 방법은 caustics, 날카로운 간접 그림자, 고주파수의 광택 있는 상호 반사 같은 까다로운 시각 효과를 모두 실시간으로 렌더링할 수 있답니다. 우리 방법에서는 사전 계산된 neural networks가 객체 표면의 조명 효과에만 의존하고, 기본 표면 메싱에는 의존하지 않아요. 이는 고주파수 조명 효과를 위해 밀집 표면 메싱에 의존하는 PRT보다 더 확장 가능하게 만들어 줍니다.
우리가 알기로는, 우리 방법이 복잡한 장면에서 동적인 지역 조명과 시점을 고려한 전체 간접 조명 효과를 실시간으로 렌더링하는 첫 번째 솔루션을 제공해요. 복잡한 기하학적 구조와 다양한 재질을 가진 장면들(예: 그림 1)에서, 우리 기술은 512 x 512 이미지에서 초당 30 프레임으로 전체 글로벌 조명 효과를 렌더링할 수 있어요. 여기에는 caustics(그림 9(a)), 고주파수의 glossy interreflections(그림 8(d)), 네 번 이상의 빛 반사를 통해 생성된 glossy interreflections(그림 1(a)와 그림 10), 간접적인 강한 그림자(그림 1(c)), 그리고 복잡한 장면에서 다양한 조명 효과의 혼합(그림 12) 같은 시각적 효과들이 포함됩니다. 렌더링 시간은 주로 화면 크기에 따라 달라지며, 장면 내 객체 수에는 크게 영향을 받지 않아요. 우리 런타임 알고리즘은 화면 공간에서 모든 보이는 객체를 병렬로 렌더링하기 때문에, 많은 객체가 있는 더 큰 장면으로 확장하는 것이 꽤 쉬워요. 이러한 확장성은 복잡한 침실 장면(그림 12)과 간단한 Cornell 박스(그림 9(a))의 프레임 속도가 거의 동일한 결과에서 반영됩니다.
우리의 RRF 표현은 런타임 로컬이에요. 즉, 각 3D 객체의 RRF의 런타임 평가가 장면 내 다른 3D 객체의 RRF와 독립적이에요.
2 Related Work
공간의 제한으로 인해, 우리 연구와 직접적으로 관련된 최근 방법들만 논의할게요. 인터랙티브 글로벌 조명 기술에 대한 더 폭넓은 설명은 최근의 설문 조사 [Wald et al. 2009; Ramamoorthi 2009; Ritschel et al. 2012]를 참고하세요.
상호작용적 전역 조명 장면의 전역 조명을 빠르게 계산하기 위해 여러 방법이 제안되었어요. 한 가지 해결책은 GPU나 여러 개의 CPU를 사용해서 고전적인 전역 조명 알고리즘을 가속화하는 것이에요 [Wald et al. 2009]. 최근에는 Wang et al. [2009]이 GPU 기반의 photon mapping 방법을 제시해서 전체 전역 조명 효과를 렌더링했어요. McGuire et al. [2009]은 이미지 공간 photon mapping 알고리즘을 개발해서 CPU와 GPU를 모두 활용해 전역 조명을 구현했답니다. Parker et al. [2010]은 GPU와 다른 고도로 병렬화된 아키텍처를 위해 설계된 프로그래머블 레이 트레이싱 엔진을 설명했어요.
실시간 프레임 속도를 얻기 위한 또 다른 접근법은 정확성을 희생하고 속도를 높이는 것이에요. 이런 해결책 중 하나는 표면에서 반사되는 간접 조명을 가상의 점광원(VPLs) 세트로 근사하는 것이에요 [Keller 1997; Dachsbacher and Stamminger 2006; Ritschel et al. 2008; Nichols and Wyman 2010; Thiedemann et al. 2011]. 여러 방법들이 [Dong et al. 2007; Dachsbacher et al. 2007; Crassin et al. 2011] 장면 계층 구조를 통해 계산된 대규모 솔루션을 사용해 전역 조명을 근사하고 있어요. 더 최근에는, Kaplanyan et al. [2010]이 3D 장면 격자에서 빛의 전파를 계산해 동적 장면에서 저주파 간접 조명을 근사했어요. 이 방법은 빠르고 간결하지만, 확산 표면의 간접 조명만 시뮬레이션할 수 있어요.
계산 속도를 높이기 위한 다양한 전략에도 불구하고, 이러한 방법들의 처리 비용은 여전히 빛의 반사 횟수에 비례해요. 이는 그들이 시뮬레이션할 수 있는 상호 반사 효과를 효과적으로 제한하죠. 장면의 기하학이 더 복잡해지고 재료가 더 광택이 나면, 다양한 빛의 경로가 각 반사에서 더 큰 계산 비용을 초래해요. 이는 이러한 방법들의 확장성을 제한하기도 해요. 반면에, 우리 방법은 까다로운 효과인 카우스틱스와 고주파 광택 상호 반사를 포함한 모든 간접 조명 효과를 효율적으로 모델링해요.
Precomputed Light Transport, Precomputed radiance transfer (PRT) [Sloan et al. 2002; Ng et al. 2004; Ramamoorthi 2009]는 각 장면의 포인트에 대해 기본 조명 세트와 관련된 빛의 전달을 미리 계산해요. 그리고 이 데이터를 실시간으로 장면을 다시 조명하는 데 사용하죠. 초기 방법들은 [Sloan et al. 2002; Sloan et al. 2003] 구면 조화 함수(SH) 기저를 사용해서 저주파수의 전역 조명 효과만 지원했어요. 이후의 방법들은 각 표면 포인트에서 BRDF를 분해하고, 비선형 웨이블릿 [Liu et al. 2004; Wang et al. 2006]이나 구면 가우시안 기저 [Tsai and Shih 2006; Green et al. 2006]로 빛의 전달을 표현해서 모든 주파수의 전역 조명을 렌더링할 수 있게 했답니다. 하지만, 이 방법들은 먼 조명만 지원한다는 한계가 있어요.
지역 광원을 지원하기 위해, Kristensen et al. [2005]는 2D SH 기저를 사용해서 반사된 복사를 모델링했어요. 이는 조밀한 지역 광원 위치에 대해 드문드문한 메쉬 꼭짓점에서 샘플링을 하죠. 빛 공간 샘플은 클러스터링으로 압축되고, 공간 샘플은 영역으로 나누어져 클러스터링 PCA를 사용해 압축됩니다. 렌더링 중에는, 인근 광원에서 샘플링된 데이터가 보간되어 새로운 광원 위치에 대한 렌더링 결과를 생성해요.
데이터가 드문드문한 메쉬 꼭짓점에서 샘플링되기 때문에, 이 방법은 고주파수 조명 효과나 caustics를 잘 표현하지 못해요. 또한, 광택 있는 물체에서 시점에 따라 달라지는 간접 조명 효과를 표현하려면 고차원 SH 기저가 필요하답니다.
Direct-to-indirect transfer 방법 [Hašan et al. 2006; Wang et al. 2007; Kontkanen et al. 2006; Lehtinen et al. 2008]은 장면의 직접 조명에 대해 샘플링된 표면 위치에서 간접 조명을 미리 계산해요. 렌더링할 때는 먼저 장면의 직접 음영을 계산하고, 이를 사용해 간접 조명 효과를 재구성하죠. 이 방법은 지역 조명 소스를 지원할 수 있지만, 고주파 간접 조명을 표현하려면 표면을 촘촘히 샘플링해야 해서 저장 비용이 크고 렌더링 성능이 느려진답니다.
Regression Methods 회귀 방법은 그래픽스에서 널리 사용되고 있어요 [Hertzmann 2003]. 예를 들어, Grzeszczuk et al. [1998]은 신경망을 사용해 객체의 동작을 모방하고, 시뮬레이션 없이 물리적으로 현실적인 애니메이션을 생성했어요. 신경망은 가시성 계산에도 사용되었답니다. Dachsbacher [2011]는 신경망을 이용해 다양한 가시성 구성들을 분류했어요. Nowrouzezahrai et al. [2009]는 동적 객체의 저주파 미리 계산된 가시성 데이터를 신경망에 맞췄어요. 이러한 가시성 신경망은 동적 장면의 직접 음영을 계산할 때 저주파 자기 그림자를 예측할 수 있게 해줍니다. 마지막으로, Meyer et al. [2007]는 통계적 방법을 사용해 수백 개의 키 포인트를 선택하고, 선형 부분 공간을 형성했어요. 이 방법은 계산을 크게 줄여주지만, 키 포인트에서 전역 조명을 렌더링하는 것은 여전히 시간이 많이 걸린답니다.
3 Radiance Regression Functions
이 섹션에서는 먼저 radiance regression 함수 Φ를 소개하고, 미리 계산된 간접 조명 데이터를 이용한 regression을 통해 어떻게 얻을 수 있는지 설명할게요. 그 다음, 함수 Φ를 neural network ΦN으로 모델링하는 방법과 함수 Ф№의 분석적 표현을 유도하는 방법을 설명해요. 이후에는 neural network의 구조와 학습에 대해 논의하고, 더 기술적인 세부 사항은 부록 A에 남겨둡니다. 마지막으로, 함수 Ф№를 사용한 간단한 렌더링 예제를 보여드릴게요.
움직이는 점광원에 의해 조명되는 정적 장면에서, 위치 Xₚ에 있는 불투명 표면 점에서 방향 V로 본 반사된 radiance는 반사 방정식 [Cohen et al. 1993]으로 설명됩니다.
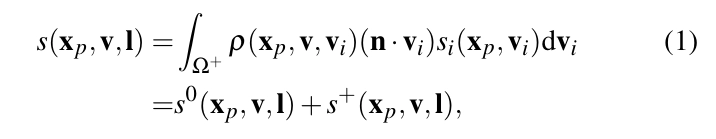
여기서 I는 점광원의 위치를 나타내고, p와 n은 위치 Xp에서의 BRDF와 표면 법선을 나타내며, sᵢ(xₚ,Vᵢ)는 방향 Vᵢ로부터 Xp로 들어오는 radiance를 나타냅니다. 매개변수화된 BRDF p는 다음과 같이 반사 매개변수 a(xₚ)의 집합을 가진 폐쇄형 함수 Pc로 설명될 수 있어요.
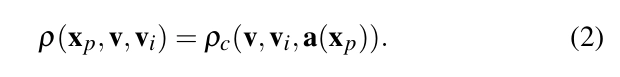
공간적으로 변하는 매개변수화된 BRDF의 경우, 공간적으로 변하는 유일한 부분은 매개변수 벡터 a(xₚ)이며, 이는 텍스처 맵의 집합으로 표현되어 그래픽 파이프라인에서 효율적으로 사용할 수 있습니다.
방정식 (1)에서 보이는 것처럼, 반사된 radiance s는 직접 조명과 간접 조명에 해당하는 국소 조명 성분 s⁰와 간접 조명 성분 s⁺로 나눌 수 있어요.
각각입니다. 로컬 조명 성분 s⁰는 기존 방법들(e.g. [Donikian et al. 2006])로 효율적으로 계산할 수 있기 때문에, 우리는 간접 조명 s⁺에 집중해요. 이 간접 조명은 간접 조명에서 sᵢ(xₚ,Vᵢ)에 대한 들어오는 복사휘도 기여로부터 발생하거든요. 단위 강도의 점광원이 위치 I에 있을 때, 함수 s⁺(xₚ,v,I)는 시야 방향 V로의 간접 조명 성분을 나타내요.
