



Abstract
본 논문은 복잡한 장면의 새로운 시점 이미지(뷰) 를 합성하기 위한 최신 방법을 제안합니다. 핵심 아이디어는 여러 입력 뷰로부터 장면을 연속적인 볼륨 함수 로 표현하는 것으로, 완전 연결 심층 신경망(컨볼루션 없이 MLP) 하나가 장면을 압축해서 담도록 학습됩니다.
네트워크는 5차원 입력
•
공간 위치
•
시점 방향
을 받아, 해당 위치의 볼륨 밀도(density) 와 시점 의존 색상(radiance) 을 출력합니다.
이 출력을 카메라 광선(ray)을 따라 반복적으로 질의(query)하고, 고전적인 볼륨 렌더링(volume rendering) 적분으로 픽셀 색을 합성합니다. 이 렌더링 과정은 자연스럽게 미분 가능(differentiable) 하므로, 카메라 포즈가 알려진 이미지 집합만으로도 관측 이미지와 렌더링 이미지의 오차를 최소화하는 방식으로 장면 표현을 직접 최적화할 수 있습니다.
제안한 NeRF(Neural Radiance Fields) 기반 표현은 복잡한 기하학과 재질(외관)을 가진 장면에서도 포토리얼리스틱한 새로운 뷰를 효과적으로 생성하며, 신경 렌더링 및 뷰 합성 분야의 기존 방법들을 정량·정성적으로 능가하는 성능을 보입니다.
1. INTRODUCTION
본 연구는 오랫동안 연구되어 온 뷰 합성(view synthesis) 문제를 새로운 관점에서 다룹니다. 뷰 합성이란, 여러 장의 입력 이미지와 카메라 포즈(위치·방향)가 주어졌을 때 관측되지 않은 시점의 이미지를 렌더링 하는 문제입니다. 새로운 시점에서 포토리얼리스틱한 결과를 얻기 위해서는 장면의 복잡한 기하학과 재질 반사 특성을 함께 모델링해야 합니다.
기존에도 다양한 장면 표현과 렌더링 기법이 제안되었지만, 카메라 기준선(baseline) 이 큰 조건에서 안정적으로 고품질의 포토리얼리스틱 렌더링을 달성하기는 어려웠습니다. 이에 본 논문은 많은 고해상도 입력 뷰를 잘 재현하도록 최적화할 수 있으면서, 동시에 메모리 효율이 뛰어난 새로운 장면 표현을 제안합니다(그림 1).
우리는 정적 장면을 연속적인 5D 함수 로 표현합니다. 이 함수는 임의의 공간 위치 와 시점 방향 에 대해,
•
해당 위치의 방출 복사율(radiance)
•
해당 위치의 밀도(density)
를 출력합니다. 여기서 밀도는 광선이 매질을 통과하며 누적되는 불투명도(differential opacity)를 결정하는 값으로 해석할 수 있습니다.
제안 방법은 깊은 완전 연결 신경망, 즉 MLP(multilayer perceptron) 을 최적화하여 컨볼루션 레이어 없이 단일 5D 입력 로부터 밀도와 시점 의존 RGB 색상을 회귀하도록 학습합니다.

그림 1. 우리는 입력 이미지 세트로부터 장면의 연속적인 5D 신경 복사장 표현을 최적화하는 방법을 제시해요. 이 표현은 임의의 연속 위치에서 볼륨 밀도와 시점 의존적 색상을 나타냅니다. 볼륨 렌더링 기법을 사용해 광선을 따라 장면 표현의 샘플을 축적하여 어떤 시점에서든 렌더링할 수 있어요. 여기서는 합성 Drums 장면의 100개 입력 뷰를 시각화했어요. 이 뷰들은 주변 반구에서 무작위로 캡처되었으며, 최적화된 NeRF 표현에서 렌더링된 두 개의 새로운 뷰를 보여줍니다
특정 시점에서 이 신경 복사장(NeRF)을 렌더링하기 위해 다음 세 단계를 거쳐요.
1) 카메라 광선을 장면에 투사해 3D 샘플 지점들을 생성합니다.
2) 이 점들과 해당 2D 시점 방향을 신경망에 입력해 색상과 밀도를 출력합니다.
3) 고전적인 볼륨 렌더링 기법으로 이 값들을 2D 이미지로 합성합니다.
이 과정은 자연스럽게 미분 가능하기 때문에, gradient descent로 모델을 최적화할 수 있어요. 관찰된 이미지와 렌더링된 이미지 간의 오류를 최소화하는 방식이죠. 여러 시점에서 오류를 최소화하면 네트워크가 장면의 일관된 모델을 학습합니다. 실제 장면 내용이 있는 위치에 높은 밀도와 정확한 색상을 할당하는 거예요.
NeRF 논문의 맥락에서 보면, 볼륨 렌더링 과정 전체가 미분 가능하기 때문에 관찰된 이미지와 렌더링된 이미지 사이의 오차를 이용해 신경망의 가중치를 직접 최적화할 수 있다는 거예요. 만약 이 과정이 미분 불가능했다면, 어떻게 파라미터를 조정해야 더 나은 결과를 얻을지 알 수 없었을 거예요.
그림 2는 이 전체 파이프라인을 보여줍니다.
기본 구현이 복잡한 장면에서 충분히 높은 해상도로 수렴하지 않는다는 것을 발견했어요. 이를 해결하기 위해 입력 5D 좌표를 positional encoding으로 변환했습니다. 이를 통해 MLP가 더 높은 주파수 함수를 표현할 수 있게 됩니다.
우리 방법은 복잡한 실제 기하학과 외관을 표현할 수 있고, 투영 이미지를 사용한 gradient 기반 최적화에 적합해요. 장면을 신경망 매개변수에 저장함으로써 이산화된 voxel 그리드의 과도한 저장 비용 문제를 해결했습니다. 결과적으로 우리의 neural radiance field 방법은 정량적으로 우수한 성능을 보여줍니다.
이 논문의 원본 버전은 2020년 유럽 컴퓨터 비전 학회에서 발표되었습니다.
research highlights
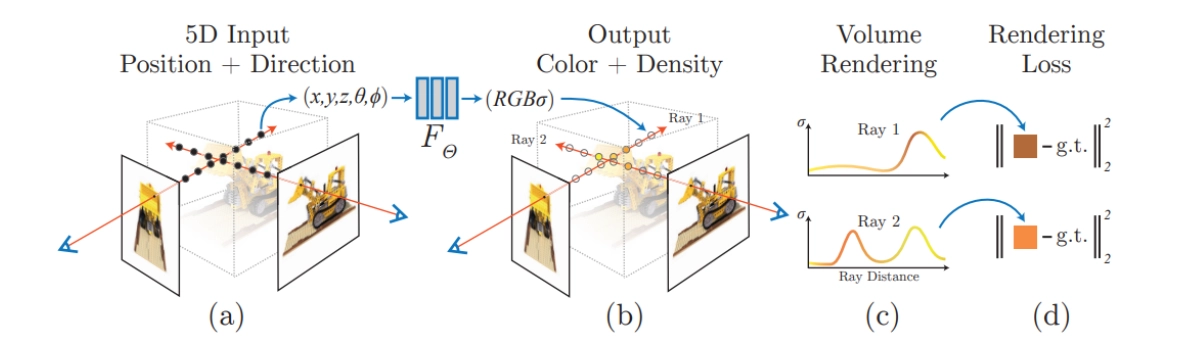
그림 2. 우리의 neural radiance field 장면 표현과 미분 가능한 렌더링 절차의 개요입니다. (a) 카메라 광선을 따라 5D 좌표(위치와 시선 방향)를 샘플링하여 이미지를 합성합니다. (b) 이 위치들을 MLP에 입력하여 색상과 볼륨 밀도를 생성합니다. (c) 볼륨 렌더링 기법으로 이 값들을 이미지로 합성합니다. (d) 렌더링 함수가 미분 가능하므로, 합성된 이미지와 실제 관찰된 이미지 간의 오차를 최소화하여 장면 표현을 최적화할 수 있습니다.