식 (1)과 식 (2)를 결합하면, 간접 조명 성분을 다음과 같이 표현할 수 있어요.
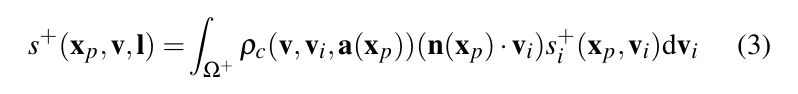
(3) 여기서 sᵢ는 들어오는 복사휘도의 간접 성분 sᵢ(xₚ,Vᵢ)입니다. 여기서는 표면 법선 n을 n(xₚ)로 대체했는데, 이는 위치 Xp에서의 표면 법선 n이 Xp의 함수로 계산된다는 사실을 명확히 하기 위함이에요. 식 (3)에서 우리는 간접 조명 s⁺가 새로운 함수 s⁺ₐ로 다시 쓸 수 있음을 관찰할 수 있어요. 이 함수는 표면 법선과 BRDF 매개변수 벡터를 포함한 확장된 속성 집합을 가지고 있답니다.
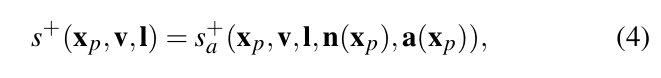
간접 조명 ⁺(xₚ,v,l)은 잘 정의된 함수예요. 주어진 장면에서, 우리는 어떤 표면 지점, 광원 위치, 시야 방향에 대해서도 s⁺를 얻기 위해 광 전송 계산을 수행할 수 있거든요. 하지만, s⁺는 일반적으로 계산하는 데 시간이 많이 걸려요. 이 연구에서는 복사휘도 회귀 함수 Φ를 소개하는데, 이 함수는 s⁺를 최소자승법으로 근사하고, 컴팩트하고 평가가 빠르며 실시간 렌더링에 잘 맞도록 설계되었답니다.
회귀를 통한 근사화 간접 조명 s⁺의 근사화를 회귀 문제로 다루고, 학습 데이터 세트로부터 회귀 함수 Φ를 학습해요 [Hertzmann 2003]. 원칙적으로는 Φ를 기본 속성 집합 Xₚ, V, I만으로 정의하는 것이 충분할 거예요. 왜냐하면 이들은 주어진 장면에서 특정 지점의 간접 조명을 결정하는 최소한의 요소들이거든요. 하지만 표면 법선 n과 반사율 매개변수 a의 값이 장면 영역에 따라 크게 달라질 수 있어서, 간접 조명 s⁺(xₚ,v,I)는 기본 속성만으로는 매우 복잡해질 수 있어요. 따라서, 확장된 속성 집합 Xₚ, V, I, n, a로 회귀 함수 Φ를 정의하면, 표면의 양 n과 a를 더 이상 학습 데이터에서 추론할 필요가 없기 때문에 비선형 회귀를 통해 s⁺를 더 효과적으로 근사화할 수 있어요. 그래서 우리는 표면 지점 p에서의 복사 회귀 함수 Φ를 Φ(xₚ,v,l,n,a)로 정의하고, 이는 R¹²⁺ⁿₚ에서 R³로의 맵을 나타내요. 여기서 nₚ는 공간적으로 변하는 BRDF의 매개변수 수이고, R³는 세 개의 RGB 색상 채널을 포함해요.
우리가 사용하는 학습 데이터는 간접 조명 (xₚ,v,I)을 샘플링한 N개의 입력-출력 쌍으로 구성돼요. 각 쌍은 예제라고 불리며, i번째 예제는 (xⁱ,yⁱ) 쌍으로 구성돼요. 여기서 xⁱ는 입력 벡터이고 yⁱ는 해당 출력 벡터예요. 복사 회귀 함수 Φ는 최소제곱 오차를 최소화함으로써 결정돼요:
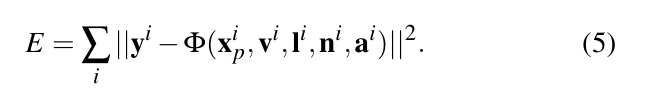
학습 포인트 (xⁱ,yⁱ)를 통과하고, 따라서 식 (5)를 최소화하는 많은 함수가 존재할 수 있어요. 특정 솔루션은 학습 데이터에서 보지 못한 새로운 입력 벡터 (xₚ,v,l,n,a)에서 간접 조명 (xₚ,v,I)의 근사화가 좋지 않을 수 있어요. 더 나은 근사화를 위해서는 더 큰 학습 세트가 필요하답니다.
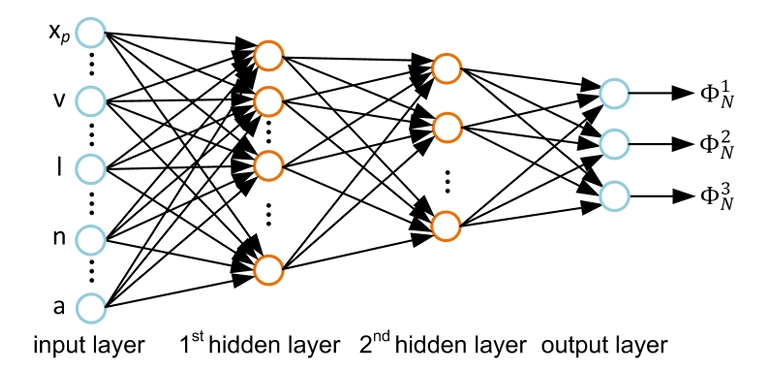
그림 2: 비순환 피드포워드 신경망을 사용하여 RRF를 모델링한 모습이에요. 이 신경망은 입력 벡터 (xₚ,v,l,n,a)로부터 방정식 (8)에서 정의된 출력 RGB 구성 요소로의 매핑을 정의해요.
크기 N을 사용하면 입력 공간을 더 촘촘하게 샘플링할 수 있어요. 하지만 실제로 N은 제한되어야 하고, 유용한 회귀 함수 Φ를 얻기 위해 방정식 (5)의 가능한 해를 더 작은 함수 집합으로 제한해야 해요. 이렇게 제한된 모델을 구조적 회귀 모델이라고 부르는데요 [Hastie et al. 2009]. 가장 간단한 것 중 하나는 선형 모델인데, 이는 간접 조명 s⁺ (xₚ)에 대해 잘 작동하지 않아요. 그래서 이번 연구에서는 신경망을 회귀 모델로 선택했어요.
신경망을 선택한 주된 이유는 상대적으로 컴팩트하고 평가 속도가 빠르기 때문이에요. 이는 실시간 렌더링에 중요한 요소죠. 신경망은 또한 간단하면서도 강력한 비선형 모델을 제공하기 때문에 우리 문제에 잘 맞아요. 신경망은 선형 회귀 모델의 비선형 일반화로 볼 수 있어요. 게다가 신경망은 강력한 표현력을 가지고 있어서 범용 함수 근사기로 널리 사용되고 있어요. 특히, 유한한 영역의 연속 함수나 제곱 적분 가능한 함수는 하나 또는 두 개의 은닉층을 가진 피드포워드 네트워크로 임의의 작은 오차로 근사할 수 있답니다 [Hornik et al. 1989; Blum and Li 1991]. 간접 조명 함수 s⁺는 이러한 함수 범주에 속해요.
Neural Network RRF 방사율 회귀 함수(radiance regression function)를 신경망으로 표현하면, RRF를 새로운 벡터 W로 다시 쓸 수 있어요. 여기서 W는 신경망 ΦN의 가중치 벡터이고, W의 구성 요소들은 Ф№의 가중치라고 불러요. 이제 식 (5)는 식 (6)으로 바뀌어요. Фₙ을 찾으려면, 신경망의 구조를 선택하고 E(w)를 최소화하여 가중치를 결정해야 해요.
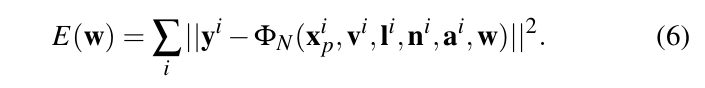
신경망은 가중치가 있는 방향 그래프로, 노드들이 층으로 구성되어 있어요. 엣지의 가중치가 가중치 벡터 W의 구성 요소를 이루죠. 우리가 사용하는 네트워크는 두 개의 숨겨진 층을 가진 비순환 피드포워드 네트워크예요. 그림 2에 나와 있듯이, 각 노드는 이전 층의 모든 노드와 방향 엣지로 연결되어 있어요. 그래서 i번째 층의 노드는 이전 층의 모든 노드로부터 입력을 받아요. 이 그래프는 첫 번째 층, 즉 입력층의 노드를 통해 입력을 받고, 마지막 층, 즉 출력층의 노드를 통해 출력을 내보내요. 입력층의 노드들은 RRF의 입력 벡터 (xₚ,v,l,n,a)의 차원에 해당하고, 출력층은 간접 조명의 RGB 색상 채널 각각에 해당하는 세 개의 노드로 구성되어 있어요. 입력층과 출력층 사이의 층들은 숨겨진 층이라고 불러요.
각 노드는 이전 층에서 입력을 받아서, 가중치 벡터 W의 구성 요소 {wᵢⱼₖ}를 기반으로 출력을 계산해요. i번째 층의 j번째 노드를 생각해 볼게요. 이 노드의 출력은 nⁱⱼ이고, wⁱⱼ0는 이 노드의 바이어스 가중치랍니다. 각 은닉층에서 nⁱⱼ는 다음과 같이 그 층의 모든 노드의 출력으로부터 계산돼요:
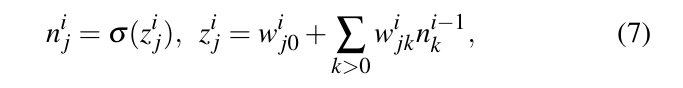
k>0 여기서 wijk는 이전 층의 k번째 노드에서 현재 층의 j번째 노드로 가는 방향성 있는 엣지의 가중치예요. 노드는 σ(zⁱⱼ) 값을 출력하는데, 여기서 σ는 쌍곡선 탄젠트 함수랍니다. 이 함수는 = = 1이고, zij는 이전 층의 출력의 선형 결합이에요. 쌍곡선 탄젠트 함수는 인기 있는 시그모이드 함수와 동일해요 :) = 1/(1 + ²). σ와 σ₁ 모두 스텝 함수(Heaviside 함수)와 비슷하지만, σ와 σ₁는 연속적이고 미분 가능해서 수치 계산을 크게 용이하게 해줘요. 출력층의 경우, nⁱⱼ는 단순히
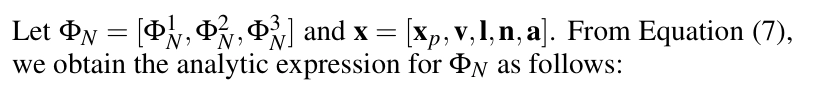
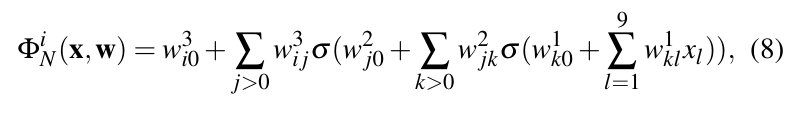
여기서 i = 1,2,3이고 xₗ은 입력 벡터 X의 l번째 구성 요소예요. 쌍곡선 탄젠트 함수 σ가 Ф№의 유일한 비선형 요소라는 점을 주목하세요. 실제로, 만약 ΦN의 모든 쌍곡선 탄젠트 함수를 선형 함수로 대체하면, ΦN은 선형 모델이 돼요. 이런 의미에서, 신경망은 단순한 선형 회귀 모델의 비선형 일반화라고 할 수 있답니다.
신경망 구조 및 학습 신경망 구조는 그림 2에 나와 있는 형태로 선택했어요. 이 구조는 다음과 같은 고려사항에 기반하고 있답니다. 입력층과 출력층은 입력과 출력 형식에 따라 고정되어 있으니까, 결정해야 할 것은 숨겨진 층의 수와 각 층의 노드 수뿐이에요. 이론적으로는 하나의 숨겨진 층을 가진 신경망이 연속적인 함수를 임의의 정확도로 근사할 수 있다고 해요 [Hornik et al. 1989]. 하지만 간접 조명 함수 s⁺는 많은 능선과 골짜기를 포함하고 있어서, 이런 유형의 함수는 하나의 숨겨진 층만으로는 많은 노드가 필요해요. 반면에 두 개의 숨겨진 층을 사용하면 상대적으로 적은 수의 노드로 효과적으로 근사할 수 있답니다 [Chester 1990; FAQ]. 간접 조명 s⁺의 불연속성은 큰 가중치를 사용하면 쌍곡 탄젠트 함수가 본질적으로 계단 함수가 되기 때문에 문제가 되지 않아요. 두 개 이상의 숨겨진 층을 가진 신경망은 훈련이 어렵기 때문에 함수 근사에 일반적으로 사용되지 않아요. 부록 A에서는 두 개의 숨겨진 층에 있는 노드 수를 어떻게 설정했는지 논의하고 있어요.
신경망 ΦN은 수치 최적화를 사용하여 훈련 세트에 대해 식 (6)에서 정의된 E(w)를 최소화하는 W의 가중치를 찾음으로써 훈련돼요. 이 훈련 세트는 빛의 위치와 시점을 샘플링하고, 시점에서 장면의 점들로 광선을 추적하여 간접 조명을 결정함으로써 구성돼요. 훈련 샘플의 수는 W의 가중치 수의 대략 10배 정도랍니다. 훈련 과정과 과적합 같은 문제에 대한 자세한 내용은 부록 A에 설명되어 있어요.
신경망을 학습한 후에는 각 장면의 간접 조명을 다양한 조명과 시점 조건에서 렌더링할 수 있어요. 특정 시점과 조명 위치가 주어지면, 먼저 각 화면 픽셀의 가시 표면 점과 그 표면 위치 Xₚ를 계산해요. 입력 벡터의 각 속성은 [-1.0, 1.0] 범위로 스케일링되죠. 그런 다음 각 픽셀에 대해 스케일링된 입력 벡터를 사용해요.

그림 3: 표면 법선과 SVBRDF 속성 유무에 따른 RRF 비교. (a) 경로 추적에 의한 실제 값. (b) 표면 법선과 SVBRDF 매개변수를 포함한 확장된 속성을 가진 RRF. (c) 기본 속성에 SVBRDF 매개변수만 추가한 RRF. (d) 표면 법선이나 SVBRDF 매개변수 없이 기본 속성만 가진 RRF.
v는 신경망 ΦN에 입력되어 간접 조명 값을 계산해요. 이렇게 얻은 간접 조명 결과는 직접 조명 결과에 더해져서 최종 렌더링을 생성하게 돼요.
ΦN의 실행 시간 평가가 쉬운 이유는 그래픽 파이프라인에서 a(xₚ)와 n(xₚ)를 사용할 수 있기 때문이에요. 앞서 말했듯이, a(xₚ)는 텍스처 맵 세트로 저장되어 텍스처 매핑을 통해 접근할 수 있답니다. n(xₚ)도 이용 가능한데, 이는 방정식 (1)에서 직접 조명 s⁰를 평가할 때 계산되기 때문이에요. 반면에, 다른 장면 점들의 거리와 각도 같은 간접 조명에 영향을 미치는 다른 요소들은 입력 벡터에 포함시키기에는 적합하지 않아요. 이런 값들은 그래픽 파이프라인에서 쉽게 얻을 수 없을 뿐만 아니라, 이를 표현하기 위해 상당히 많은 입력이 필요해져서 학습해야 할 신경망 가중치의 수가 크게 증가할 거예요. 각 추가 입력은 신경망에 n₁개의 가중치를 더하는데, 여기서 n₁은 첫 번째 은닉층의 노드 수예요. RRF의 설계 원칙이 컴팩트하고 평가가 빠르게 하는 것이기 때문에, 추가 입력의 수를 제한하고 쉽게 얻을 수 있는 값들만 선택해요.
그림 3은 두 개의 객체, 즉 구와 상자로 구성된 간단한 장면의 렌더링 결과를 보여줘요. (a)의 실제 이미지(ground truth)는 학습 데이터를 생성할 때 사용된 물리 기반 오프라인 경로 추적기 [Lafortune and Willems 1993]로 렌더링되었어요. 여기서 구는 노멀 맵과 공간적으로 변하는 등방성 Ward BRDF [Ward 1992]로 텍스처링되었고, 이 BRDF의 공간적으로 변하는 매개변수 a(xₚ)는 3D 확산 및 반사 색상과 1D 반사 거칠기를 포함하는 7D 벡터랍니다. 동일한 학습 데이터 세트를 사용해서 (b), (c), (d)를 생성했어요. 기본 속성만 있는 RRF(d)나 기본 속성에 SVBRDF 매개변수만 추가한 RRF(c)와 비교했을 때, 표면 속성을 모두 포함한 확장된 속성은 표면 세부 사항을 더 충실하게 재현해요(b). Cook-Torrance 모델, BlinnPhong 모델, 비등방성 Ward 모델, Ashikhmin-Shirley 모델과 같은 다른 자주 사용되는 매개변수 BRDF 모델도 이 방식으로 효과적으로 활용할 수 있답니다.
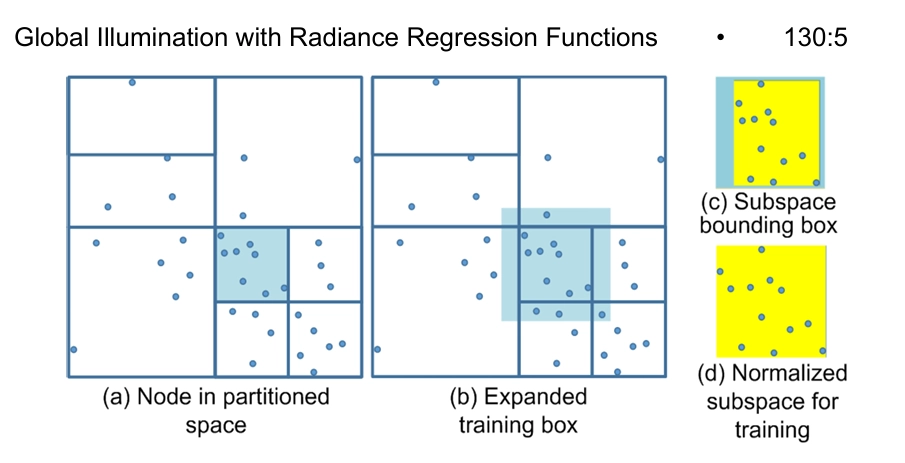
그림 4: 여러 RRF를 맞추기 위한 입력 공간의 분할.
4 장면 복잡성 처리
입력 공간 분할 지금까지는 많은 객체가 있는 복잡한 장면을 고려하지 않았어요. 이론적으로는, 이런 장면을 숨겨진 층에 많은 노드를 가진 단일 RRF로 근사할 수 있답니다. 하지만 이렇게 하면 학습해야 할 가중치의 수가 숨겨진 층 노드 수에 따라 제곱으로 증가하기 때문에 RRF 학습이 상당히 복잡해져요. 더 중요한 것은, 더 큰 네트워크는 평가 비용도 훨씬 더 커지게 되는데, 이 역시 숨겨진 층 노드 수에 따라 제곱으로 증가해요. 결과적으로, 신경망을 확장하는 것은 실시간 렌더링에 대해 빠르게 비현실적이 되어버려요.
이 문제를 해결하기 위해, 우리는 neural network의 입력 벡터가 펼치는 공간을 여러 영역으로 나누고, 각 영역의 학습 데이터에 별도의 RRF를 맞추는 방법을 사용해요. 입력 공간을 나누기 위해, 장면이 이미 콘텐츠 생성 과정에서 여러 3D 객체로 나뉘어 있다는 점을 활용합니다. 일반적으로 각 객체는 장면 내 다른 객체와 위상적으로 분리되어 있거든요. 각 3D 객체에 대해, 우리는 kd-tree를 사용해 입력 공간을 세분화해요. kd-tree는 고차원 공간을 재귀적으로 세분화하는 데 적합한 이진 트리입니다. 이렇게 나누면, 입력에 대한 간접 조명 값을 계산할 때 kd-tree 검색과 작은 RRF 평가만 필요하게 되죠. 이는 매우 빠릅니다. 각 객체의 입력 공간은 n차원 박스이고, 우리는 그 kd-tree를 Σ라고 부릅니다. Σ의 모든 비말단 노드 V는 n차원 점으로, 이는 암묵적으로 현재 레벨의 박스를 다음 레벨의 두 박스로 나누는 분할 초평면을 생성합니다. 각 비말단 노드는 n차원 중 하나인 xᵢ와 연결되어 있어, 분할 초평면이 그 차원의 축에 수직이 되도록 합니다. 간단하게 하기 위해, 우리는 항상 현재 레벨의 박스를 중간에서 나누어, 두 개의 동일한 크기의 다음 레벨 박스를 생성합니다. 분할 초평면의 왼쪽 박스는 노드 v의 왼쪽 서브트리에 속하고, 오른쪽 박스는 오른쪽 서브트리에 속합니다. 마지막으로, kd-tree Σ의 말단 노드는 더 이상 세분화되지 않는 박스를 보유합니다.
그림 4는 (a)에서 강조된 노드 v에서의 세분화 처리를 보여줍니다. 노드 V와 관련된 n차원 박스 w 내의 훈련 샘플을 가져와 RRF를 맞춥니다. 인접한 박스 간의 불연속성을 줄이기 위해, (b)에서 보여지는 것처럼 각 차원에 따라 박스 w를 10% 확장하여 이웃 박스에서 추가적인 훈련 샘플을 포함합니다. 작은 전이 구역을 만들고 인접한 RRF를 선형 보간하여 인접 박스 경계의 불연속성을 더욱 줄일 수 있습니다. 그러나 실험을 통해 이것이 불필요하다는 것을 발견했습니다. 훈련 전에, (c-d)에서 보여지는 것처럼 샘플의 경계 상자를 단위 초입방체로 정규화합니다. 훈련 및 예측 오류가 모두 5% 미만(상대 오류)일 때 노드 V의 세분화를 중지합니다. 여기서 예측 오류는 모든 훈련 샘플 풀에서 제거된 테스트 세트를 사용하여 RRF를 평가하여 측정됩니다. 우리의 실험에서는 30%를 제거합니다.
테스트를 위한 훈련 샘플.