그리고 질적으로는 최신의 view synthesis 방법들보다 뛰어난 성능을 보여요. 예를 들어, neural 3D 표현을 장면에 맞추는 작업이나, 샘플링된 볼륨 표현을 예측하기 위해 deep convolutional networks (CNNs)를 훈련시키는 작업보다 더 나은 결과를 냅니다. 이 논문은 자연 환경에서 촬영된 RGB 이미지를 통해 실제 물체와 장면의 고해상도 포토리얼리스틱한 새로운 뷰를 렌더링할 수 있는 최초의 연속적인 neural scene 표현을 제시합니다.
2. 관련 연구
최근 컴퓨터 비전 분야에서는 장면을 명시적인 메쉬나 복셀로 저장하기보다, 신경망(주로 MLP)의 가중치 자체에 장면을 인코딩 하는 방향이 크게 주목받고 있습니다. 이 계열의 방법은 3D 공간 좌표를 입력으로 받아 서명 거리 함수(SDF)나 점유 필드(occupancy field) 같은 암묵적(implicit) 표현 을 직접 회귀하는 형태로 이해할 수 있습니다.
다만 이러한 신경 암묵 표현은, 전통적인 삼각형 메쉬나 복셀 그리드처럼 이산 구조를 사용하는 방법들에 비해 복잡한 기하학을 높은 해상도로 안정적으로 복원 하는 데 한계를 보이는 경우가 있었습니다.
본 절에서는 (1) 신경 기반 3D 형태 표현과 (2) 뷰 합성 및 이미지 기반 렌더링 연구를 간단히 정리한 뒤, 복잡하고 현실적인 장면에서 최첨단 수준의 결과를 달성하기 위해 신경 장면 표현의 표현력을 확장 하고자 하는 본 논문의 접근과 비교합니다.
2.1. Neural 3D 형태 표현
최근 연구들은 3D 좌표 를 입력으로 받아 서명 거리 함수(SDF) 또는 점유 필드(occupancy field) 를 예측하도록 심층 신경망을 최적화하여, 연속적인 3D 형태를 암묵적(implicit) 으로 표현하는 방법을 탐구해 왔습니다. 다만 이러한 접근은 종종 ShapeNet과 같은 합성 3D 데이터셋에서 제공되는 정답 기하학(ground-truth geometry) 을 필요로 한다는 제약이 있었습니다.
이후 연구들은 미분 가능한 렌더링(differentiable rendering) 을 도입하여, 2D 관측 이미지 만으로도 신경 암묵 형태 표현을 학습할 수 있도록 해당 요구를 완화했습니다. 예를 들어 Niemeyer 등¹⁴은 표면을 3D 점유 필드로 모델링한 뒤, 각 광선의 표면 교차점을 수치적으로 찾고 암묵적 미분(implicit differentiation)을 통해 도함수를 계산합니다. 교차점은 신경 3D 텍스처 필드에 입력되어 해당 위치의 확산 색을 예측합니다. Sitzmann 등²¹은 연속 3D 좌표에서 특징 벡터와 RGB를 출력하는 신경 표현과, 광선을 따라 이동하며 표면 위치를 결정하는 순환 신경망 기반의 미분 가능한 렌더링 함수를 제안했습니다.
이 계열의 방법들은 연속 표현을 통해 복잡한 기하학을 다룰 잠재력이 있지만, 초기 결과들은 주로 낮은 기하학적 복잡성을 가진 형태에 집중되어 과도하게 매끄러운(oversmoothed) 렌더링을 보이기도 했습니다. 본 논문은 이러한 흐름과 구별되게, 3D 위치와 시점 방향을 함께 고려하는 5D 방사 필드(NeRF) 를 직접 최적화하여, 복잡한 장면에서도 고해상도 기하학과 외관을 보다 효과적으로 표현하고자 합니다.
2.2. 뷰 합성 및 이미지 기반 렌더링
컴퓨터 비전 및 컴퓨터 그래픽스 커뮤니티는 관측 이미지로부터 기하학(geometry)과 외관(appearance)을 추정하여 새로운 시점 이미지를 합성 하는 문제에서 꾸준한 진전을 이루어 왔습니다. 대표적인 흐름 중 하나는 메쉬 기반 장면 표현 으로, 차별화된 래스터라이저⁹나 미분 가능한 경로 추적기⁷를 이용해 관측 이미지를 재현하도록 메쉬를 직접 최적화할 수 있습니다.
그러나 이미지 재투영(reprojection)에 기반한 메쉬 최적화는 최적화 지형이 불안정하거나 지역해(local minima)에 빠지는 등 실용적으로 어려운 경우가 많습니다. 또한 일부 방법은 최적화 시작점으로 고정된 위상의 템플릿 메쉬 를 필요로 하는데⁷, 이는 제약 없는 실제 장면에서는 일반적으로 उपलब्ध하지 않습니다.
또 다른 흐름은 볼륨(volume) 기반 장면 표현 을 이용해 입력 RGB 이미지로부터 고품질의 시점 합성을 수행하는 접근입니다. 볼륨 기반 방법은 복잡한 형태와 재질을 비교적 자연스럽게 표현할 수 있고, 미분 가능한 렌더링을 통해 경사 기반 최적화 와도 잘 결합됩니다. 또한 메쉬 기반 방법에 비해 시각적으로 덜 거슬리는 아티팩트를 생성하는 경향이 있습니다.
초기 볼륨 기반 접근은 관측 이미지를 이용해 복셀 그리드(voxel grid)를 직접 채우는 방식이었으며, 이후에는 대규모 데이터셋으로부터 입력 이미지 세트에 대응하는 샘플링 볼륨 표현을 예측하도록 딥 네트워크를 학습하는 방법들이 제안되었습니다. 또한 특정 장면(scene)마다 CNN과 샘플링된 복셀 그리드를 결합해 최적화하여, CNN이 이산화(discretization)로 인한 아티팩트를 보완하도록 하는 방식도 연구되었습니다.
다만 볼륨 기반 기술은 고해상도 이미지를 처리할 때 근본적인 계산·메모리 한계 에 직면합니다. 이산 샘플링을 사용하는 이상, 해상도를 올리기 위해 더 촘촘하게 3D 공간을 샘플링해야 하며, 이에 따라 시간 및 공간 복잡도가 급격히 증가합니다. 본 논문은 이러한 한계를 완화하기 위해, 연속적인 볼륨을 복셀 그리드가 아니라 완전 연결 신경망의 파라미터 내부에 인코딩하는 방식(NeRF)을 제안합니다. 이로써 높은 품질의 렌더링을 제공하면서도 저장 비용을 크게 줄일 수 있습니다.
3. NEURAL RADIANCE FIELD SCENE REPRESENTATION
본 논문은 장면을 연속적인 5D 벡터값 함수 로 표현합니다. 입력은
•
3D 위치
•
시점 방향(실제로는 단위 벡터)
이며, 출력은
•
방출 색상
•
볼륨 밀도
입니다.
즉, 장면은 공간의 임의의 점과 방향에 대해 “그 방향으로 보았을 때 어떤 색이 나오며, 그 지점이 얼마나 불투명한가”를 반환하는 함수로 정의됩니다. 이 연속 표현을 MLP 로 근사하여
가 되도록 학습하며, 가중치 는 입력 뷰들을 재현하도록 최적화됩니다.
표현의 다중 뷰 일관성을 유도하기 위해, 네트워크는 볼륨 밀도 를 위치 의 함수로만 예측 하도록 제한합니다. 반면, 색상 는 위치뿐 아니라 시점 방향 에도 의존할 수 있도록 하여, 반사광(specular highlight) 등 비람버시안(non-Lambertian) 효과를 모델링할 수 있게 합니다.