노드 V의 추가 분할이 필요한 경우, V를 분할하기 위해 축 xᵢ를 선택해야 합니다. 최고의 분할 축은 V의 자식 노드에서 가장 작은 훈련 및 예측 오류를 생성하는 축입니다. 이 축을 찾는 무차별 대입 방법은 모든 축을 시도하고 결과 자식 노드에서 RRF 적합 및 테스트 프로세스를 수행하는 것입니다. 대안으로, 우리는 무작위로 분할 축을 선택할 수 있으며, 이는 우리의 실험에서 대략 10% 더 높은 RRF 적합 및 테스트 오류를 초래합니다. 이 논문에서 보고된 결과를 위해, 우리는 분할 축을 식별하기 위해 무차별 대입 방법을 사용합니다.
기본 속성만 사용하는 대신 확장된 속성을 사용하면 입력 공간의 차원이 늘어나게 돼요. 이렇게 되면 의미 없는 셀들이 많아져서 세분화 과정이 비효율적일 수 있답니다. 하지만 s⁺가 s⁺보다 더 높은 차원의 함수처럼 보일지라도, s⁺의 본질적인 차원은 s⁺보다 크지 않아요. 왜냐하면 a와 n은 독립적인 변수가 아니라 이미 s⁺의 입력 벡터에 속성으로 포함된 Xp의 함수이기 때문이에요. 함수 s⁺는 단순히 원래 함수 s⁺가 더 높은 차원 공간에 포함된 형태랍니다. 우리 kd-tree 세분화 기준은 오로지 적합성과 예측 오류에 의해 결정되기 때문에, 셀은 필요할 때만 생성돼요. 즉, 오류가 너무 클 때만 생성된답니다. 이 오류 기반 세분화 기준 덕분에 불필요한 셀이 생성되지 않아요.
kd-tree를 사용하는 장점 중 하나는 quadtree나 octree 같은 분할 구조와 달리 모든 차원에서 공동으로 노드를 분할하지 않는다는 점이에요. 이렇게 하면 고차원 공간에서 노드가 과도하게 많아질 수 있고, 그 결과로 불필요하게 많은 RRF가 생길 수 있답니다.
조명 복잡도 지금까지의 논의는 단일 점 광원을 중심으로 했어요. 하지만 어떤 색상의 유한한 수의 지역 광원도 쉽게 처리할 수 있답니다. 더 중요한 것은, RRF Фₙ를 다시 계산하지 않고도 이 작업을 할 수 있다는 점이에요. K개의 광원이 있고, k번째 광원이 위치 1ₖ에 있다고 가정해 보세요. ΦN은 단위 광원에 대해 계산되며, 광원의 세기에 따라 광 전달이 선형이기 때문에 간접 조명 s⁺는 다음과 같이 쓸 수 있어요.
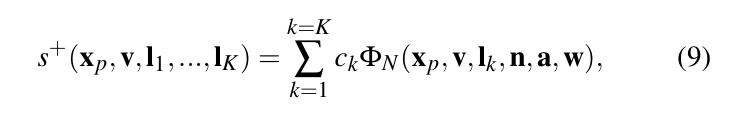
여기서 cₖ는 k번째 빛의 색을 의미해요. 이 방정식은 빛의 위치와 색상이 사용자 제어 하에 독립적으로 자유롭게 변경될 수 있는 변수임을 암시해요. 합의 각 항이 동일한 RRF Фₙ에 의해 평가되기 때문에, 여러 점광원에 대해 추가적인 학습이나 저장 비용이 필요하지 않아요. 실행 시에는 여러 빛의 위치에 대한 ΦN 평가와 각 빛에 대한 직접 조명 계산이 주요 비용이에요.
빛의 전송의 선형성 덕분에, 우리는 동일한 RRF Ф№를 사용해서 어떤 색상의 지역 조명도 유한한 개수로 처리할 수 있어요. 이 특성이 없었다면, 모든 빛의 위치와 색상을 Фₙ의 입력 변수로 동시에 포함해야 했을 거예요. 그러면 학습과 저장이 너무 비싸서 감당할 수 없는 신경망이 되었겠죠.
5 구현 및 결과
우리는 제안된 분할 및 학습 알고리즘을 200개의 노드로 구성된 PC 클러스터에 구현했어요. 각 노드는 다음과 같이 구성되어 있어요.

표 1: RRF 학습에 대한 성능 데이터.
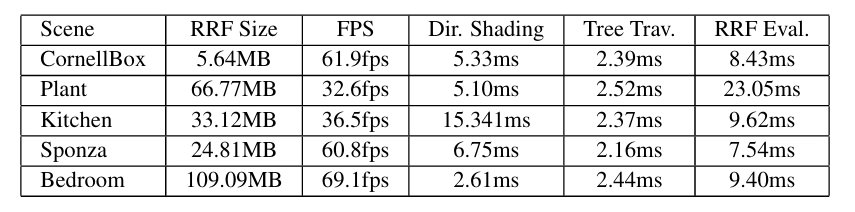
표 2: RRF 기반 렌더링의 성능 데이터입니다. Dir. shading은 직접 음영 계산 시간을 나타내고, Tree Trav.는 파티션 트리 탐색 시간을 의미해요. RRF Eval.은 RRF 평가 시간을 나타냅니다.
두 개의 Quadcore Intel Xeon L5420 2.50G CPU와 16GB 메모리를 사용했어요. 훈련 세트의 간접 조명 값은 같은 클러스터에서 Mitsuba 렌더러 [Jakob 2010]를 사용해 계산했어요. 실시간 렌더링 알고리즘은 2GB 비디오 메모리를 가진 nVidia GeForce GTX 680에서 구현되었어요. 직접 조명 구성 요소는 variance shadow maps [Donnelly and Lauritzen 2006]을 사용하는 프로그래머블 렌더링 파이프라인으로 계산했어요.
실행 시에는 CUDA를 사용해 각 화면 픽셀의 간접 조명 값을 다음과 같이 계산해요. 모든 픽셀의 입력 벡터는 지연 음영 파이프라인의 G-buffer에서 변환된 행렬 M에 저장되며, 각 행렬 열에는 하나의 입력 벡터가 들어가요. 각 3D 객체에 대해 kd-tree가 구축되기 때문에, 입력 벡터와 함께 객체 ID도 저장해서 해당 kd-tree를 쉽게 찾을 수 있게 했어요. kd-tree 탐색을 위한 CUDA 커널에서는 각 스레드가 행렬 M에서 입력 벡터 X를 읽고, kd-tree를 찾아 내려가면서 리프 노드에 도달해요. 거기서 X를 포함하는 파티션의 신경망 ΦN의 ID를 가져오죠. 그런 다음 신경망 CUDA 커널에서 각 스레드는 입력 벡터 X를 신경망 ΦN에 입력하고, 식 (8)에 따라 픽셀의 색상 값을 평가해요.
우리 방법을 다양한 장면에 적용해 봤어요. Cornell Box 장면(Figure 9 a-b)은 확산 표면과 반사 표면 사이의 색 번짐과 카우스틱 같은 풍부한 상호 반사 효과를 포함하고 있어요. Plant 장면(Figure 9 c-d)에서는 식물 모델의 세밀한 기하학적 구조가 복잡한 가림과 가시성 변화를 일으켜요. Kitchen 장면(Figure 10)은 반사 표면 사이의 강한 상호 반사로 인해 발생하는 시점 의존 간접 조명 효과를 보여주기 위해 사용됐어요. 또한, 두 개의 복잡한 장면에서 우리 방법의 확장성을 테스트했어요. Sponza 장면(Figure 11)은 복잡한 기하학적 구조를 가진 확산 표면으로 구성되어 있어요. Bedroom 장면(Figure 12)에서는 다양한 모양과 재질의 객체들이 함께 배치되어, 서로 다른 조명과 시점 조건에서 풍부하고 복잡한 음영 변화를 보여줘요.
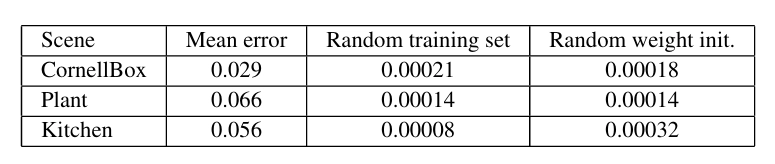
Table 3: 세 장면의 렌더링 정확도와 다양한 훈련 데이터 세트 선택 및 초기 신경망 가중치 값에 대한 강건성을 보여줍니다.
Radiance Regression Functions를 이용한 Global Illumination
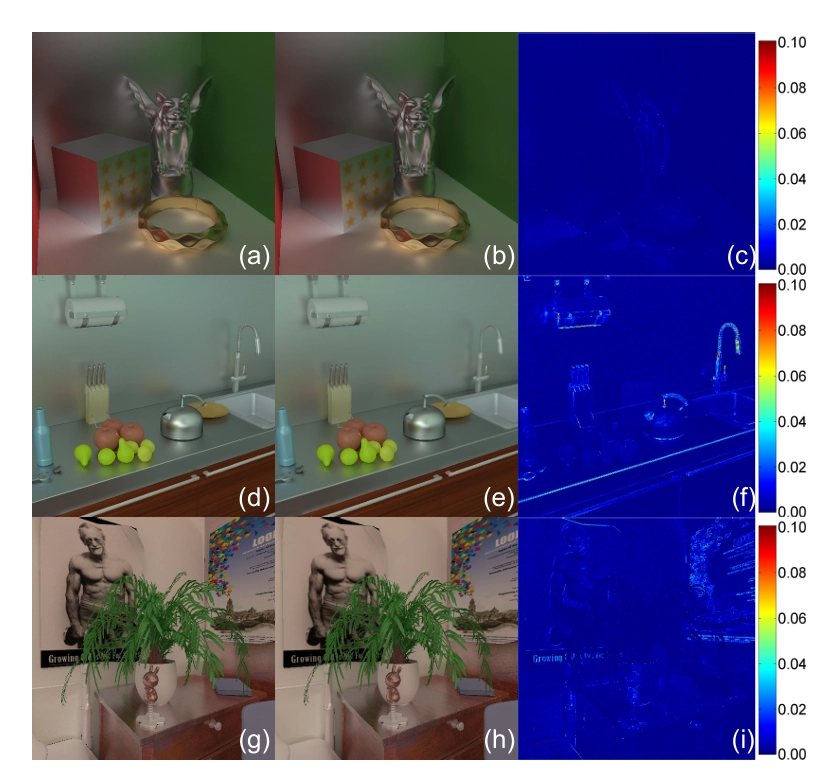
Figure 5: 우리 방법으로 렌더링한 결과와 경로 추적의 결과를 비교한 그림이에요. 간접 조명 결과만 보여주고 있어요. 왼쪽은 경로 추적 결과, 가운데는 우리 렌더링 결과, 오른쪽은 두 결과 간의 차이를 나타내요.
각 장면에 대한 실행 시간 렌더링 성능은 표 2에 나와 있어요. Plant 장면의 RRF 평가 시간이 비교적 긴 이유는 복잡한 기하학 때문인데요, 이로 인해 많은 인접 포인트들이 서로 다른 파티션에 속하게 되어 데이터 일관성이 낮아지거든요. 모든 렌더링의 이미지 해상도는 512 X 512입니다.
방법 검증 우리는 Cornell Box, Plant, Kitchen 장면을 사용해 RRF 학습 및 렌더링 방법을 검증해요. 정확도를 평가하기 위해, 우리 방법으로 렌더링한 이미지를 Mitsuba 경로 추적으로 생성한 기준 이미지와 비교했어요. 이 실험에서는 512 X 512 해상도의 이미지를 400장 렌더링했는데, 20개의 무작위로 선택된 뷰 위치와 20개의 무작위 조명 위치의 조합을 사용했어요. 렌더링 오류 E는 400개의 이미지 쌍의 제곱 평균 제곱근 오차로 계산했어요. 표 3의 첫 번째 열에는 세 장면에 대한 평균 오류가 나와 있어요. 그림 5에는 우리의 결과, 기준 이미지, 그리고 그 차이가 나와 있답니다. RRF가 새로운 조명 아래에서 표면 포인트의 간접 조명 값을 정확하게 예측하고, 기준 이미지와 시각적으로 유사한 결과를 생성하는 것을 볼 수 있어요. 텍스처가 있는 영역의 오류는 주로 Mitsuba와 우리 RRF 렌더링에서 사용된 다른 텍스처 필터 때문이고, 객체 경계의 오류는 우리 RRF 렌더링에서 각 픽셀에 단일 샘플 광선을 사용했기 때문이에요.
우리의 훈련 방법이 다양한 훈련 세트에 대해 얼마나 강건한지를 테스트하기 위해, 전체 훈련 세트에서 무작위로 선택한 70%의 샘플로 RRFs를 훈련시켰어요. 그리고 이 RRFs를 사용해 앞서 언급한 400개의 이미지를 렌더링했답니다. 이 과정을 서로 다른 훈련 샘플 세트로 총 10번 반복했어요. 그리고 각 렌더링 결과를 실제 값과 비교했죠. 그 결과, 10개의 신경망에서 평균 렌더링 오류는 원래 RRF 피팅과 거의 동일했고, 오류의 표준 편차는 매우 작았어요. 세 장면에 대한 오류의 표준 편차는 표 3의 두 번째 열에 보고되어 있어요. 또한, 초기 가중치 값이 다른 경우에 대해서도 훈련 방법의 강건성을 비슷한 방식으로 조사했어요. 각 실험에서는 동일한 훈련 데이터를 사용하지만, 초기 가중치 값은 [-1.0,1.0] 범위 내에서 다르게 설정했어요.
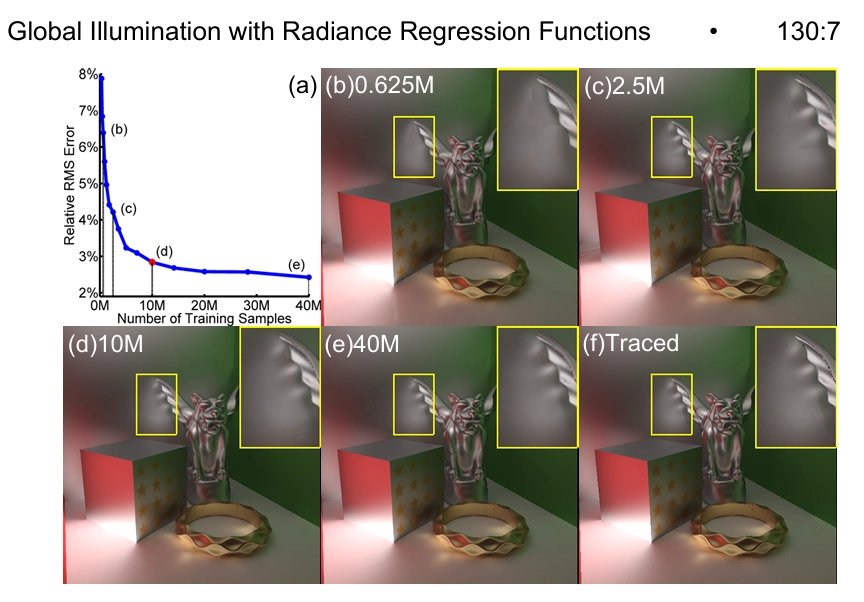
그림 6: 다양한 크기의 훈련 세트로 생성된 RRFs의 정확도. (a) 다른 크기의 훈련 데이터로 계산된 RRFs의 렌더링 오류. (b)-(e) 서로 다른 RRFs의 렌더링 결과. (f) 실제 이미지.
[-1.0,1.0]. 세 장면에 대한 10세트의 RRF 렌더링 결과에 대한 렌더링 오류의 표준 편차는 표 3의 세 번째 열에 나와 있어요. 이러한 실험들은 초기 가중치 값의 선택과 훈련 데이터의 선택에 대해 우리 훈련 방법이 안정적이고 강건하다는 것을 보여줘요. 주어진 입력 벡터에 대한 서로 다른 렌더링 결과도 시각적으로 비슷하게 보인답니다.
RRFs의 정확도는 주로 학습 세트의 크기와 정확도에 의해 결정돼요. Figure 6(a)에서는 Cornell Box 장면에 대해 다양한 양의 학습 데이터를 사용해 계산한 RRFs의 렌더링 오류를 보여줘요. Figure 6(b)-(f)에서는 RRFs의 렌더링 결과와 경로 추적에 의해 생성된 실제 이미지(Ground Truth)를 보여주고 있답니다. 비교적 적은 데이터로 학습된 RRFs도 표면의 저주파 음영 변화를 잘 재구성할 수 있지만, 풍부한 음영 세부 사항은 손실돼요. 학습 데이터의 양이 증가함에 따라 RRFs의 정확도는 빠르게 향상되고, 학습 샘플 수가 10M에 도달하면 안정화돼요. 그 이후로는 학습 데이터의 크기가 증가해도 RRFs의 정확도와 렌더링 품질은 천천히 향상돼요. Figure 7(a)에서는 Cornell Box 장면에 대해 다양한 정확도로 생성된 학습 세트에서 계산된 RRFs의 렌더링 오류를 보여줘요. 이 실험에서는 학습 샘플 수가 10M이고, 각 학습 세트는 서로 다른 수의 광선을 사용한 경로 추적으로 생성됐어요. Figure 7(b)-(f)에서는 RRFs의 렌더링 결과와 16384개의 광선으로 렌더링된 실제 이미지를 보여줘요. 학습 세트 생성에 사용된 광선 수를 4096에서 256으로 줄이면, 샘플링 데이터의 노이즈가 커져서 RRF 렌더링 오류가 커지고, 부드러운 음영 영역에서 블로킹 아티팩트가 발생해요. 반면, 광선 수가 4096에서 16384로 증가해도 RRFs의 정확도는 안정적이에요. 이는 경로 추적에서 4096개의 광선을 사용하는 것 이상으로 학습 샘플의 정확도가 크게 향상되지 않기 때문이에요. 이를 바탕으로, 논문의 나머지 부분에서는 RRF 학습 데이터를 생성하기 위해 4096개의 광선을 사용해요.
그림 9(a-b)는 Cornell Box 장면의 렌더링 결과를 보여줘요. 이 장면에서는 좌우 벽, 천장, 바닥이 diffuse surfaces이고, 나머지 객체들은 glossy해요. 측면 벽과 천장 사이의 color bleeding이 잘 재현되었고, 반지와 조각상에 의해 생기는 caustics도 설득력 있게 생성되었답니다. 그림 9(c-d)는 Plant 장면의 렌더링 결과를 보여줘요. 책상과 식물 잎에서의 다중 반사 interreflections가 실제와 매우 가깝게 일치해요.
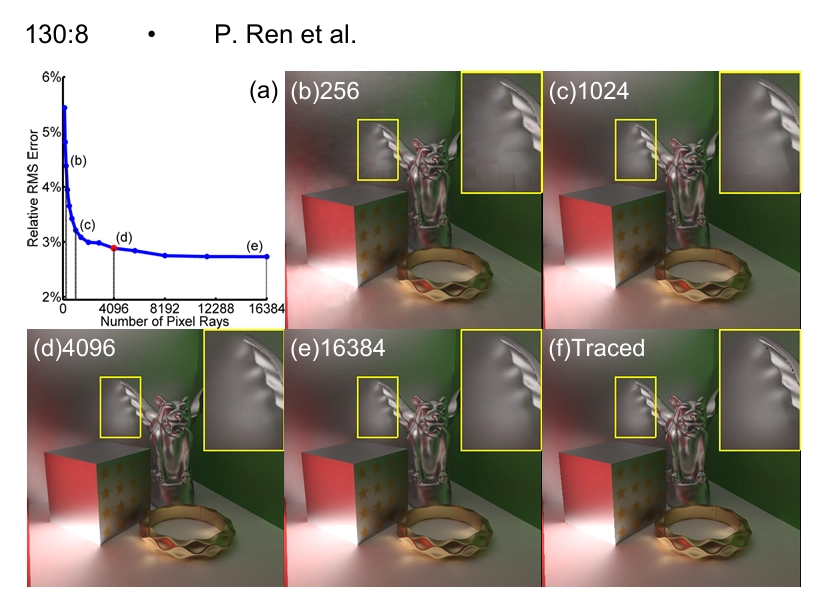
그림 7: 다양한 광선 수로 렌더링된 학습 세트로부터 생성된 RRFs의 정확도입니다. (a) 학습 데이터 생성에 사용된 광선 수에 따른 RRFs의 렌더링 오류를 보여줘요. (b)-(e) 서로 다른 RRFs의 렌더링 결과입니다. (f) 실제 이미지입니다.
그림 10에서는 Kitchen 장면의 렌더링 결과가 보여져요. 여기서는 glossy surfaces 사이의 다중 반사 interreflections가 강한 간접 조명 효과를 만들어내요. 다양한 시점에서, 과일과 병이 뒷벽과 책상에 반사되는 모습이 잘 재현되었답니다. 비교를 위해, 그림 10(d)에서는 직접 조명만으로 렌더링된 장면도 보여줘요.
그림 11은 Sponza 장면의 렌더링을 보여줘요. 다중 반사 interreflections로 인한 음영 변화가 정확하게 생성되었어요. (a)에서는 회랑 아케이드 지붕에서 세 번 이상의 반사를 포함한 interreflections가, (c)에서는 간접 조명에 의해 생기는 그림자가 보여져요.
그림 12에서는 Bedroom 장면이 렌더링되어 있어요. 이 장면은 복잡한 간접 조명 효과를 보여주는데, 오프라인 global illumination 알고리즘조차도 모든 복잡한 조명 효과를 렌더링하는 것은 어려운 일이에요. 우리 방법은 단 109.09 MB의 RRF 데이터만으로 모든 조명 효과를 실시간으로 재현해요. diffuse surfaces에서의 부드러운 간접 조명과 glossy 객체에서의 세밀한 반사가 모두 잘 렌더링되었답니다.
첨부된 비디오에서는 동적인 시점과 조명을 가진 모든 장면의 실시간 렌더링 결과를 보여줘요. 이 비디오에는 색상이 변하는 여러 동적 지역 조명과 함께 실시간 렌더링도 포함되어 있고, 아래에서 논의할 실시간 재질 편집 예시도 들어 있어요.
재질 편집 RRF는 실시간 재질 편집을 위한 유연한 기술을 제공해요. 특히 RRF가 변화하는 caustics(그림 8 a-b)와 고주파수의 광택 있는 상호반사(그림 8 c-d) 같은 고급 시각 효과를 포착할 수 있는 능력 덕분에 큰 이점을 얻어요. 더 자세한 내용은 부록 B를 참조하세요.