구체적으로 MLP는 입력 3D 좌표 를 먼저 8개의 완전 연결 레이어로 처리하며, 각 레이어는 ReLU 활성화와 256채널을 사용합니다. 이후 네트워크는 밀도 와 256차원의 특징 벡터(feature vector)를 출력합니다. 이 특징 벡터는 시점 방향 와 결합(concatenate)되어, ReLU 활성화와 128채널을 사용하는 추가 완전 연결 레이어를 거친 뒤 최종적으로 시점 의존 RGB 색상 를 출력합니다.
시점 방향 입력을 통해 비람버시안 효과를 표현하는 예시는 그림 3에서 확인할 수 있습니다. 그림 4에서 보이듯이, 시점 의존성을 제거하고 위치 만으로 학습한 모델은 반사광과 같은 현상을 재현하는 데 어려움을 보입니다.
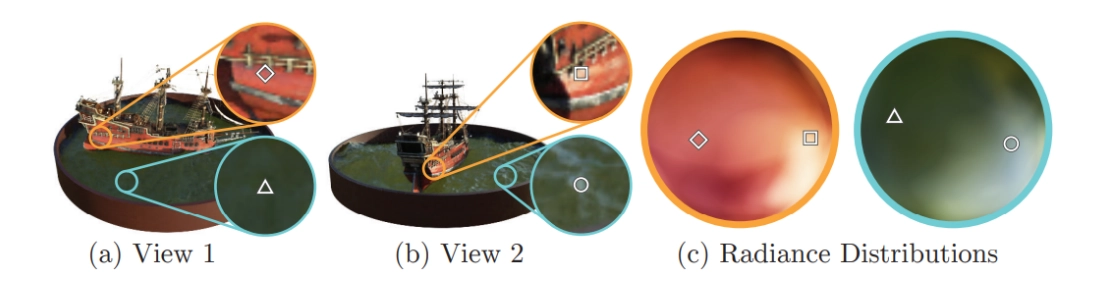
그림 3. 시야 의존적인 방사 광도의 시각화입니다. 우리 신경 방사 필드 표현은 공간 위치 X와 시야 방향 d의 5D 함수로 RGB 색상을 출력해요. 여기서는 Ship 장면의 신경 표현에서 두 공간 위치에 대한 예시 방향 색상 분포를 시각화했어요. (a)와 (b)에서는 두 고정된 3D 점의 외관을 두 다른 카메라 위치에서 보여줍니다: 하나는 배의 측면(오렌지색 삽입)이고, 다른 하나는 물 표면(파란색 삽입)입니다. 우리 방법은 이 두 3D 점의 변화하는 반사 외관을 예측하고, (c)에서는 시야 방향의 전체 반구에 걸쳐 이 동작이 어떻게 일반화되는지를 보여줍니다.
4. 방사 필드를 이용한 볼륨 렌더링
5D 신경 방사 필드(NeRF)가 주어졌을 때, 특정 카메라에서의 이미지를 얻는 과정은 고전적인 볼륨 렌더링(volume rendering) 원리에 기반합니다. 핵심은 각 픽셀에 대응하는 카메라 광선 를 따라가며, 연속적으로 정의된 를 샘플링하고 이를 적분(누적)하여 최종 픽셀 색 를 계산하는 것입니다.
여기서 밀도 는 위치 에서 광선이 매질에 의해 흡수되거나 산란되어 “종료될” 확률과 관련된 양으로 해석할 수 있으며, 광선 방향으로 누적된 투과율(transmittance)이 함께 결합되어 최종 색을 결정합니다.
이때 는 근거리·원거리 경계 를 갖는 적분 형태로 표현됩니다:
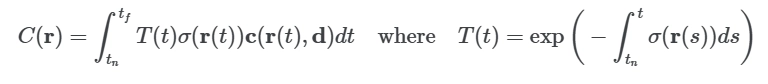
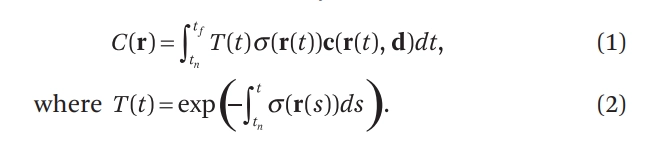
함수 는 에서 까지 광선 경로를 따라 누적된 투과율(transmittance) 을 의미하며, 직관적으로는 “광선이 그 구간을 통과하는 동안 다른 입자에 의해 흡수·산란되지 않고 살아남을 확률”로 해석할 수 있습니다.
NeRF 렌더링에서 중요한 점은, 각 픽셀에 대해 이 연속 적분 를 직접 계산하는 대신, 계산 가능한 형태로 수치적으로 근사 해야 한다는 것입니다.
이 적분은 닫힌 형태로 계산하기 어렵기 때문에, 우리는 이를 수치 적분(quadrature) 으로 근사합니다. 전통적인 복셀 그리드 렌더링에서 사용되는 결정론적 샘플링은 질의 지점이 고정된 격자에 묶이기 때문에, 연속 표현(MLP)을 사용하더라도 사실상 표현 해상도에 상한 이 생길 수 있습니다.
따라서 본 논문은 구간 를 개의 구간(bin)으로 나누고, 각 구간마다 무작위로 1개의 샘플을 선택하는 층화 샘플링(stratified sampling) 을 사용합니다.
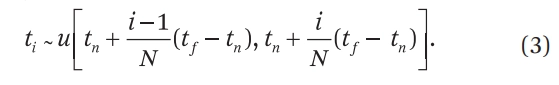
비록 적분을 이산 샘플들의 합으로 근사하지만, 층화 샘플링을 사용하면 최적화 과정에서 MLP가 서로 다른 연속 위치에서 반복적으로 평가 되므로, 연속적인 장면 표현의 장점을 유지할 수 있습니다.
샘플링된 들로부터 를 계산하는 방식은 Max¹⁰의 볼륨 렌더링 정식화와 같은 계열의 구적법으로 유도되며, 결과적으로 전통적인 알파 합성(alpha compositing) 형태로 정리됩니다.
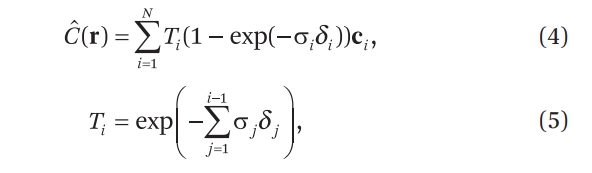
여기서 는 인접한 샘플 간의 거리(간격)를 의미합니다.
그림 4는 (1) 시점 의존성(방향 입력)이 비람버시안 반사 효과를 모델링하는 데 어떻게 기여하는지, 그리고 (2) 위치 인코딩(positional encoding)이 고주파 기하학·텍스처를 표현하는 데 왜 중요한지를 시각화합니다.

마지막으로 로부터 를 계산하는 이 합성 함수는 전체적으로 미분 가능 하며, 표준 볼륨 렌더링에서의 알파 값은 일반적으로
와 같이 정의됩니다.
5. Neural Radiance Field 최적화
앞선 절들에서는 신경 방사 필드로 장면을 표현하고, 이를 볼륨 렌더링으로 이미지에 투영하는 기본 구성 요소를 정리했습니다. 그러나 단순한 구성만으로는 복잡한 장면에서 충분히 높은 해상도와 세부 표현을 안정적으로 얻기 어렵습니다.
본 절에서는 고해상도 장면에서의 성능을 개선하기 위해 제안된 두 가지 핵심 요소를 소개합니다.
•
위치 인코딩(positional encoding): MLP가 고주파 성분(날카로운 경계, 반복 패턴 등)을 더 잘 표현하도록 입력 좌표를 고차원으로 매핑합니다.
•
계층적 샘플링(hierarchical sampling): 동일한 계산 예산 내에서 중요한 구간에 샘플을 더 집중시켜 렌더링 품질과 수렴을 개선합니다.