6 Discussion
우리의 접근 방식도 실시간으로 전역 조명 효과를 렌더링하기 위해 사전 계산을 기반으로 하지만, 개념적으로 PRT 방법과는 다르고 매우 다른 특성을 가지고 있어요. 모든 PRT 방법은 각 표면 지점의 전역 조명을 입사 및 방사 복사의 선형 함수로 모델링해요. 6D 간접 전역 조명(표면 위치, 시야 방향, 먼 조명 방향에 대한)을 처리하기 위해, 이러한 방법들은 2D 객체 표면을 밀집 샘플링하고 각 표면 지점의 4D 광 전송을 선형 또는 비선형 기저로 인코딩해요. 이 별도의 표현은 비선형 공동체의 이점을 활용해요.

그림 8: 실시간 재질 편집으로의 RRF 확장. (a)(b) 동상의 반사 색상과 반지의 광택을 변경. (c)(d) 과일의 확산 색상과 뒷벽의 광택을 편집.
6D 간접 전역 조명에서의 일관성을 제한적으로만 활용할 수 있어요. 특히, 표면에서 고주파 조명 효과를 모델링하려면 장면을 촘촘하게 테셀레이션해야 하거든요. 데이터 크기는 CPCA나 클러스터링된 텐서 근사 같은 다양한 데이터 압축 기법으로 줄일 수 있지만, 이런 조각별 선형 또는 다중 선형 압축 기법은 데이터의 비선형 일관성을 완전히 활용하지 못하게 해요. 고주파 조명 효과, 예를 들어 caustics, 날카로운 간접 그림자, 고주파 광택 상호반사 등을 렌더링하려면 많은 양의 데이터와 계산이 필요해요. 우리가 아는 한, 기존의 PRT 방법 중에서는 이러한 모든 효과를 로컬 광원에 대해 실시간으로 렌더링할 수 있는 방법이 없답니다.
반면에, 우리 방법은 6차원 간접 전역 조명을 직접적으로 근사화하고, 여섯 차원 모두에서 비선형적인 일관성을 동시에 효과적으로 활용할 수 있어요. 게다가, 미리 계산된 신경망은 분석적인 형태를 가지고 있어서 고주파 조명 효과를 포착하기 위해 조밀한 표면 메시가 필요하지 않답니다. 예를 들어, Cornell Box 장면에서는 여러 광택 있는 물체의 복잡한 반사와 굴절을 보여주는데, 우리 방법은 이 장면을 60 FPS로 렌더링하기 위해 5.6 MB의 데이터만 필요해요. 비교하자면, Green et al. [2006]은 구형 가우시안 혼합으로 입사 조명을 모델링했는데, 단일 균일 광택 물체를 렌더링하는 데 약 25 MB의 데이터가 필요하답니다. Kristensen et al.의 접근법 [2005]을 사용하면, 단일 광택 토끼 모델을 미리 계산하고 압축된 데이터로 17 MB로 렌더링할 수 있어요. Kontkanen et al. [2006]이 제시한 직접-간접 전환 방법은 각 표면 지점에서 직접 조명에서 간접 조명으로의 4차원 전송 행렬을 샘플링하고, 웨이블릿 기저를 사용해 전송 행렬을 인코딩합니다. 두 개의 광택 물체가 있는 작은 장면의 저해상도 간접 조명을 렌더링하는 데 23 MB의 데이터가 필요해요. 압축 방식의 복잡성(4차원 웨이블릿 기저) 때문에 렌더링 프레임 속도는 낮아서 약 10 FPS 정도랍니다.
우리 방법의 성능은 메쉬 테셀레이션의 밀도(즉, 정점의 수)와는 무관하지만, 장면의 크기와 기하학적 구성에 영향을 받아요. 장면의 크기가 커질수록, 장면의 다른 영역 간의 간접 조명의 일관성이 그에 따라 감소하게 되거든요.
이로 인해 더 많은 파티션과 RRFs가 렌더링에 필요하게 돼요. Sponza 장면의 경우, 우리 방법은 장면 전체의 조명 효과를 렌더링하기 위해 24.81MB의 데이터를 사용해요. 장면 내 간접 그림자 효과도 효과적으로 렌더링되죠. 참고로, Kristensen 등은 같은 장면에서 확산 상호반사를 모델링하기 위해 약 17MB의 데이터를 사용했어요. 음영 효과가 희소한 메쉬의 꼭짓점에서 샘플링되기 때문에, 꼭짓점 사이의 세부적인 간접 그림자 효과는 손실돼요. Lehtinen 등의 메쉬 없는 접근법은 이 장면에서 우리 방법과 유사한 렌더링 품질을 얻기 위해 77.4MB의 데이터가 필요해요. 복잡한 기하학적 구성으로 인해 날카로운 간접 그림자 효과가 있는 장면들(예: Bedroom 장면과 Plant 장면)에서는 우리 방법도 더 많은 RRFs가 필요해요. 이러한 장면들은 이전의 PRT 방법들에도 도전적인 과제랍니다.
이번 연구에서는 점광원으로 구성된 조명 환경을 고려했지만, RRFs는 다른 유형의 광원과도 함께 사용할 수 있어요. 예를 들어, 방향성 조명은 d 형태의 RRFs를 훈련시켜 처리할 수 있는데, 여기서 d는 빛의 방향이에요. 하지만 환경 조명은 주의해서 다뤄야 해요. 환경 맵의 모든 픽셀을 무제한으로 변경할 수 있게 하면 입력 벡터의 자유도가 폭발적으로 증가해서 RRFs의 훈련이 비현실적이 될 수 있거든요. 만약 환경 조명의 회전만 필요하다면, r이 환경 조명의 회전 벡터인 형태의 RRFs를 훈련시켜서 이를 달성할 수 있어요. 환경 조명의 더 일반적인 변화에 대해서는, PRT에서처럼 조명을 구면 조화 기저에 투영하고 기저 확장의 처음 몇 개 항을 RRF 입력으로 선택해서 저주파 조명을 조정할 수 있어요. 그런 다음 선택된 각 기저 함수에 대해 하나의 RRF를 훈련시킬 수 있고, 이렇게 훈련된 RRFs는 식 (9)처럼 결합할 수 있답니다.
RRF의 입력 변수 Xₚ와 V를 매개변수화하는 다른 방법들도 있어요. 만약 장면에 참여 매체가 없다면, 우리는 표면 위의 점 Xₚ에만 관심을 가지게 되는데, 이는 두 변수 uₚ, vₚ로 매개변수화할 수 있답니다. 이렇게 하면 자유도를 줄일 수 있어서 RRF 훈련이 더 쉬워져요. 이번 연구에서는 3D 점 Xₚ를 직접 사용하는 방법을 선택했어요. 왜냐하면 그래픽 객체들이 다양한 형식으로 제공되는 경우가 많아서 매개변수화가 항상 쉽지 않거든요. 또한, 참여 매체가 있는 장면에도 적합한 일반적인 형태로 RRF를 유지하고 싶었어요. 이와 같은 고려는 시점 벡터 V에도 적용됩니다.
현재 시스템은 전처리에 시간이 많이 걸려요. 우리는 이 긴 전처리 단계를 최적화하려고 노력하지 않았어요. 왜냐하면 전역 조명 효과를 희생하지 않고 실시간 렌더링을 달성하는 데 집중했기 때문이죠. 앞으로 전처리 시간을 줄이기 위한 많은 작업이 가능할 거예요. 전처리는 두 부분으로 나뉘어요: 훈련 데이터 샘플링과 신경망 훈련이죠. 샘플링의 긴 계산 시간은 현재 구현에서 사용된 무차별 경로 추적 알고리즘 때문이에요. 이 시간을 더 빠른 전역 조명 알고리즘(예: photon mapping)을 사용하면 크게 줄일 수 있답니다. 신경망 훈련 코드는 최적화되지 않았고, 논문에 있는 각 예제의 신경망을 생성하는 데 1~10시간이 걸려요. 이 작업은 GPU에서 10배~30배 가속할 수 있어요.
RRF의 주요 제한점은 입력 벡터의 차원이 너무 높아서는 안 된다는 점이에요. 입력 벡터에 독립 변수들이 많아지면, 신경망을 훈련시키는 데 걸리는 시간과 필요한 데이터 양 때문에 훈련이 비현실적이 되거든요. 우리 연구에서는 동적인 시점과 지역 조명을 잘 처리할 수 있음을 보여줬어요. 하지만 애니메이션 객체 같은 추가적인 동적 요소를 장면에 도입할 때는 주의가 필요해요. 동적 요소는 장면의 자유도를 관리 가능한 수준으로 유지할 수 있도록 추가해야 해요.
RRF의 또 다른 제한점은 샘플링된 시점 방향과 조명 위치 근처의 간접 조명만 잘 근사한다는 점이에요.
다시 말해, RRF는 샘플 간의 보간에는 잘 작동하지만, 이웃 샘플에서의 외삽에는 잘 작동하지 않아요.
7 Conclusion
우리는 방사율 회귀 함수를 동적 시점과 조명 조건에 대한 간접 조명의 비선형 모델로 설명했어요. 실험 결과, 고주파의 반짝이는 상호 반사 같은 까다로운 시각 효과를 포함한 설득력 있는 렌더링이 비교적 간결한 RRF 모델로 가능하다는 것을 보여줬어요. 이는 간접 조명 데이터에 상당한 비선형 일관성이 존재한다는 것을 의미해요. 이 일관성은 사전 계산된 전역 조명을 기반으로 한 실시간 렌더링 방법에 의해 효과적으로 활용될 수 있답니다. 우리 RRF 표현은 런타임에서 각 3D 객체의 RRF 평가가 장면의 다른 객체와 관련이 없다는 점에서 런타임 로컬이에요. 따라서 많은 객체가 있는 큰 장면에서도 모든 객체가 화면 공간에서 병렬로 렌더링되기 때문에 렌더링은 실시간으로 유지될 수 있어요.
앞으로의 연구 방향으로 몇 가지를 계획하고 있어요. 현재는 불투명한 물체만 다루고 있고, 참여 매체가 없다고 가정하고 있거든요. 앞으로는 반투명한 물체와 참여 매체를 다루는 방향도 포함될 수 있어요. 또한, 학습 시간을 줄이는 방법에도 관심이 있어요. 마지막으로, 동적 장면을 효율적으로 처리하는 방법을 조사할 계획이에요. 이 논문에서 다룬 몇 가지 자유도에서 덜 제한된 장면 구성의 많은 자유도로 확장하는 것은 큰 도전이지만, 물체/영역의 속성 집합을 조정하여 그 음영에 눈에 띄는 영향을 줄 수 있는 애니메이션 물체만 고려함으로써 이 문제를 단순화할 수 있을지도 몰라요.
Acknowledgements
저자들은 비선형 회귀 기법과 신경망 학습에 대한 유익한 토론을 해주신 Zhuowen Tu와 Frank Seide에게 감사드려요. 또한, 익명의 리뷰어들에게도 유익한 제안과 의견을 주셔서 감사드려요. 그림 10의 장면은 Tomas Davidovic가 제공했고, 그림 12의 장면은 David Vacek가 기하학적으로 모델링하고 Shuitan Yan이 디자인했어요.
References
BEALE, M. H., HAGAN, M. T., AND DEMUTH, H. B. 2012. Neural Network Toolbox user's guide.
BLUM, E., AND LI, L. 1991. Approximation theory and feedforward networks. Neural Networks 4, 4, 511-515.
CHESTER, D. 1990. Why two hidden layers are better than one. In Int. Joint Conf. on Neural Networks (IJCNN), 265-268.
COHEN, M. F., WALLACE, J., AND HANRAHAN, P. 1993. Radiosity and realistic image synthesis. Academic Press Professional, Inc., San Diego, CA, USA.
CRASSIN, C., NEYRET, F., SAINZ, M., GREEN, S., 그리고 EISEMANN, E. 2011. Voxel cone tracing을 이용한 인터랙티브 간접 조명. Computer Graphics Forum 30, 7.
DACHSBACHER, C., AND STAMMINGER, M. 2006. Splatting indirect illumination. In I3D, 93-100.
DACHSBACHER, C., STAMMINGER, M., DRETTAKIS, G., 그리고 DURAND, F. 2007. 인터랙티브 글로벌 일루미네이션을 위한 암시적 가시성과 반방사. ACM Trans. Graph. 26.
DACHSBACHER, C. 2011. 가시성 구성 분석. IEEE Trans. Vis. Comput. Graph. 17, 4, 475-486.

그림 9: RRFs를 사용한 렌더링 결과. (a)(b) Cornell Box 장면. (c)(d) 식물 장면.
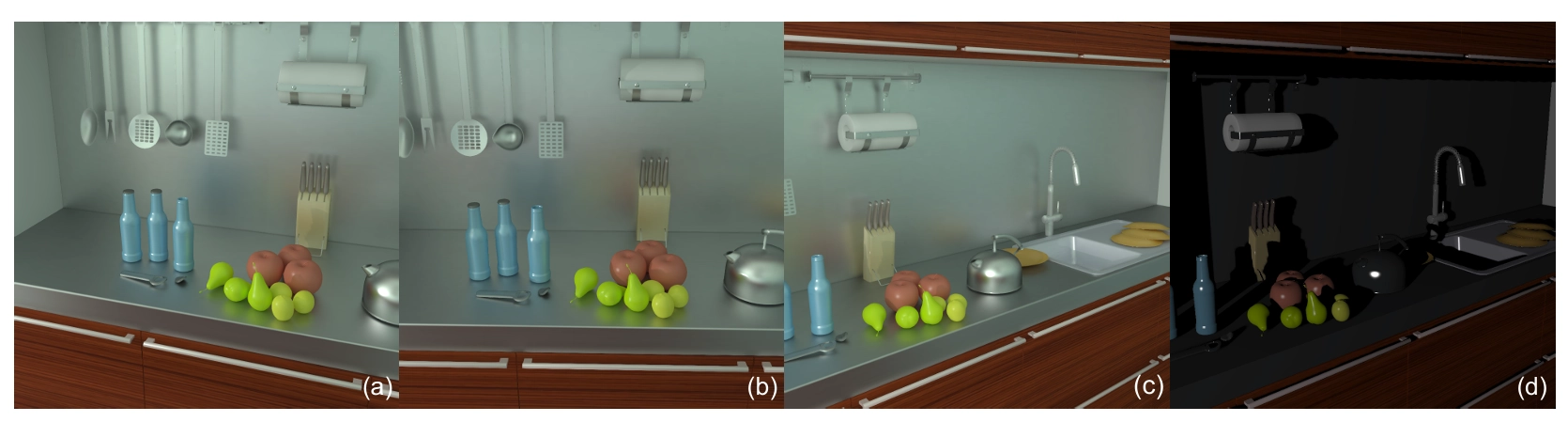
그림 10: 강한 광택 상호반사가 있는 주방 장면. (c)(d) 글로벌 일루미네이션과 직접 조명 결과 비교.

그림 11: 복잡한 기하학을 가진 Sponza 장면이에요. (a) 회랑 아케이드의 지붕에 도달하려면 세 번 이상의 빛 반사가 필요해요. (c)(d) 전역 조명과 직접 조명 결과를 비교했어요.

그림 12: 복잡한 기하학과 다양한 재질을 가진 침실 장면이에요. (c) (b)에서 강조된 간접 그림자의 확대된 모습이에요. (d) 경로 추적을 통해 렌더링된 간접 그림자의 실제 모습이에요.
Appendix A: Neural Network Details
이 연구에서 사용된 신경망은 두 개의 은닉층을 가지고 있어요. 이 은닉층의 노드 수를 결정하기 위해, 그림 3에 있는 장면에 대해 다양한 노드 배열을 실험해 봤어요. 그림 13에서 보듯이, 각 층의 노드 수가 증가하면 적합 오차가 줄어들어요. 하지만, 가중치의 수도 증가해서 신경망 훈련과 평가에 더 많은 계산이 필요하게 돼요. 현재 구현에서는 첫 번째 은닉층에 20개의 노드, 두 번째 은닉층에 10개의 노드를 사용하고 있어요. 이게 근사 능력과 계산 효율성 사이의 좋은 균형을 제공하거든요.
신경망을 훈련시키려면 먼저 훈련 데이터를 얻어야 해요. 사전에 정의된 광원 위치와 시점 범위를 가진 장면이 주어지면, Latin hypercube 샘플링 기법 [McKay et al. 2000]을 사용해 훈련 세트를 생성하고, path tracing [Lafortune and Willems 1993]을 통해 모든 예제의 간접 조명 값을 계산해요. 구체적으로는, 광원 범위를 Nₗ 개의 층으로 균등하게 나누고 각 층에서 무작위로 광원 위치를 샘플링해요. 그런 다음, 비슷한 방식으로 Nᵥ 개의 시점 위치를 샘플링해요. 광원 위치 I와 시점의 각 조합에 대해, 시점에서 Nᵣ 개의 광선을 무작위로 쏘고, 각 광선 V를 장면의 첫 번째 교차점 X까지 추적해요. 그런 다음, 표면 점 위치 Xp를 기록하고 path tracing을 통해 간접 조명 값을 계산해요. 이 과정을 통해 Nₗ Nᵥ Nᵣ 개의 예제를 생성하여 훈련 세트를 구성해요. 샘플의 총 개수는 신경망 가중치의 약 10배로 설정해요 [Grzeszczuk et al. 1998]. Nᵥ, Nₗ, Nᵣ의 값은 장면의 복잡성에 따라 사용자가 선택해요. 그림 5(b)에 표시된 장면의 경우, Nᵥ = 200, Nₗ = 200, Nᵣ = 6000으로 설정했어요. 표면의 점을 직접 샘플링하는 대신, 우리 방법은 시야 광선의 표면 교차점을 샘플링해서 가시성 테스트를 피하고, 가시 표면이 잘 샘플링되도록 해요. 일부 광선이 장면의 점과 교차하지 않을 수 있기 때문에, 목표한 예제 수를 생성하려면 Nᵣ 값을 늘려야 할 수도 있어요. 다른 샘플링 기법도 훈련 세트 생성에 사용할 수 있답니다.
신경망 Ф№의 구조와 학습 세트를 결정한 후, 이제 Φₙ(xₚ,v,l,n,a,w)를 학습시켜서 W의 모든 가중치를 구해요. 이 과정은 [Hagan and Menhaj 1994]에서 설명한 Levenberg-Marquardt (LM) 알고리즘을 적용해서 식 6의 E(w)를 최소화하는 방식으로 진행돼요. 우리 시스템에서 사용하는 소규모 신경망의 경우, LM 알고리즘이 다른 gradient 기반 방법이나 공액 방법보다 성능이 더 좋답니다 [Hagan and Menhaj 1994]. [Beale et al. 2012]의 구현을 따라, 먼저 입력과 출력 벡터 각각의 요소 범위를 계산하고, 모든 요소를 [-1.0, 1.0] 범위로 스케일링해서 학습 시 동일하게 취급되도록 해요. 각 속성의 스케일링 계수는 실행 시 계산을 위해 저장해 둡니다. 가중치 벡터 W는 1.0 범위 내에서 무작위 값으로 초기화한 후, 반복적으로 W를 업데이트해요.
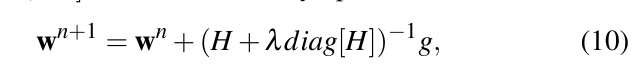
여기서 wⁿ⁺¹과 wn은 현재와 이전 반복의 가중치 벡터를 의미해요. H는 E(w)에 대한 W의 헤시안 행렬로, E(w)의 야코비안 행렬 J로부터 효율적으로 계산할 수 있어요. 2는 스텝 길이를 제어하는 상수로, 알고리즘에 의해 자동으로 결정돼요. g는 현재 오차 함수 E(wⁿ)에 대한 가중치의 그래디언트를 나타내며, g = E(wⁿ)로 계산됩니다. 각 반복에서는 표준 역전파 방식 [Hinton 1989]을 사용해 E(wⁿ)의 야코비안 행렬을 계산해요. 이 과정을 사용자가 정의한 임계값(우리 구현에서는 0.05) 이하로 E(w)가 떨어질 때까지 반복합니다.
우리 작업에서는 배치 학습과 온라인 학습 [Hastie et al. 2009]을 모두 시도해 봤어요. 배치 학습에서는 모든 학습 데이터를 사용해 E(w)를 최소화하고, 온라인 학습에서는 학습 데이터를 하위 그룹으로 나누어 가중치 벡터를 점진적으로 업데이트하면서
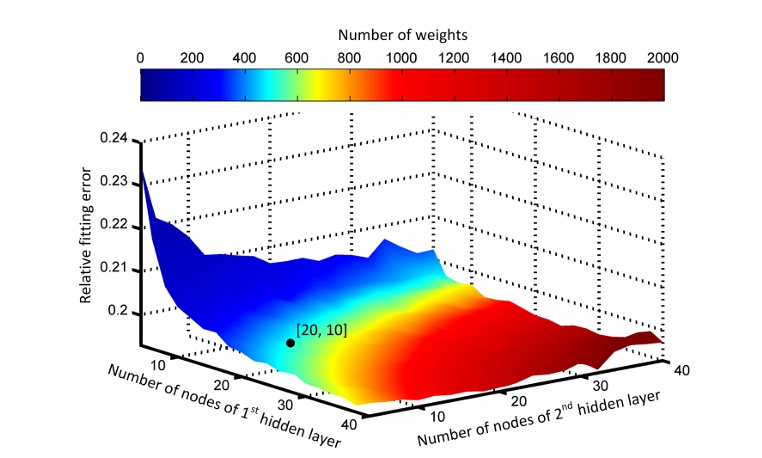
그림 13: 숨겨진 레이어 노드 수와 피팅 오류의 관계.
E(w)를 최소화해요. 우리 응용 프로그램에서는 배치 학습이 항상 온라인 학습보다 성능이 뛰어나다는 것을 발견했고, 그래서 구현에서는 배치 학습을 사용하고 있어요.
과적합은 회귀 분석에서 중요한 문제로, 많이 연구되었어요. 자유 매개변수가 너무 많은 신경망은 데이터를 과적합하게 되거든요. 이를 피하기 위해 충분한 훈련 데이터를 확보하는데요, [Grzeszczuk et al. 1998]에 따르면 신경망 가중치의 8~10배 정도의 데이터가 필요해요. 또 다른 중요한 기법은 교차 검증이에요. 훈련 데이터의 70%를 신경망 훈련에 사용하고, 나머지 30%는 훈련 결과를 검증하는 데 사용하죠 [Beale et al. 2012]. 마지막으로, 가중치 감소라는 기법도 있어요. 이건 일종의 정규화 방법인데요 [Hastie et al. 2009]. 우리 시스템에 이 기법을 구현했지만, 추가적인 개선은 거의 없었어요. 6장에서 우리 회귀 시스템이 다양한 훈련 세트와 초기 가중치 값에 대해 견고하다고 보고했어요. 이는 우리 시스템에서 과적합이 잘 제어되고 있다는 또 다른 신호랍니다.