세부 구현과 설정은 원 논문을 참고합니다.¹³
5.1. 위치 인코딩
MLP는 보편 근사기(universal function approximator)이지만, 입력 좌표 를 그대로 사용하면 색상과 기하학에서 나타나는 고주파 변화(날카로운 경계, 미세 텍스처 등) 를 충분히 표현하지 못하는 경향이 관찰되었습니다. 이는 Rahaman 등¹⁷이 지적한 심층 신경망의 스펙트럼 편향(spectral bias), 즉 저주파 함수를 우선적으로 학습하는 성향과도 일치합니다.
이를 완화하기 위해, 본 논문은 입력 좌표를 그대로 MLP에 넣는 대신, 고주파 성분을 포함한 더 풍부한 표현이 가능하도록 위치 인코딩(positional encoding) 함수 를 적용합니다. 즉, 모델은
와 같은 형태로 재구성될 수 있으며(그림 4), 는 일반적인 MLP입니다.
본 논문에서 사용하는 인코딩 함수는 다음과 같습니다.
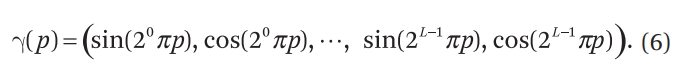
는 위치 의 각 성분과 시점 방향 의 각 성분에 독립적으로 적용되며, 입력 값은 보통 범위로 정규화됩니다. 실험 설정에서는 위치 인코딩에 대해 , 방향 인코딩에 대해 를 사용합니다.
이와 같은 Fourier feature/positional encoding 계열의 매핑이 고주파 신호를 더 빠르고 안정적으로 표현하게 만드는 이유는 후속 연구²²에서 더 자세히 논의됩니다.
5.2 계층적 볼륨 샘플링
각 카메라 광선을 따라 N개의 쿼리 지점에서 신경 방사 필드 네트워크를 조밀하게 평가하는 우리의 렌더링 전략은 비효율적입니다. 렌더링된 이미지에 기여하지 않는 빈 공간과 가려진 영역도 반복적으로 샘플링되기 때문입니다. 우리는 볼륨 렌더링 초기 연구[20]에서 영감을 얻어, 최종 렌더링에 대한 예상 기여도에 비례해 샘플을 배분함으로써 렌더링 효율을 높이는 계층적 표현을 제안합니다.
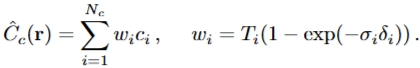
장면을 표현할 때 단일 네트워크만 사용하는 대신, 우리는 두 개의 네트워크, 즉 "거친(coarse)" 네트워크와 "정밀한(fine)" 네트워크를 함께 최적화합니다. 먼저 층화 샘플링(stratified sampling)으로 개의 위치 집합을 샘플링하고, Eqn. 2와 3에 설명된 대로 이 지점들에서 "거친" 네트워크를 평가합니다. 이후 "거친" 네트워크의 출력으로부터 각 광선에서 샘플이 볼륨의 중요한 부분에 더 집중되도록, 더 정보에 입각한 지점 샘플링을 생성합니다.
이를 위해 먼저 Eqn. 3의 거친 네트워크로부터 얻은 알파 합성 색상을 다음과 같이 다시 씁니다:
가중치를 다음과 같이 정규화하면, 광선을 따라 구간 상수 확률 밀도 함수(PDF)가 생성됩니다:
이 분포에서 역변환 샘플링(inverse transform sampling)으로 두 번째 개의 위치 집합을 샘플링하고, 첫 번째와 두 번째 샘플 집합의 합집합에서 "정밀한" 네트워크를 평가합니다. 마지막으로 Eqn. 3을 사용하되 모든 개의 샘플을 이용해 광선의 최종 렌더링 색상 을 계산합니다.
이 절차는 보이는 콘텐츠가 포함될 것으로 예상되는 구간에 더 많은 샘플을 할당합니다. 목표는 중요도 샘플링(importance sampling)과 유사하지만, 우리는 샘플링된 값을 전체 적분 영역의 비균일 이산화로 사용하며, 각 샘플을 전체 적분의 독립적인 확률적 추정치로 취급하지 않습니다.
5.3. 구현 세부사항
본 방법은 각 장면(scene)마다 별도의 신경 연속 볼륨 표현(neural continuous volume representation) 네트워크 를 최적화합니다. 이를 위해서는 RGB 이미지 집합, 카메라 포즈(외부 파라미터), 내재적 파라미터(intrinsics), 그리고 장면 경계(near/far 등)가 필요합니다. 합성 데이터는 정답 카메라 파라미터와 경계를 사용하며, 실제 데이터는 COLMAP 기반의 구조-운동(SfM) 패키지¹⁸로 해당 파라미터를 추정합니다.
최적화 반복(iteration)마다 데이터셋의 픽셀들로부터 카메라 광선을 무작위로 샘플링하고, 각 광선에 대해 개의 샘플 지점에서 네트워크를 질의하여 를 얻습니다. 이후 4절의 볼륨 렌더링 절차로 광선의 예측 색 를 계산합니다. 손실 함수는 관측 색 과 예측 색 사이의 평균 제곱 오차(MSE) 입니다.
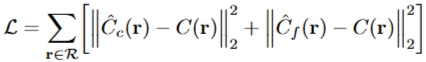
실험에서는 배치당 4096개의 광선을 사용하며, 각 광선은 총 개의 샘플로 평가됩니다. 이는 coarse/fine 두 단계의 계층적 네트워크로 분해되며, 자세한 설정은 원 논문¹³을 따릅니다. 최적화에는 Adam 옵티마이저⁶를 사용하고, 학습률은 에서 시작해 까지 지수적으로 감소시킵니다. 단일 장면 최적화는 일반적으로 GPU 한 대에서 1–2일이 소요됩니다.
6. Result
본 절에서는 제안 방법의 성능을 정량적(Table 1) 및 정성적(그림 5, 6)으로 평가하고, 기존 방법들과의 비교를 통해 우수성을 보입니다. 특히 새로운 시점에서 연속적인 카메라 경로를 따라 렌더링할 때 나타나는 개선 효과는 동영상에서 더욱 명확하게 확인할 수 있습니다. 관련 동영상, 코드, 데이터셋은 논문에서 제공하는 프로젝트 페이지(https://www.matthew)에서에서)에서)에서)에서)에서)에서) 확인할 수 있습니다.
6.1. Data set
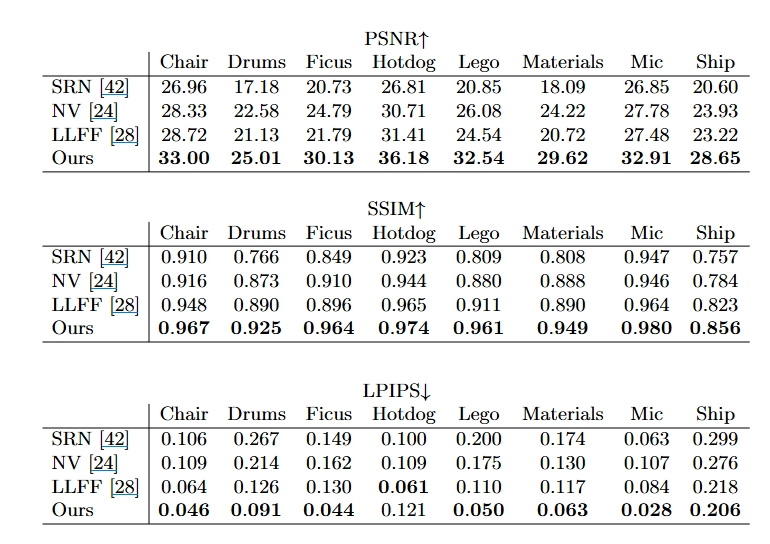
먼저 합성 객체 렌더링 데이터셋에 대한 결과를 보고합니다(Table 1의 “Diffuse Synthetic 360°”, “Realistic Synthetic 360°”). 비교에 사용한 DeepVoxels²⁰ 데이터셋은 네 개의 램버시안(Lambertian) 객체로 구성됩니다.
표 1은 합성 데이터와 실제 데이터 모두에서 제안 방법이 기존 접근보다 정량적으로 우수한 성능을 보임을 요약합니다.