Appendix B: Material Editing
RRF는 장면 내 선택된 객체의 재질 속성을 편집할 수 있는 유연한 기술을 제공해요. 그리고 전체 글로벌 조명 효과와 함께 실시간으로 편집 결과를 시각화할 수 있답니다. 기존 방법으로는 잡기 어려운 시각적 효과들, 예를 들어 변하는 caustics나 여러 번 반사되는 고주파수의 광택 상호반사 같은 것들이 RRF를 통해 잘 재현될 수 있어요. 편집 작업의 성격에 따라 조명이나 시점을 고정하고, 선택된 객체의 BRDF 매개변수로 해당 RRF 입력 변수를 대체할 수 있답니다. 그림 8(a-b)는 Cornell Box 장면에서 반지의 스펙큘러 거칠기와 가고일의 스펙큘러 색상을 편집한 모습을 보여줘요. 이 예시에서는 반지로 인해 생성된 caustics가 스펙큘러 거칠기와 조명의 변화에 따라 어떻게 변하는지에 특히 관심이 있어요. 그래서 시점을 고정하고, RRF의 시점 방향 변수를 반지의 스펙큘러 거칠기와 가고일의 스펙큘러 색상을 나타내는 새로운 변수로 대체했어요. 새로운 입력 벡터를 기반으로 훈련 세트를 생성하고, 새로운 훈련 데이터를 바탕으로 회귀를 통해 RRF를 얻습니다. 결과적으로, 이러한 재질 속성들이 이제 RRF의 입력 변수가 되었기 때문에 실시간 편집을 지원할 수 있어요. 이는 동영상에서 시연되고 있답니다. 그림 8(c-d)는 주방 장면에서 과일 색상과 뒷벽의 스펙큘러 거칠기를 편집한 모습을 보여줘요. 이 예시에서는 여러 번 반사되는 고주파수의 광택 상호반사가 다른 시점에서 뒷벽에 어떻게 보이는지에 초점을 맞추고 있어요. 다시 말해, 조명 위치를 고정하고 시점 방향을 RRF의 입력 변수로 남겨두면서, 훈련 데이터 생성과 RRF 회귀 수행 시 과일의 색상과 뒷벽의 스펙큘러 거칠기를 RRF 입력 변수로 사용하여 재질 편집을 지원할 수 있답니다. 대부분의 기존 방법들은 여러 번 반사되는 상호반사가 저주파수라고 가정하기 때문에, 여러 번 반사되는 고주파수의 광택 상호반사를 포착하기가 매우 어렵다는 점을 유의하세요.
Reference
DONG, Z., KAUTZ, J., THEOBALT, C., 그리고 SEIDEL, H.-P. 2007. 암시적 가시성을 이용한 상호작용 전역 조명. Pacific Conference on Computer Graphics and Applications, 77-86.
DONIKIAN, M., WALTER, B., BALA, K., FERNANDEZ, S., 그리고 GREENBERG, D. P. 2006. 반복적인 적응 샘플링을 이용한 정확한 직접 조명. IEEE TVCG 12 (5월), 353-364.
DONNELLY, W., AND LAURITZEN, A. 2006. Variance shadow maps. In I3D, 161-165.
FAQ. 숨겨진 레이어는 몇 개를 사용해야 하나요? Neural Network FAQ, Usenet 뉴스그룹 comp.ai.neural-nets, ftp:// ftp.sas.com/pub/neural/FAQ3.html#A_hl.
GREEN, P., KAUTZ, J., MATUSIK, W., 그리고 DURAND, F. 2006. 비선형 가우시안 함수 근사를 사용한 뷰 종속 사전 계산된 광 전송. I3D에서, 7-14.
GRZESZCZUK, R., TERZOPOULOS, D., 그리고 HINTON, G. 1998. Neuroanimator: 물리 기반 모델의 빠른 신경망 에뮬레이션 및 제어. Proc. SIGGRAPH '98에서, 9-20.
HAGAN, M., 그리고 MENHAJ, M. 1994. 마쿼르트 알고리즘을 사용한 피드포워드 네트워크 훈련. Neural Networks, IEEE Transactions on 5, 6, 989-993.
HASTIE, T., TIBSHIRANI, R., 그리고 FRIEDMAN, J. 2009. 통계적 학습의 요소: 데이터 마이닝, 추론, 예측, 2판. Springer.
HAŠAN, M., PELLACINI, F., 그리고 BALA, K. 2006. 영화 조명을 위한 직접-간접 전환. ACM Trans. Graph. 25, 1089-1097.
HERTZMANN, A. 2003. 컴퓨터 그래픽스를 위한 머신러닝: 선언문과 튜토리얼. Pacific Conference on Computer Graphics and Applications, 22-36.
HINTON, G. E. 1989. Connectionist learning procedures. Artificial Intelligence 40, 1-3, 185-234.
HORNIK, K., STINCHCOMBE, M., 그리고 WHITE, H. 1989. 다층 피드포워드 네트워크는 보편적 근사자입니다. Neural Networks 2, 5 (7월), 359-366.
JAKOB, W., 2010. Mitsuba 렌더러. Cornell University 컴퓨터 과학부. (http://www.mitsuba-renderer.org).
KAPLANYAN, A., 그리고 DACHSBACHER, C. 2010. 실시간 간접 조명을 위한 계단식 빛 전파 볼륨. I3D, 99-107.
KELLER, A. 1997. Instant radiosity. In SIGGRAPH '97, 49-56.
KONTKANEN, J., TURQUIN, E., HOLZSCHUCH, N., 그리고 SILLION, F. X. 2006. 상호작용적인 간접 조명을 위한 웨이브릿 복사 전송. Rendering Techniques '06, 161-171에서.
KRISTENSEN, A. W., AKENINE-MÖLLER, T., 그리고 JENSEN, H. W. 2005. 실시간 조명 설계를 위한 사전 계산된 지역 복사 전송. ACM Trans. Graph. 24, 1208-1215.
LAFORTUNE, E. P., 그리고 WILLEMS, Y. D. 1993. 양방향 경로 추적. Proc. Compugraphics '93, 145-153에서.
LEHTINEN, J., ZWICKER, M., TURQUIN, E., KONTKANEN, J., DURAND, F., SILLION, F. X., 그리고 AILA, T. 2008. 빛 전송을 위한 메쉬 없는 계층적 표현. ACM Trans. Graph. 27, 37:1-37:9.
LIU, X., SLOAN, P.-P., SHUM, H.-Y., 그리고 SNYDER, J. 2004. 광택 있는 물체를 위한 모든 주파수 사전 계산된 복사 전송. Rendering Techniques '04, 337-344에서.
MCGUIRE, M., AND LUEBKE, D. 2009. 이미지 공간 포톤 매핑을 통한 하드웨어 가속 전역 조명. High Performance Graphics에서 발표.
MCKAY, M. D., BECKMAN, R. J., AND CONOVER, W. J. 2000. 컴퓨터 코드의 출력 분석에서 입력 변수 값을 선택하는 세 가지 방법 비교. Technometrics 42, 1 (2월), 55-61.
MEYER, M., AND ANDERSON, J. 2007. 키 포인트 서브스페이스 가속 및 소프트 캐싱. ACM Trans. Graph. 26, 3.
NG, R., RAMAMOORTHI, R., AND HANRAHAN, P. 2004. 모든 주파수 재조명을 위한 삼중곱 웨이블릿 적분. ACM Trans. Graph. 23, 477-487.
NICHOLS, G., AND WYMAN, C. 2010. 적응형 다중 해상도 스플래팅을 사용한 인터랙티브 간접 조명. IEEE TVCG 16, 5, 729-741.
NOWROUZEZAHRAI, D., KALOGERAKIS, E., 그리고 FIUME, E. 2009. 임의의 BRDFs를 가진 동적 장면의 그림자 처리. Comput. Graph. Forum: Eurographics Conf. 28, 249-258.
PARKER, S. G., BIGLER, J., DIETRICH, A., FRIEDRICH, H., HOBEROCK, J., LUEBKE, D., MCALLISTER, D., MCGUIRE, M., MORLEY, K., ROBISON, A., 그리고 STICH, M. 2010. Optix: 범용 레이 트레이싱 엔진. ACM Trans. Graph. 29.
RAMAMOORTHI, R. 2009. 사전 계산 기반 렌더링. Found. Trends. Comput. Graph. Vis. 3 (4월), 281-369.
RITSCHEL, T., GROSCH, T., KIM, M. H., SEIDEL, H.-P., DACHSBACHER, C., 그리고 KAUTZ, J. 2008. 간접 조명의 효율적인 계산을 위한 불완전한 그림자 맵. ACM Trans. Graph. 27, 129:1-129:8.
RITSCHEL, T., DACHSBACHER, C., GROSCH, T., 그리고 KAUTZ, J. 2012. 상호작용적 글로벌 일루미네이션의 최신 기술. Computer Graphics Forum 31, 1, 160-188.
SLOAN, P.-P., KAUTZ, J., AND SNYDER, J. 2002. 동적이고 저주파 조명 환경에서 실시간 렌더링을 위한 사전 계산된 복사 전달. ACM Trans. Graph. 21.
SLOAN, P.-P., HALL, J., HART, J., AND SNYDER, J. 2003. 사전 계산된 복사 전달을 위한 클러스터링된 주성분. ACM Trans. Graph. 22, 3 (7월), 382-391.
THIEDEMANN, S., HENRICH, N., GROSCH, T., AND MÜLLER, S. 2011. 복셀 기반 전역 조명. In I3D, 103-110.
TSAI, Y.-T., AND SHIH, Z.-C. 2006. 구형 방사 기저 함수와 클러스터링된 텐서 근사를 사용한 모든 주파수 사전 계산 복사 전달. ACM Trans. Graph. 25, 3, 967-976.
WALD, I., MARK, W. R., GUENTHER, J., BOULOS, S., IZE, T., HUNT, W., PARKER, S. G., AND SHIRLEY, P. 2009. 애니메이션 장면의 레이 트레이싱 최신 기술. Computer Graphics Forum 28, 6, 1691-1722.
WANG, R., TRAN, J., 그리고 LUEBKE, D. 2006. 광택 있는 물체의 모든 주파수 재조명. ACM Trans. Graph. 25, 2, 293-318.
WANG, R., ZHU, J., 그리고 HUMPHREYS, G. 2007. 스펙트럴 메쉬 기반을 사용한 실시간 간접 조명을 위한 사전 계산된 복사 전달. Rendering Techniques '07, 13-21.
WANG, R., WANG, R., ZHOU, K., PAN, M., 그리고 BAO, H. 2009. 상호작용적인 전역 조명을 위한 효율적인 GPU 기반 접근법. ACM Trans. Graph. 28 (7월), 91:1-91:8.
WARD, G. J. 1992. Measuring and modeling anisotropic reflection. In Proc. SIGGRAPH '92, 265-272.