평가 지표로는 PSNR/SSIM(값이 클수록 우수)과 LPIPS(값이 작을수록 우수)를 사용합니다. DeepVoxels²⁰ 데이터셋은 비교적 단순한 기하학을 가진 4개의 확산(Lambertian) 객체로 구성됩니다. 또한 본 논문은 복잡한 기하학과 비람버시안 재질을 포함하는 8개 객체에 대해, 경로 추적(path tracing) 기반으로 렌더링한 자체 현실적 합성 데이터셋 을 추가로 구성하여 평가합니다.
실제 데이터셋은 휴대폰으로 손에 들고 전방을 향해 촬영한 8개의 실제 장면으로 구성됩니다. Neural Volumes(NV)는 관심 객체가 제한된 볼륨(bound volume) 내부에 포함되어야 한다는 가정이 있어 해당 실제 데이터 설정에서는 평가할 수 없습니다. 표 1에서 굵은 글씨는 각 지표에서 최고 성능을 기록한 방법을 나타냅니다.

그림 5. 물리 기반 렌더러로 생성된 새로운 합성 데이터셋의 장면에 대한 테스트 세트 뷰 비교입니다. 우리 방법은 Ship의 돛대, Lego의 기어와 트레드, Microphone의 반짝이는 스탠드와 메쉬 그릴, Material의 비람버트 반사율 같은 기하학적 세부 사항과 외관을 잘 복원할 수 있어요. LLFF는 Microphone 스탠드와 Material 객체의 가장자리에서 밴딩 아티팩트를, Ship의 돛대와 Lego 객체 내부에서 고스트 아티팩트를 보여요. SRN은 모든 경우에 흐릿하고 왜곡된 렌더링을 생성합니다. Neural Volumes는 Microphone의 그릴이나 Lego의 기어의 세부 사항을 포착할 수 없고, Ship의 돛대 기하학을 완전히 복원하지 못해요.
research highlights

그림 6. 실제 장면의 테스트 세트 뷰 비교. LLFF는 실제 장면의 전방 캡처를 위해 특별히 설계되었습니다. 우리 방법은 Fern의 잎, T-rex의 골격 갈비뼈, 난간 등에서 볼 수 있듯이 렌더링된 뷰 전반에 걸쳐 LLFF보다 세밀한 기하학을 더 일관되게 표현합니다. 또한 LLFF가 깨끗하게 렌더링하기 어려운 부분적으로 가려진 영역도 정확하게 재구성합니다. 예를 들어 Fern 하단 크롭의 잎 뒤에 있는 노란 선반과 Orchid 하단 크롭 배경의 녹색 잎이 있습니다. 여러 렌더링 간의 블렌딩은 LLFF에서 반복된 가장자리를 초래할 수 있으며, Orchid 상단 크롭에서 이를 확인할 수 있습니다. SRN은 각 장면의 저주파 기하학 및 색상 변화는 포착하지만 세부 사항은 재현하지 못합니다.
DeepVoxels²⁰ 합성 데이터셋은 단순한 기하학을 갖는 객체들로 구성되며, 각 객체는 상반구에서 샘플링된 시점에서 해상도로 렌더링됩니다(입력 479뷰, 테스트 1000뷰).
추가로 본 논문은 복잡한 기하학과 현실적인 비람버시안 재질을 포함하는 8개 객체에 대해 경로 추적 이미지로 구성된 자체 데이터셋을 생성합니다. 이 중 6개 객체는 상반구 시점에서, 2개 객체는 전 구(sphere)에서 샘플링된 시점으로 렌더링합니다. 각 장면(scene)에 대해 100개 뷰를 학습 입력으로, 200개 뷰를 테스트용으로 사용하며, 해상도는 모두 입니다.
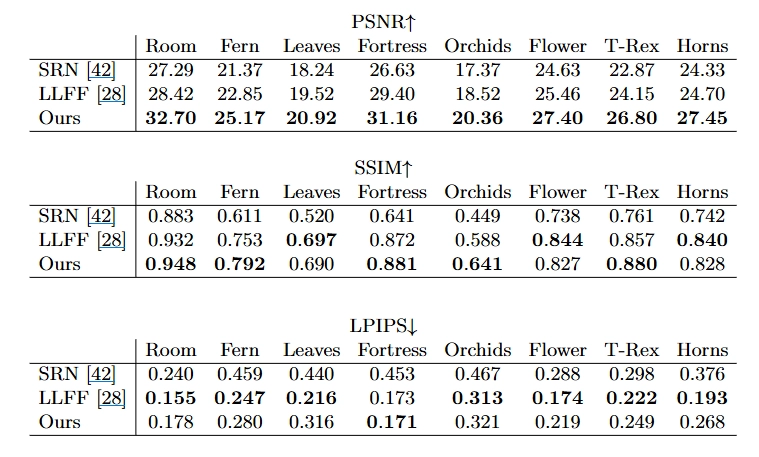
실제 데이터셋(표 1의 “Real ForwardFacing”)은 대략 전방을 향해(handheld, forward-facing) 촬영된 8개의 실제 장면으로 구성됩니다(5개는 LLFF¹²에서 제공, 3개는 본 논문에서 캡처). 각 장면은 20–62장의 이미지로 촬영되며, 이 중 을 테스트 세트로 사용합니다. 모든 이미지는 해상도입니다.
6.2. 비교
제안 방법의 성능을 평가하기 위해, 뷰 합성 분야에서 널리 사용되는 강력한 기준 방법들과 비교 실험을 수행합니다. LLFF¹²를 제외한 비교 방법들은 각 장면마다 별도의 모델을 최적화 하며, 동일한 입력 뷰 세트를 사용해 장면을 재현하도록 학습합니다. 반면 LLFF는 대규모 데이터셋에서 하나의 3D CNN을 사전 학습한 뒤, 테스트 시에는 해당 네트워크를 사용해 새로운 장면의 입력 이미지를 처리하는 방식으로 동작합니다.
Neural Volumes (NV)⁸ 는 특정 배경 앞의 경계된 볼륨(bound volume) 내부에 완전히 포함된 관심 객체(object)에 대해 새로운 뷰를 합성하는 방법입니다. 이 설정에서는 관심 객체가 없는 배경을 별도로 캡처해야 하며, 깊은 3D CNN을 통해 샘플의 RGB$alpha$ 복셀 그리드와 샘플의 3D 왜곡(distortion) 그리드를 예측합니다. 예측된 왜곡 그리드를 통해 카메라 광선을 워핑(warping)하여 새로운 뷰를 렌더링합니다.
Scene Representation Networks (SRN)²¹ 은 연속 장면을 불투명한 표면으로 모델링합니다. 이는 각 3D 좌표 를 특징 벡터로 매핑하는 MLP로 암묵적으로 정의되며, 광선을 따라 이동하기 위해 3D 좌표에서 다음 스텝 크기를 예측하는 순환 신경망을 학습합니다. 최종적으로 얻은 특징 벡터는 해당 표면 지점의 단일 색상으로 디코딩됩니다. SRN은 DeepVoxels²⁰의 후속 연구로, 본 논문에서는 DeepVoxels와의 직접 비교는 포함하지 않습니다.
LLFF¹² 는 잘 샘플링된 전방향 장면에 대해 포토리얼리스틱한 새로운 뷰를 생성하도록 설계된 방법입니다. 입력 뷰들에 대해 분할된 프러스텀(frustum) 샘플링 기반의 RGB$alpha$ 그리드, 즉 멀티플레인 이미지(MPI²⁵)를 예측한 뒤, 알파 합성과 인접 MPI의 블렌딩을 통해 새로운 시점 이미지를 렌더링합니다.
6.3. 논의
실험 결과, 제안 방법은 모든 설정에서 장면별 최적화를 수행하는 두 기준선(NV, SRN)을 일관되게 능가합니다. 또한 LLFF와 비교하더라도 정량 지표와 시각적 품질 모두에서 더 우수한 렌더링을 생성함을 확인했습니다. 이는 LLFF가 입력 이미지만을 사용해 테스트 장면을 처리한다는 조건에서도 성립합니다.
각 비교 방법의 한계는 다음과 같이 해석할 수 있습니다. SRN은 광선(ray)마다 단일 깊이와 단일 색상을 선택하는 형태의 표면 기반 표현을 사용하므로, 복잡한 가림(occlusion) 구조나 미세 텍스처를 포함한 장면에서 표현력이 제한되어 결과가 과도하게 매끄러워지는 경향이 있습니다. NV는 상세한 볼륨 기하학과 외관을 일정 수준 포착할 수 있으나, 명시적인 복셀 그리드를 사용하기 때문에 고해상도에서 세부 구조를 표현하는 데 한계가 존재합니다.
LLFF는 입력 뷰 간 재투영 오차가 약 64픽셀을 넘지 않도록 하는 “샘플링 가이드라인”을 전제로 합니다. 그러나 본 논문의 합성 데이터셋에서는 입력 뷰 간 불일치가 400–500픽셀에 달할 수 있어, LLFF가 올바른 기하학을 추정하지 못하는 경우가 발생합니다. 또한 LLFF는 새로운 뷰를 렌더링할 때 서로 다른 장면 표현을 혼합(blending)하는 과정이 포함되며, 이로 인해 보조 동영상에서 관찰되듯 지각적으로 혼란스러운 불일치가 나타날 수 있습니다.
마지막으로 방법들 간의 중요한 실용적 트레이드오프는 시간과 공간(메모리/저장) 입니다. 비교된 단일 장면 최적화 기반 방법들은 장면당 최소 12시간 수준의 학습 시간이 필요한 반면, LLFF는 상대적으로 작은 입력 데이터셋을 수 분 내에 처리할 수 있습니다. 그러나 LLFF는 각 입력 이미지에 대해 큰 3D 볼륨 표현을 생성하므로 저장 비용이 매우 큽니다(예: “Realistic Synthetic” 장면 1개당 15GB 이상). 제안 방법은 장면을 네트워크 가중치로 저장하며, 약 5MB 수준의 파라미터로 표현이 가능하여 LLFF 대비 약 3000배 압축된 저장 효율을 보입니다. 이는 본 데이터셋의 단일 장면 입력 이미지 전체보다도 작은 규모입니다.
7. CONCLUSION
본 논문은 정적 장면을 3D 위치 와 시점 방향 에 대해 색상과 밀도를 출력하는 연속적인 5D 함수로 표현하는 Neural Radiance Field(NeRF) 를 제안했습니다. 또한 이를 미분 가능한 볼륨 렌더링 절차와 결합하여, 다중 뷰 입력 이미지에 대한 재투영 오차를 최소화하는 방식으로 장면 표현을 직접 최적화할 수 있음을 보였습니다.
제안한 표현은 기존의 이산 복셀 그리드 기반 방법들에 비해 메모리 효율이 높으면서도, 복잡한 기하학과 시점 의존적 외관을 포함하는 장면에서 고품질의 새로운 시점 렌더링을 가능하게 합니다. 실험적으로도 합성 및 실제 데이터셋 전반에서 기존 방법들을 정량·정성적으로 능가하는 성능을 확인했습니다.
본 연구는 실제 이미지 기반으로 연속적인 신경 장면 표현을 구축하는 방향에서 중요한 진전을 제시하며, 이후 relighting, 변형 모델링, 애니메이션 등 다양한 확장 연구의 기반이 되었습니다.
A. 추가 구현 세부사항
네트워크 아키텍처 그림 7은 우리의 간단한 완전 연결 아키텍처를 자세히 보여줍니다.
볼륨 경계 우리 방법은 카메라 광선을 따라 연속적인 5D 좌표에서 neural radiance field 표현을 쿼리하여 뷰를 렌더링합니다. 합성 이미지 실험에서는 장면을 원점 중심의 한 변 길이 2인 정육면체 내에 위치하도록 스케일을 조정하고, 이 경계 볼륨 내에서만 쿼리합니다. 실제 이미지 데이터셋은 가장 가까운 지점부터 무한대까지 콘텐츠를 포함할 수 있으므로, normalized device coordinates를 사용하여 깊이 범위를 [−1, 1]로 매핑합니다. 이를 통해 모든 광선 원점이 near plane으로 이동하고, 원근 광선이 평행 광선으로 변환되며, 메트릭 깊이 대신 disparity(역깊이)를 사용하여 모든 좌표가 경계 내에 들어옵니다.
훈련 세부사항 실제 장면 데이터의 경우, 출력 σ 값에 평균 0, 분산 1의 가우시안 노이즈를 추가하여 네트워크를 정규화합니다(ReLU 통과 전). 이는 새로운 뷰 렌더링의 시각적 성능을 약간 향상시킵니다. 모델은 Tensorflow [1]로 구현했습니다.
테스트 시 새로운 뷰를 렌더링하기 위해 코어스 네트워크에서 광선당 64개 점을, 파인 네트워크에서 광선당 192개 점(64 + 128)을 샘플링하여 광선당 총 256번의 네트워크 쿼리를 수행합니다. 합성 데이터셋은 이미지당 640k개 광선을, 실제 장면은 이미지당 762k개 광선을 필요로 하며, 렌더링된 이미지당 1억 5천만~2억 개의 네트워크 쿼리가 발생합니다. NVIDIA V100에서 프레임당 약 30초가 소요됩니다.
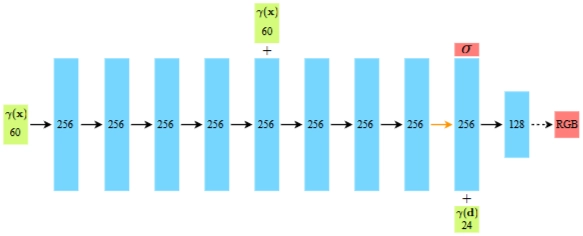
그림 7: 완전 연결 네트워크 아키텍처. 입력 벡터는 초록색, 중간 은닉층은 파란색, 출력 벡터는 빨간색으로 표시되며, 각 블록 안 숫자는 벡터 차원을 나타냅니다. 모든 레이어는 표준 완전 연결 레이어입니다. 검은색 화살표는 ReLU 활성화, 주황색 화살표는 활성화 없음, 점선 검은색 화살표는 시그모이드 활성화를 나타내며, "+"는 벡터 연결을 의미합니다. 입력 위치의 위치 인코딩(γ(x))은 각각 256채널을 가진 8개의 완전 연결 ReLU 레이어를 통과합니다. DeepSDF [32] 아키텍처를 따라 이 입력을 다섯 번째 레이어 활성화에 연결하는 스킵 연결을 포함합니다. 추가 레이어는 볼륨 밀도 σ(ReLU로 음수 방지)와 256차원 특징 벡터를 출력합니다. 이 특징 벡터는 입력 시점 방향의 위치 인코딩(γ(d))과 연결되어 128채널 완전 연결 ReLU 레이어로 처리됩니다. 최종 레이어(시그모이드 활성화)는 방향 d 광선으로 볼 때 위치 x에서 방출된 RGB 복사광을 출력합니다.
B 추가적인 베이스라인 방법 세부 정보
Neural Volumes (NV) [24] 우리는 저자들이 https://github.com/facebookresearch/neuralvolumes에서 공개한 NV 코드를 사용하며, 시간 의존성 없이 단일 장면에 대해 훈련하는 절차를 따릅니다.
Scene Representation Networks (SRN) [42] 우리는 저자들이 https://github.com/vsitzmann/scene-representation-ne에서 공개한 SRN 코드를 사용하며, 단일 장면에 대해 훈련하는 절차를 따릅니다.
Local Light Field Fusion (LLFF) [28] 우리는 저자들이 https://github.com/Fyusion/LLFF에서 공개한 사전 훈련된 LLFF 모델을 사용합니다.
Quantitative Comparisons: SRN 구현은 상당한 양의 GPU 메모리를 요구하며, 4개의 NVIDIA V100 GPU에 병렬화하더라도 이미지 해상도가 512 × 512 픽셀로 제한됩니다.
우리는 합성 데이터셋에 대해 512 × 512 픽셀, 실제 데이터셋에 대해 504 × 376 픽셀에서 SRN의 정량적 지표를 계산합니다. 이는 더 높은 해상도에서 실행 가능한 다른 방법들의 800 × 800 및 1008 × 752와 비교됩니다.
C NDC 레이 공간 유도
우리는 삼각형 래스터화 파이프라인의 일부로 흔히 사용되는 정규화 장치 좌표(NDC) 공간에서 "정면 캡처"를 사용하여 실제 장면을 재구성합니다.
이 공간은 z축(카메라 축)을 깊이(disparity)에 대해 선형으로 변환하면서 평행선을 유지하기 때문에 편리합니다.
여기서는 카메라 공간에서 NDC 공간으로 레이를 매핑하기 위해 적용되는 변환을 유도합니다.
동차 좌표에 대한 표준 3D 원근 투영 행렬은 다음과 같습니다:
여기서 n, f는 근평면(near) 및 원평면(far) 클리핑 평면이고, r과 t는 근평면에서의 장면의 오른쪽 및 위쪽 경계입니다.
(이것은 카메라가 -z 방향을 바라보는 규약입니다.) 동차점 를 투영하기 위해, M을 좌측 곱하고 네 번째 좌표로 나눕니다:
투영된 점은 이제 정규화 장치 좌표(NDC) 공간에 있습니다. 여기서 원래 시야 절두체는 큐브 [-1, 1]^3으로 매핑됩니다.
우리의 목표는 레이 o + td를 NDC 공간의 레이 원점 'o'와 방향'd′로 변환하는 것입니다. 모든 t에 대해 를 만족하는 새로운 t'가 존재해야 합니다. 여기서는 위 행렬을 사용한 투영입니다. 즉, 원래 레이의 투영과 NDC 공간 레이는 동일한 점들을 추적합니다(속도는 다를 수 있습니다).
식 9에서 투영된 점을 (a_x x/z, a_y y/z, a_z + b_z /z)로 다시 작성해 보겠습니다.
새로운 원점 o'와 방향 d'의 성분은 다음을 만족해야 합니다:
자유도 하나를 제거하기 위해, t'=0과 t=0이 동일한 점으로 매핑되도록 결정합니다.
식 10에 t=0과 t'=0을 대입하면 NDC 공간의 원점 o'를 직접 얻을 수 있습니다:
이는 원래 광선 원점의 투영 π(o)과 정확히 일치합니다.
이를 식 10에 임의의 t에 대해 다시 대입하면 t'와 d'의 값을 결정할 수 있습니다:
t에만 의존하는 공통 표현식을 인수분해하면 다음과 같습니다:
원하는 대로 t′ = 0일 때 t = 0임을 주목하십시오.
또한, t → ∞일 때 t′ → 1임을 알 수 있습니다.
원래 투영 행렬로 돌아가서, 우리의 상수들은 다음과 같습니다:
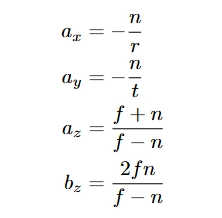
표준 핀홀 카메라 모델을 사용하여 다음과 같이 재매개변수화할 수 있습니다:
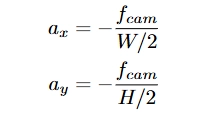
여기서 W와 H는 픽셀 단위의 이미지 너비와 높이이며, fcam은 카메라의 초점 거리입니다.
실제 전방향 캡처에서, 우리는 먼 장면 경계가 무한대라고 가정합니다 (이는 NDC가 z 차원을 역 깊이, 즉 시차를 나타내는 데 사용하기 때문에 거의 비용이 들지 않습니다).
이 극한에서 z 상수들은 다음과 같이 단순화됩니다:
모든 것을 종합하면 다음과 같습니다:
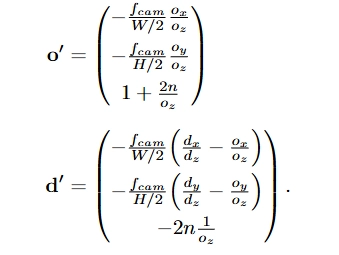
구현의 마지막 세부 사항으로, 우리는 NDC 변환 전에 z = -n에서의 광선 교차점으로 o를 이동시킵니다. 이는 tn = -(n + oz )/dz에 대해 on = o + tnd로 계산합니다.
NDC 광선으로 변환하면, 원래 공간에서 n부터 ∞까지의 시차에 대한 선형 샘플링을 얻기 위해 0부터 1까지 t′를 선형적으로 샘플링할 수 있습니다.

D 추가 결과
장면별 분석 표 3, 4, 5, 6에는 본 논문에서 제시된 정량적 결과를 장면별 지표로 세분화한 내용이 포함되어 있습니다.
장면별 분석은 논문에서 제시된 종합적인 정량적 지표와 일관되며, 저희 방법은 모든 기준선보다 정량적으로 우수한 성능을 보입니다.
LLFF가 LPIPS 지표에서 약간 더 나은 성능을 달성하지만, 저희 방법이 모든 기준선보다 더 나은 다중 시점 일관성을 달성하고 더 적은 아티팩트를 생성하는 저희 보충 영상을 보시기를 권장합니다.

이 데이터셋의 “장면”들은 3D 스캐너로 캡처된 텍스처 매핑된 메쉬로부터 렌더링된, 단순한 기하학적 구조를 가진 모든 확산체 객체들입니다.
DeepVoxels 방법의 지표들은 해당 논문에서 직접 가져왔으며, LPIPS는 보고하지 않고 SSIM에 대해서만 두 개의 유효 숫자를 보고합니다.
이 데이터셋의 “장면”들은 Blender의 Cycles 패스 트레이서를 사용하여 렌더링된, 더 복잡한 기하학적 구조와 비램버시안 재질을 가진 모든 객체들입니다.
이 데이터셋의 장면들은 모두 전면을 향한 휴대폰으로 촬영되었습니다.
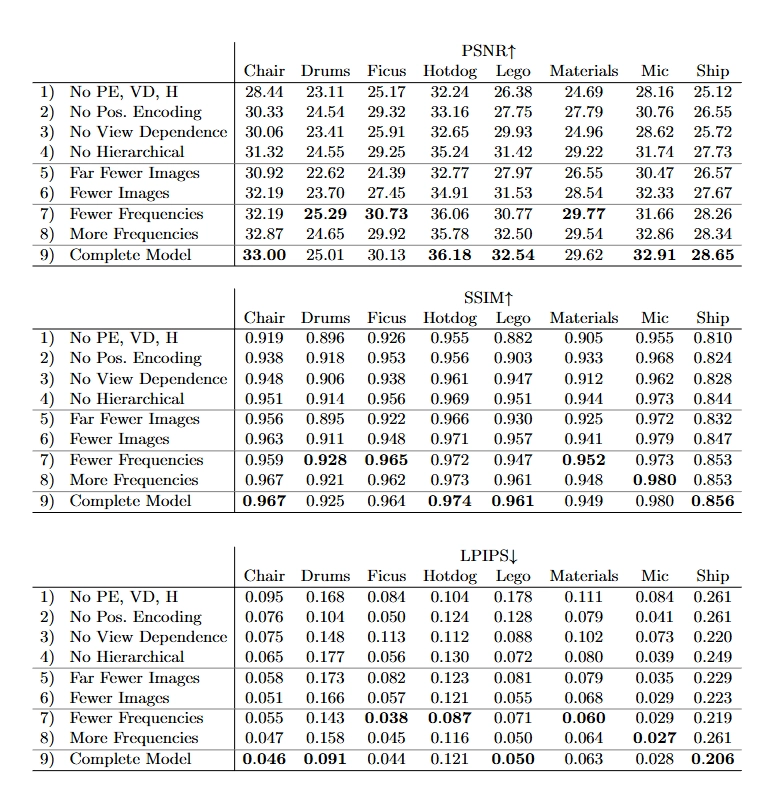
표 6: 저희의 애블레이션 연구에 대한 장면별 정량적 결과입니다.
여기서 사용된 장면들은 표 4와 동일합니다.
Acknowledgments
Kevin Cao, Guowei Frank Yang, Nithin Raghavan에게 의견과 토론에 대해 감사드려요. RR은 ONR의 N000141712687, N000141912293, N000142012529, NSF Chase-CI, Ronald L. Graham Chair의 지원을 받았어요. BM은 Hertz Foundation Fellowship의 지원을 받고 있고, MT는 NSF Graduate Fellowship의 지원을 받고 있어요. Google은 BAIR Commons 프로그램을 통해 클라우드 컴퓨팅 크레딧을 후원해 주었어요. 우리의 현실적인 synthetic dataset에 사용된 모델을 제공해 주신 Blend Swap 사용자들에게 감사드려요: gregzaal (ship), 1DInc (chair), bryanajones (drums), Herberhold (ficus), erickfree (hotdog), Heinzelnisse (lego), elbrujodelatribu (materials), up3d.de (mic).
References
1.
Buehler, C., Bosse, M., McMillan, L., Gortler, S., Cohen, M. Unstructured lumigraph rendering. In SIGGRAPH (2001).
2.
Chang, A.X., Fhnkhouser, T., Guibas, L., Hanrahan, P., Huang, Q., Li, Z., Savarese, S., Savva, M., Song, S., Su, H., et al. ShapeNet: An information-rich 3D model repository. arXiv:1512.03012 (2015).
3.
Curless, B., Levoy, M. 범위 이미지로부터 복잡한 모델을 구축하기 위한 체적 방법. SIGGRAPH (1996)에서 발표했어요.
4.
Debevec, P., Taylor, C.J., Malik,J.
사진으로부터 건축물을 모델링하고 렌더링하는 방법: 기하학 기반과 이미지 기반을 혼합한 접근법. SIGGRAPH (1996)에서 발표했어요.
1.
Kajiya, J.T., Herzen, B.P.V. Ray tracing volume densities. Comput. Graph. (SIGGRAPH) (1984).
2.
Kingma, D.P., Ba, J. Adam: A method for stochastic optimization. In ICLR (2015).
3.
Li, T.-M., Aittala, M., Durand, F., Lehtinen, J. 엣지 샘플링을 통한 미분 가능한 몬테카를로 레이 트레이싱. ACM Trans. Graph. (SIGGRAPH Asia) (2018)에서 발표했어요.
4.
Lombardi, S., Simon, T., Saragih, J., Schwartz, G., Lehrmann, A., Sheikh, Y. Neural volumes: 이미지로부터 동적 렌더링 가능한 볼륨을 학습하는 방법. ACM Trans. Graph. (SIGGRAPH) (2019)에서 발표했어요.
5.
Loper, M.M., Black, M.J. OpenDR: An approximate differentiable renderer. In ECCV (2014).
6.
Max, N. Optical models for direct volume rendering. IEEE Trans. Visual. Comput. Graph. (1995).
7.
Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S., Geiger, A. 점유 네트워크: 함수 공간에서 3D 재구성을 학습하는 방법. CVPR (2019)에서 발표했어요.
8.
Mildenhall, B., Srinivasan, P.P., Ortiz-Cayon, R., Kalantari, N.K., Ramamoorthi, R., Ng, R., Kar, A. Local light field fusion: Practical view synthesis with prescriptive sampling guidelines. ACM Trans. Graph. (SIGGRAPH) (2019).
9.
Mildenhall, B., Srinivasan, P.P, Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R. NeRF: Representing scenes as neural radiance fields for view synthesis. In ECCV (2020).
10.
Niemeyer, M., Mescheder, L., Oechsle, M., Geiger, A. Differentiable volumetric rendering: Learning implicit 3D representations without 3D supervision. In CVPR (2019).
11.
Park, J.J., Florence, P., Straub, J., Newcombe, R., Lovegrove, S. DeepSDF: Learning continuous signed distance functions for shape representation. In CVPR (2019).
12.
Porter, T., Duff, T. Compositing digital images. Comput. Graph. (SIGGRAPH) (1984).
13.
Rahaman, N., Baratin, A., Arpit, D., Dräxler, F., Lin, M., Hamprecht, F.A., Bengio, Y., Courville, A.C. On the spectral bias of neural networks. In ICML (2018).
14.
Schönberger, J.L., Frahm, J.-M. Structure-from-motion revisited. In CVPR (2016).
15.
Seitz, S.M., Dyer, C.R. Photorealistic scene reconstruction by voxel coloring. Int. J. Comput. Vision (1999).
16.
Sitzmann, V., Thies, J., Heide, F., Nießner, M., Wetzstein, G., Zollhöfer, M. Deepvoxels: Learning persistent 3D feature embeddings. In CVPR (2019).
17.
Sitzmann, V., Zollhoefer, M., Wetzstein, G. Scene representation networks: Continuous 3D-structure- aware neural scene representations. In NeurIPS (2019).
18.
Tancik, M., Srinivasan, P.P., Mildenhall, B., Fridovich-Keil, S., Raghavan, N., Singhal, U., Ramamoorthi, R., Barron, J.T., Ng, R. Fourier features let networks learn high frequency functions in low dimensional domains. In NeurIPS (2020).
19.
Wood, D.N., Azuma, D.I., Aldinger, K., Curless, B., Duchamp, T., Salesin, D.H., Stuetzle, W. Surface light fields for 3D photography. In SIGGRAPH (2000).
20.
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, 0. 딥 피처가 지각적 척도로서 비정상적으로 효과적인 이유. CVPR (2018)에서 발표.
Ben Mildenhall ([bmild]@cs.berkeley. edu), UC Berkeley, Berkeley, CA, USA
1.
Zhou, T., Tucker, R., Flynn, J., Fyffe, G., Snavely, N. 스테레오 확대: 멀티플레인 이미지를 사용한 뷰 합성 학습. ACM Trans. Graph. (SIGGRAPH) (2018).
Pratul P. Srinivasan, Matthew Tancik, 그리고 Ren Ng (pratul, tancik, @berkeley.edu), UC Berkeley, Berkeley, CA, USA.
Jonathan T. Barron ({barron}@google. com), Google Research Mountain View, CA, USA.
Ravi Ramamoorthi ({ravir}@cs.ucsd.edu), UC San Diego, La Jolla, CA, USA.
Ben Mildenhall, Pratul P. Srinivasan, 그리고 Matthew Tancik은 이 연구에 동등하게 기여했어요.
Copyright held by authors/owners.
ACM Student Research Competition
Attention: Undergraduate and Graduate Computing Students
STUDENT RESEARCH COMPETITION
Association for Computing Machinery Advancing Computing as a Science & Profession
ACM 학생 연구 경연대회(SRC)는 학부 및 대학원생들이 잘 알려진 ACM 후원 및 공동 후원 학회에서 심사위원과 참석자들 앞에서 자신의 독창적인 연구를 발표할 수 있는 독특한 장을 제공해요. SRC는 국제적으로 인정받는 장소로, 학부 및 대학원생들이 참여를 통해 많은 유형적, 무형적 보상을 얻을 수 있게 해준답니다.
상: 현금 상금, 메달, 그리고 ACM 학생 회원권
명예: 그랜드 파이널리스트와 그들의 지도교수는 연례 ACM 시상식에 초대되어 그들의 업적을 인정받아요.
가시성: 관심 분야의 연구자들과 만날 기회가 주어지고 중요한 인맥을 쌓을 수 있어요.
경험: SRC 경험을 준비하면서 의사소통, 시각적 표현, 조직, 발표 능력을 향상시킬 기회가 주어져요.
Learn more about ACM Student Research Competitions: https://src.acm.org